HBM 开发路线图揭晓:2038 年将推出 HBM8,具有 16,384 位接口和嵌入式 NAND


韩国顶尖国家级研究机构 KAIST 发布了一份 371 页的论文,详细介绍了到 2038 年高带宽内存(HBM)技术的演进,展示了带宽、容量、I/O 宽度以及热量的增加。该路线图涵盖了从 HBM4 到 HBM8 的发展,包括封装、3D 堆叠、以内存为中心的架构以及嵌入 NAND 存储,甚至基于机器学习的方法来控制功耗。
请记住,该文件是关于 HBM 技术假设演进的,基于当前行业和研究方向,而不是任何商业公司的实际路线图。
(图片来源:KAIST)
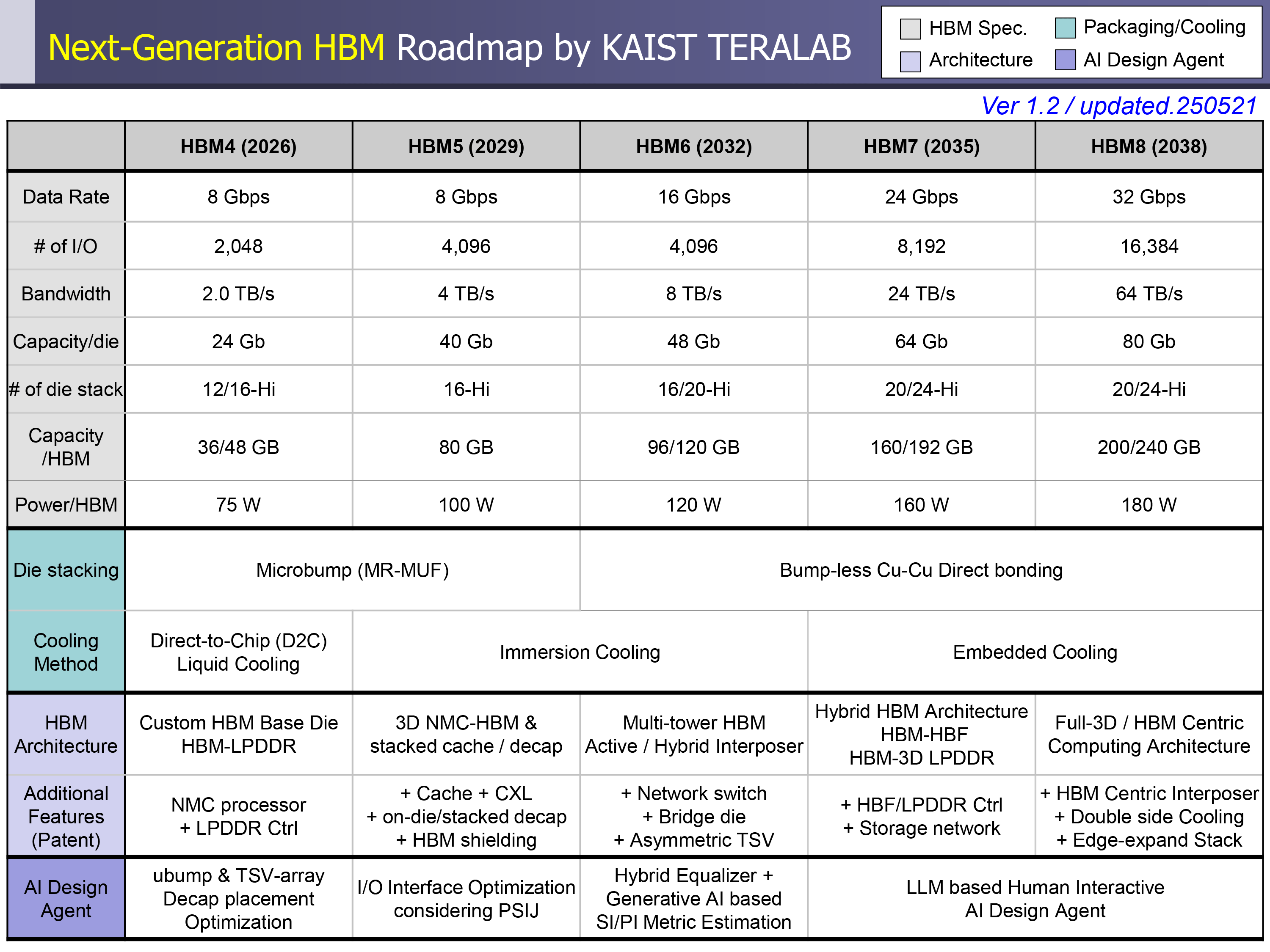
每堆叠的 HBM 容量将从 288GB 增加到 348GB(用于 HBM4),增加到 5,120GB 到 6,144GB(用于 HBM8)。同时,随着性能的提升,功耗也将随之增加,从使用 HBM4 时的每堆叠 75W 增加到使用 HBM8 时的 180W。
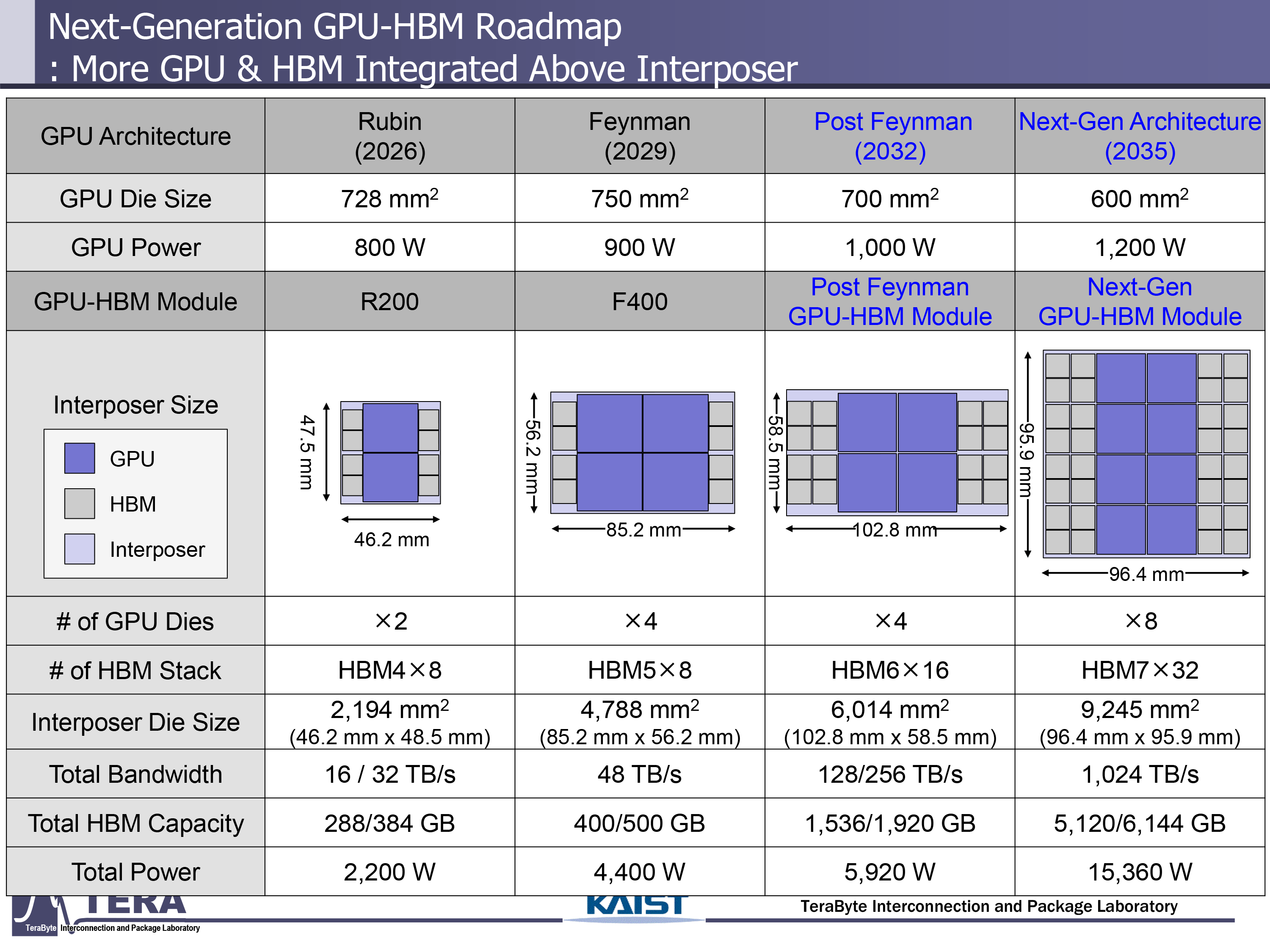
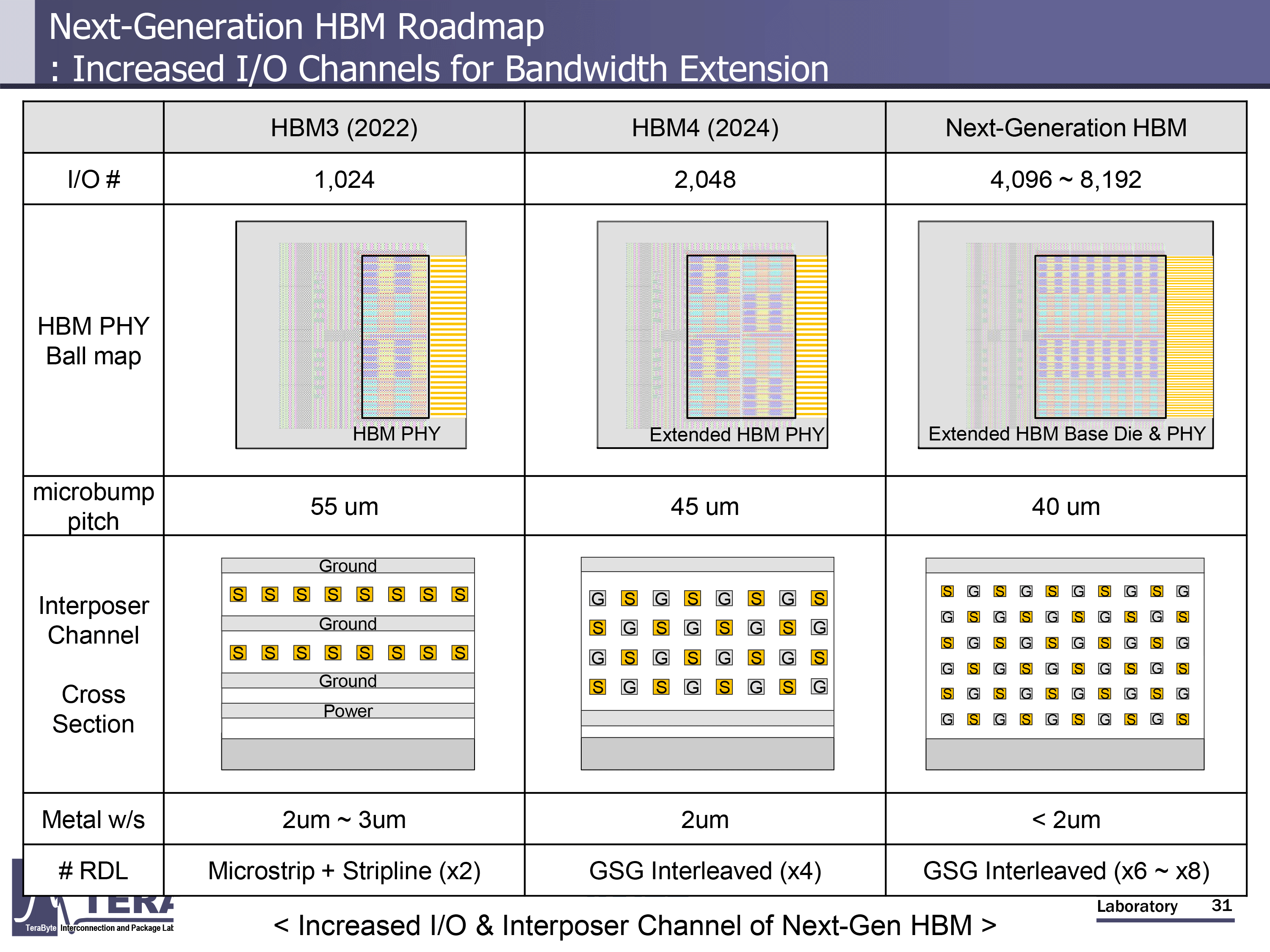
在 2026 年至 2038 年期间,内存带宽预计将从 2TB/s 增长到 64TB/s,数据传输速率预计将从 8GT/s 增长到 32GT/s。每个 HBM 封装的 I/O 宽度也将从目前的 HBM3E 的 1,024 位接口增加到 HBM4 的 2,048 位,然后一直增加到 HBM4 的 16,384 位。
(图片来源:KAIST)
我们已经对 HBM4 了如指掌,并且知道 HBM4E 将向基础芯片添加可定制性 ,以使 HBM4E 更适合特定应用(人工智能、高性能计算、网络等)。
预计这些功能将保留在 HBM5 中,HBM5 还将部署堆叠去耦电容器和 3D 缓存。随着新的内存标准的到来,性能将得到提升,因此预计在 2029 年推出的 HBM5 将保持 HBM4 的数据传输速率,但预计将 I/O 数量增加到 4,096,从而将带宽提高到 4 TB/s,并将每堆栈容量提高到 80 GB。
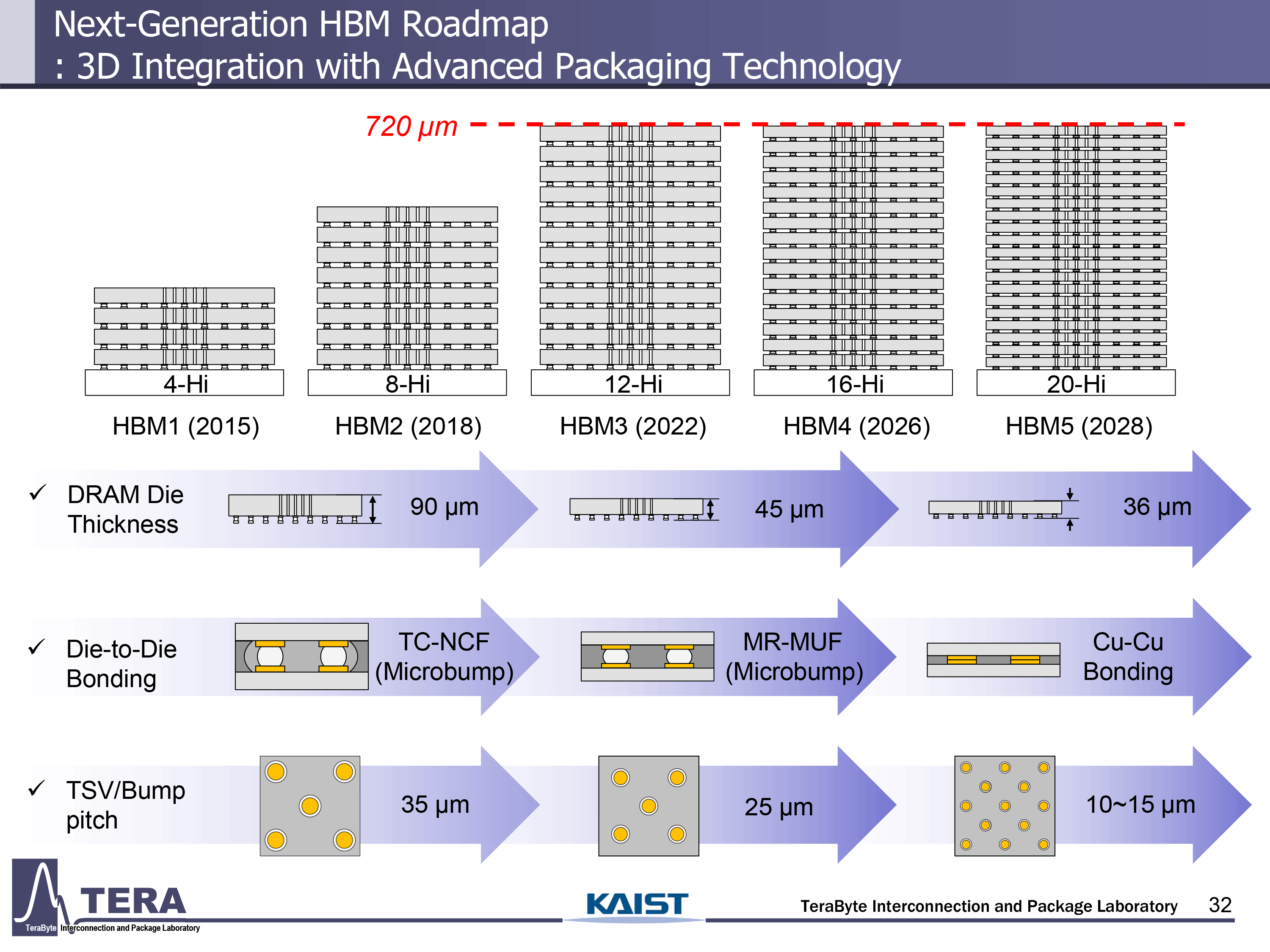
每堆栈功耗预计将增长到 100 W,这将需要更先进的冷却方法。有趣的是,KAIST 预计 HBM5 将继续使用微凸点技术(MR-MUF),尽管据报道行业已经开始考虑直接键合 与 HBM4。此外,HBM5 还将将在基础芯片上集成 L3 缓存、LPDDR 和 CXL 接口,以及热监控。KAIST 还预计人工智能工具将从优化物理布局和减少抖动等方面开始发挥作用,与 HBM5 代产品。
(图片来源:KAIST)
HBM6 预计将在 2032 年接替,将传输速度提高到 16 GT/s,每堆栈带宽提高到 8 TB/s。每堆栈的容量预计将达到 120 GB,功率上升到 120W。KAIST 的研究人员认为,HBM6 将采用无凸点的直接键合,以及结合硅和玻璃的混合中间层。架构变化包括多塔内存堆栈、内部网络交换和广泛的硅通孔(TSV)分布。AI 设计工具扩展范围,结合用于信号和电源建模的生成方法。
保持技术前沿:订阅 Tom's Hardware Newsletter
直接接收 Tom's Hardware 的最佳新闻和深入评测。
通过其他 Future 品牌与我联系,获取新闻和优惠信息接收我们代表我们信任的合作伙伴或赞助商发送的电子邮件
HBM7 和 HBM8 将更进一步,HBM8 将达到每堆栈 32 GT/s 和 64 TB/s。容量预计将扩展到 240 GB。封装预计将采用全 3D 堆叠和双面转换器,并带有嵌入式流体通道。
虽然 HBM7 和 HBM8 在形式上仍将属于高带宽内存解决方案系列,但它们的架构预计将与我们现在所知的 HBM 有巨大差异。HBM5 将增加 L3 缓存和用于 LPDDR 内存的接口,但这些代预计将集成 NAND 接口,从而实现从存储到 HBM 的数据传输,而无需 CPU、GPU 或 ASIC 的过多参与。但这将以功耗为代价,预计每堆栈功耗为 180W。据 KAIST 称,AI 代理将管理热能、功耗和信号路径的实时协同优化。
(图片来源:KAIST)
请记住,KAIST 是一个研究机构,而不是一个有实际路线图的公司,因此它几乎无法根据今天所掌握的创新知识来模拟可能发生的事情。半导体行业中有其他值得尊敬的研究机构,包括比利时的 Imec、法国的 CEA-Leti、德国的 Fraunhofer 和美国的 MIT,仅举几例。这些机构就半导体工艺节点、芯片材料和其他相关主题发布了类似的预测。一些预测在今天看来可能不切实际,但行业往往会以意想不到的方式生产产品,因此许多预测成真,有时甚至被实际制造商,如英特尔或台积电,超越。







评论