利用FinFET优势的六种方式

台积电已经发布了其重要的第四代16nm FinFET 工艺制程,16FFC(16nm FinFET Compact), 并进入量产阶段。 为了能够充分发挥好工艺制程的功耗,性能和面积(PPA)上的优势, 必须要求我们的设计人员将有相关工艺知识的设计战略和优化的IP相结合,其中包括了标准元件库和嵌入式存储器。在这有六种方式去实现它。
本文引用地址:https://www.eepw.com.cn/article/201808/384954.htm(1) 利用制程缩小的优势
16FFC 工艺制程拥有更小的晶体管间距(Poly 到Poly 间距)、更小的金属线间距(线到线、VIA到线和VIA到VIA)用来走线和更小的存储器单元, 相比于台积电28nm制程,16FFC 工艺已经超越了摩尔定律对于面积和性能在工艺节点上的缩小。FinFET 制程同时也能产生更高的单位面积的饱和电流来促进更小尺寸的逻辑单元达到更好的性能。IP设计人员可以利用这些缩小的工艺尺寸和改进的晶体管性能去构建更小/更快的逻辑单元和存储器。SoC 模块设计人员能够利用这些优势去快速地收敛关键路劲上的时序,但是我们也必须意识到这些细小的,高阻抗的线所带来的更高的线延迟还有复杂的信号电源网络所产生的电迁移顾虑。
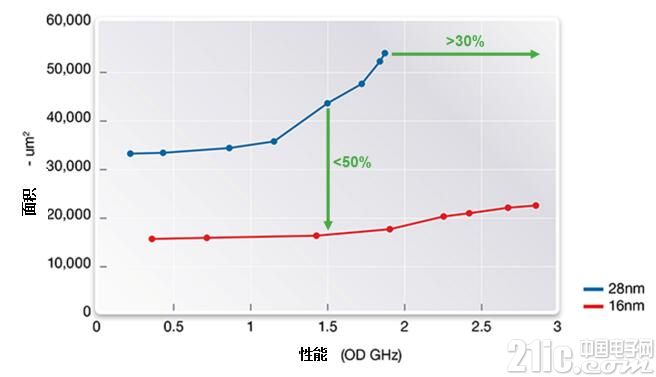
图1所示,使用正确的IP,16FFC的设计可以超越摩尔定律的缩小规则,其面积可达到相同设计在28nm制程上的一半,而性能更快30%以上。
(2) 栅极漏电的降低与动态功耗的增加之间的平衡
16FFC制程可以提供宽泛的阈值电压(VT)和沟道长度的选择来满足于各种各样对于性能和漏电流权衡的情况。图2罗列了逻辑单元的性能相对于漏电流的分布(在对数尺度上),以此来说明用相同的逻辑单元和不同的VT、沟道长度来实现性能和功耗的权衡。
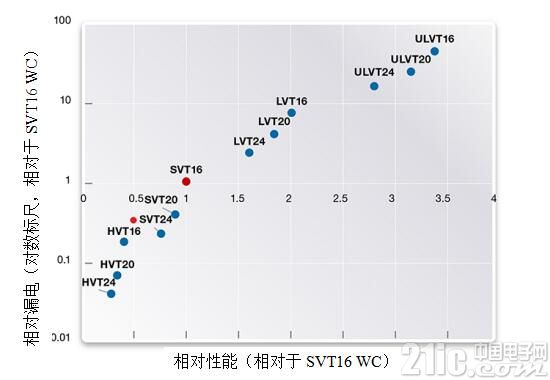
图2: 相对性能与相对漏电流对应每个VT和沟道长度, 7.5 track (T) 超高密度逻辑单元库(来源:Synopsys)
很多移动和物联网设备绝大部分的时间是处在待机或者休眠状态,此时唯一的功耗就是漏电。FinFET的Ion/Ioff比值更高是由于其竖直的鳍式结构。与传统的平面型器件相比,FinFET还能在更低电压下运行,来进一步减少漏电。
总的功耗是动态功耗和静态漏电之和。FinFET拥有更低的漏电流相比于平面型节点工艺,但是它也消耗更高的动态功耗,其原因在于Fin式结构而增加的输入电容和更高的饱和电流。
这种对于相对静态漏电和动态功耗之间的变化要求我们也需要有不同于28nm的设计方案。 图3显示了从180nm到16nm,漏电功耗占SoC总功耗的百分比。它表明了利用FinFET工艺设计的工作相对于平面型工艺来说,并不需要太多考虑漏电流的减少,而在于更多努力来控制动态功耗。
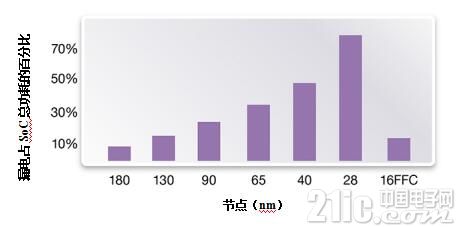
图3:从180nm到16nm,漏电功耗占SoC总功耗的百分比(来源:Synopsys)
(3) 管理动态功耗
设计人员可以通过时钟门翻转频率的管理,降低电容和最小化操作电压来控制动态功耗。 通过优化的版图和更短的走线来降低线电容。输入电容的最小化可以通过利用给定的功能和频率来选取最优化高度的设计单元库来实现。标准设计单元能够被构建在不同的高度下(整数倍的N、P fins)来满足于不同模块对于性能和可靠性的频率要求。例如, 图4显示了1X驱动能力的反相器在3个不同轨道高度上的输入电容 (7.5T, 9T, 10.5T)
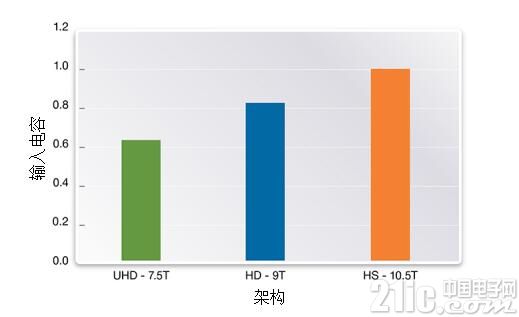
图4:1X 驱动反相器的输入电容(来源:Synopsys)
根据模块的功能和频率,如果用超高密度的7.5T设计单元库来实现,在性能上相比于用高密度9T单元库来说没有那么好,但是由于器件电容的减少,功耗也会降低25%。
动态功耗同样可以通过V^2这个系数用更低的操作电压来降低,如图5所示,模块之间在不同操作电压下的漏电功耗(虚线)和动态功耗(实线)。
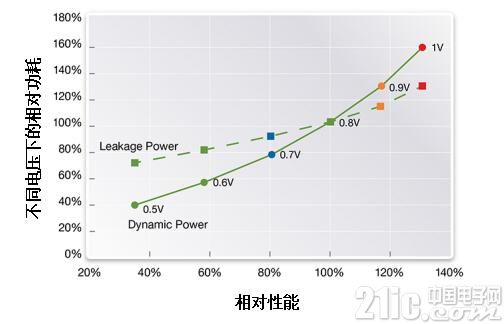
图5:多个标准电压下性能与漏电和动态功耗的比较(来源:Synopsys)
(4) 优化逻辑库设计
充分利用台积电16FFC制程的一个重要途径是确保您使用的逻辑库是经过最大绕线密度的优化。在这有多种方法可以去实线。
(4a) 减少面积和总功耗的高效版图
充分利用先进工艺的制程是至关重要的,比如利用在扩散区边缘可连续的多晶硅特性要比传统的单晶硅更小5%的绕线面积。
(4b) 组合单元
优化寄存器到寄存器路径需要一套丰富的标准单元库,其包含了各种特定功能,驱动能力和实现功能的单元。这些功能单元是综合创建高效电路所必不可少的。优化的版图技术是要求充分利用最先进的布线算法,最大化pin口的访问和减少或者消除布局拥堵。先进的综合和布局布线工具能够发挥出一套拥有丰富驱动能力选择的单元库的优势,来处理拓扑逻辑设计和物理实际差距之间单元不同的的扇形输出和负载。
(4c) 时序单元
人们有时将触发器的设置和延迟时间称为停滞时间。它会消耗掉每个时钟周期里面处理实际计算工作的有效时间。
(5) 巧妙地运用不同的触发器
我们可以通过运用多组高性能触发器来减少停滞时间。 延迟优化的触发器(多重延迟触发器)能够快速地向关键路径逻辑集群发送信号。设置时序优化的触发器(多重设置时序触发器)可作为捕获寄存器,来延长多重增量中可用的时钟周期。综合布局布线优化工具能够被约束去使用这些多重设置和延迟触发器来实现更多15-20%的性能提升。
(6) 存储器编译器设计
DesignWare 储存器编译器拥有先进的功耗管理功能,能够提供轻度睡眠模式,深度睡眠模式,断电模糊和双电源供电模式,以及读写辅助电路功能。同时还可以搭配DesignWare STAR Memory System ,来提供一套完整的嵌入式存储器测试方案,完成从侦测到修复制造过程中的失效。
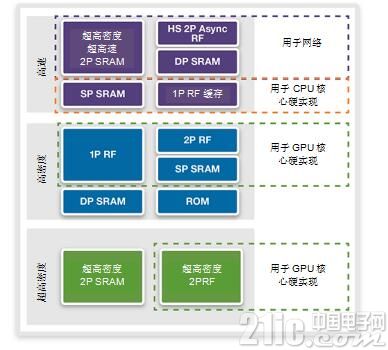
图6:适用于各种应用环境下的DesignWare Memory Compilers(来源:Synopsys)
总结
台积电的16FFC工艺制程已经改进了面积的工艺设计规则,晶体管的性能和功耗比以及缩小了工艺偏差,使得我们可以用更小的设计规模来实现更高的性能,同时功耗也更低。为了能够充分利用好先进工艺的优势,设计者需要能够获取优化的IP模块,逻辑单元库和存储器编译器,同时能运用好综合布局布线工具来达到他们的最佳效果。



评论