技术革命!主流芯片架构正在发生重大变化?

主流的芯片制造商和系统供应商都在改变方向,引发了一场架构创新大赛,创新涉及从存储器中读取和写入数据的方式、数据管理和处理方式以及单个芯片上的各个元素的结合方式等。虽然工艺节点尺寸仍在继续缩减,但是没有人寄希望于工艺的进步可以跟得上传感器数据的爆炸性增长以及芯片间数据流量增加的步伐。

在这些创新中, 新型处理器架构专注于研究每个时钟周期内处理更多数据的方法,有时牺牲部分精度,或者根据应用类型提高特定操作的优先级;
正在开发的新存储器架构改变了数据存储、读取、写入和访问的方式;
更有针对性的处理元素散布在系统周围,更加靠近内存。系统不再依赖于最适合应用的单个主处理器,而是根据数据类型和应用选择不同的加速器;
通过人工智能技术,将不同的数据类型融合在一起,形成多种模式,有效地提高了数据密度,同时最大限度地减少不同数据类型之间的差异;
封装组合形式成为架构设计的核心之一,越来越关注修改设计的难易。
“有一些趋势导致人们试图充分挖掘已有方案的潜力。” Rambus的杰出发明家Steven Woo说,“在数据中心上,你希望硬件和软件能够发挥尽可能多的作用,这是数据中心重新思考其经济成本的方式。启用一种新功能的成本非常高,但是瓶颈正在日益凸显,所以我们看到更多专用芯片和提高计算效率的方法不断涌现,如果可以减少数据在内存和I/O上来回传输的次数,将会产生很大的影响。”
这些变化在边缘节点上更加明显,此外,系统供应商突然意识到有数百亿台设备不断地产生天量数据,而这些数据无法全部发送到云端进行处理。在边缘节点上处理这些数据对节点自身带来了挑战,它们需要在不显著改变功耗预算的情况下大幅提高性能。
英伟达的Tesla产品家族首席平台架构师Robert Ober说:“人们把重点放在降低精度上,边缘节点性能的提升不仅仅体现在更多计算周期上。它需要在内存中放入更多数据,比如您可以使用16位指令格式。 所以,解决方案不是为了提高处理效率而在缓存中存储更多内容。从统计上看,不同精度的计算结果应该是一致的。”
Ober预测,在可预见的未来,通过一系列架构优化应该可以每隔几年就将处理速度提高一倍。“我们将见证这些改变,”他说。“为了实现这一目标,我们需要在三个层面实现突破。第一是计算,第二是内存,在某些模型中,计算更关键,而在其它模型中内存更关键。第三是主处理器带宽和I/O带宽,我们需要在优化存储和网络方面做很多工作。”
其中一些变化已经发生。在Hot Chips 2018会议上的演讲中,三星奥斯汀研发部门的首席架构师 Jeff Rupley指出了该公司M3处理器的几个主要架构变化。其中一个是每个周期处理更多的指令,相比于之前M2处理的四条指令/周期,M3为6条。还包括以若干神经网络取代预取搜索,改善了分支预测,以及将指令队列深度加倍。
从另一个角度来看,这些变化也改变了从制造工艺到前端架构/设计和后端封装的协同创新关系。虽然制造工艺仍在不断创新,但是每次新节点只能带来15%到20%的性能和功耗改善,显然不足以跟上数据的增长步伐。
“变化正以指数速度发生,”Xilinx总裁兼首席执行官Victor Peng在Hot Chips的演讲中表示。 “现在每年将产生10个zettabytes [1021字节]的数据,其中大部分是非结构化数据。”
存储器领域的新方案
处理这么多数据需要重新思考系统中的每个元素,从数据的处理方式到存储方式都需要重新设计。
“业界已经进行了多次尝试,以创建新的内存架构,”eSilicon EMEA创新高级主管CarlosMaciàn说。“当前内存的瓶颈在于你需要读取出一整行,然后再在其中选择一位。一种新方法是构建可以从左到右、从上到下读取的内存。您还可以更进一步,将计算能力部署到不同的内存中。”
还可以改变内存的读取方式、处理单元的位置和类型,以及使用人工智能技术优化不同数据在整个系统中存储、处理、传输的优先级。
“在稀疏数据中,我们一次只能从字节阵列读取一个字节的数据,在其它类型应用中,也可以在同样的字节阵列中一次读取八个连续数据,而不会消耗与我们不感兴趣的其它字节或字节阵列相关的能耗,”Cadence产品营销部门总监Marc Greenberg说。 “未来的新型内存可能更适合处理这类事情。比如我们看一下HBM2的架构,HBM2硅片堆栈被安排到16个64位的虚拟通道中,我们从任何一次对任何虚拟通道的访问中都能得到4个连续的64位字。因此,有可能构建可水平写入的1,024位宽的数据阵列,一次只读取4个64位字。”
内存是冯诺依曼架构的核心组件之一,也正在成为架构创新的最大试验田之一。AMD的客户端产品首席架构师Dan Bouvier表示:“现有架构的一个大报应就是虚拟内存系统,它迫使你以更加不自然的方式移动数据。你需要执行一次又一次转换。如果您可以消除DRAM中的分区冲突,您可以获得更高效的数据流动。分立GPU可以在90%的效率区间运行DRAM,效率非常高。但是,如果你可以获得串行的数据传输,你也可以在APU和CPU上在80%到85%的效率区间内运行DRAM。”
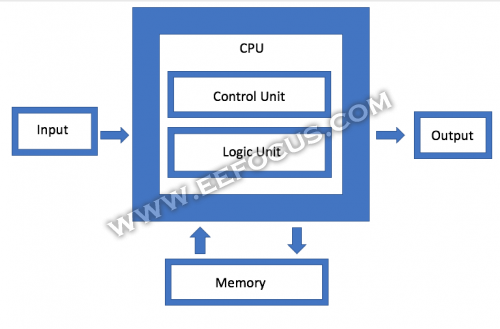
冯诺依曼架构
IBM正在开发一种不同类型的内存架构,它本质上是磁盘条带化技术的现代版本。磁盘条带化技术将数据不再局限在单个磁盘上,同样,IBM新型内存架构的目标是利用被其系统硬件架构师Jeff Stuecheli称为连接技术的“瑞士军刀”的连接器技术,混合和匹配不同类型的数据。
“CPU变成了一个位于高性能信号接口中间的东西,”Stuecheli说。“如果你修改微体系结构,不用提高频率,内核就可以在每个周期内做更多的事情。”
为了确保这些体系架构能够处理越来越庞大的数据,连接性和吞吐能力变得越来越重要。 “现在最大的瓶颈在于数据传输,”Rambus的Woo说。 “半导体行业在提高计算性能方面做得非常出色。 但是,如果您把大量时间用在等待数据或特定的数据模式上,效率依然无法提高。必须更快地运行内存。因此,如果你看看DRAM和非易失性存储器就会发现,它们的性能实际上取决于数据传输模式。如果您能够将数据串起来,就可以在内存中获得非常高的效率。但是如果你的数据在空间上随机分布,效率就会降低。无论你怎么做,随着数据量的增加,你必须保证能够更快地完成所有这些数据传输。”











评论