片上多核处理器共享资源分配与调度策略研究综述(二)

该项研究首先对系统的公平性给出一个理想化的定义如下:
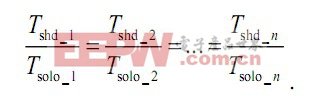
Tsolo_i 表示线程i 独占全部共享资源时所需的执行时间;Tshd_i 表示多个线程并行运行时执行线程i所需的时间;当所有线程在并行环境下的执行时间按相等比例增长时,则认为系统是绝对公平的。存在如下表达式:
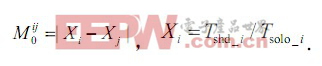
Xi 表示线程i 在与其他线程协同运行时相对于它独自运行时的减速比(slowdown); 0ij M 表示系统中任意两个线程间减速比之差。0ij M 越小,表示两个线程性能所受到的影响程度越相近。因此,一个追求公平性的缓存分区策略,应该使得0ij M 之和最小化,则系统的公平性程度最高。
在实际并行系统中,Tshd_i 信息易于获取,但是Tsolo_i 的相关信息很难取得。因此,需要寻找可以替代执行时间T 同时又易于获取的指标。
Kim 等人在文献中另外提出了5 项可用的指标来衡量系统公平性。需要用到的信息包括各线程独享缓存时产生的缓存失效数Missessolo 和缓存失效率MissRatesolo,以及多个线程并行运行时的缓存失效率Missesshd 和缓存失效率MissRateshd.对于任意一对线程i 和j,5 项指标分别如下:

这里提出的几个指标都具有较为直观的意义:
M1 用于平衡各线程缓存失效数增加的比例,M2 则是平衡各线程的缓存失效数;类似的,M3 用于平衡各线程缓存失效率增加的比例,M4 平衡各线程的缓存失效率;而M5 则用于平衡各线程由于协同运行增加的缓存失效率。
在确定了系统公平性的衡量指标后,需要制定相应的缓存分区算法, 通过最小化表达式表达式1
的值来最大化系统公平性程度。文献中提出的缓存分区算法由3 部分操作组成:初始化( initialization ), 回滚( rollback ) 和重分区(reparationing)。
初始化操作,将共享缓存平均分配给各个线程,

回滚操作,每一个时间段t 结束时:
1)将可能需要重分配的线程初始化为待调整线程集CS={1,2,…,n}.
2)对于每个线程i 检测其是否在刚刚结束的时间段t 中通过重分区操作获取了更多的缓存分区Aij(Aij 表示线程i 通过重分区操作从线程j 得到的缓存空间),用集合AS 来记录所有时间段t 中进行的缓存重分配,如果时间段t 的分区策略没有取得预期效果,即:

则进行回滚操作,返回重分区之前的状态并且将线程i,j 从待调整线程集CS 中剔除:
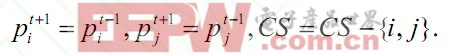
重分区操作,在每个时间段t 结束并且回滚操作完成之后进行:
1)初始化重分配集AS={};
2)对于每个线程i∈CS,按照选定的衡量指标计算其公平性ti X ;
3)根据ti X 值排序,分别找出imax∈CS 以及imin∈CS;
4)若max_i min_i repartition X ? X ?T,则进行重分区:

这个缓存分区算法本质上是用性能受影响最小线程的部分缓存空间来补偿性能受影响最大的线程,从而提高系统公平性;回滚操作可以避免将缓存分配给收益很小的线程,从而提高了缓存利用率。
实验结果还表明,采用不同的公平性衡量指标制定的分区策略所取得的效果是不一样的,其中采用M1取得的效果最佳,其次为M3,效果最差的则是M2.
上述方案是通过底层硬件来实现系统公平性。
之后Rafique 在文献中还从操作系统层面实现了上述缓存分区策略,并以M4 为衡量标准,取得类似的优化效果。
另外,对于前面提到的Tsolo_i 信息难以获取的问题,我们可以通过增加一组计数器,来记录每个线程由于其共享缓存中的数据被其他线程替换掉而产生的额外延迟Tdelay_i,用Tshd_i 减去Tdelay_i 则可以求出Tsolo_i,从而能够更准确地衡量公平性。
1.3.4 细粒度缓存分区
前面介绍的缓存分区分区策略,普遍存在的一个问题是缓存分区粒度较大。缓存的路数与其关联度(associativity)相关。通过增加缓存路数能够有效提高缓存关联度,从而降低冲突带来的缓存失效,但同时也会增加命中延迟和功耗。因此,缓存设计需要对各类代价进行折衷考虑,能够维护的缓存路数总是一定的,不能随意增加。在线程较少而缓存路数较多时,按路分区可以近似取得理想的分区效果;随着线程数的增多,每个线程的平均可用缓存路数大大减少,按路分区的方式则不再可取。
缓存分区粒度过大还不可避免地会带来缓存空间的浪费。例如一个线程分配到四路缓存,但是其中可能有一部分缓存空间的复用率很低或者根本就没用到,则该线程分到的缓存空间存在冗余,得不到充分利用;与此同时,另一些线程的缓存需求可能无法得到满足,却无法使用其他线程的冗余缓存空间。
Xie 等人在文献[10]中提出一种新的缓存管理策略称为提升/ 插入伪分区策略(promotion/insertion pseudo-partitioning ,PIPP)。PIPP 结合UCP 的缓存分区策略思想,区别在于对缓存并不进行明确的严格分区,而是通过管理缓存的替换优先级和插入策略来达到与缓存分区类似的效果。插入策略根据确定好的替换优先级选择应该被逐出的缓存行;提升策略根据缓存命中情况更改缓存的替换优先级。给缓存行设定不同替换优先级实现类似缓存分区的效果。PIPP 没有实际对缓存进行分区,因而,制定好分区策略后,线程在需要的时候仍然可以借用其他线程的冗余缓存空间。PIPP 允许从其他线程借用缓存空间在避免缓存空间浪费,提高缓存利用率的同时,却难以防止某些侵略性较强的线程可能过多占用其他线程缓存空间,导致这些线程的性能受到严重影响的隐患。另外,PIPP 是针对UCP 策略的缓存分区粒度过大而提出的,对于其他的调度策略可能并不适用,可扩展性较差。






评论