片上多核处理器共享资源分配与调度策略研究综述(二)
通过对程序的访存特征进行研究并分类,解释不同的程序从缓存分区的获益状况,可以帮助制定有效的缓存分区策略。但是,UCP 中提出的分类方式更多地是对于一个线程收益曲线的直观判断,并没有提出一个形式化的算法来对程序进行准确归类。因而,很难在硬件上实现基于该分类准则对程序的归类。另外,UCP 通过在每个核的UMON 中增加ATD,以获取更为准确的访存信息,但是带来了较大的硬件开销。可以通过抽样调查线程在部分缓存中的访存行为近似估计其全局效果,例如在每个UMON 中的ATD 只保留共享缓存的奇数组(set)的标签目录,从而可以把硬件开销减半。
类似地,Lin 等人在文献中从OS 层面通过页染色对程序进行分类。在该研究中,将一个程序分别单独运行在配置为1MB 和4MB 的共享缓存系统中,并观察其运行在1MB 配置下相对于运行于4MB缓存配置时的性能降低程度,然后按其性能降低程度对程序分为4 种 以颜色命名的类。然而,因其需要将程序单独在不同缓存配置下运行多次,来得出相关分类信息,这种分类方式也很难实际用于动态缓存分区。
Xie 等人在文献中提出了一种动物分类法(animal_based taxonomy)。借助UCP 中提出的UMON 获取访存信息,按照程序的访存行为特征对线程分类,并根据分类结果制定相应缓存分区策略。
动物分类法将线程的访存行为特征与几种动物性格相对应,具体如下:
Turtles,对应于对共享缓存空间需求很低的线程;Sheep,对应只需要分配给很少的共享缓存即可达到较低的缓存失效率的线程,这类线程对于可用缓存空间大小不敏感;Rabbit,这类线程对可用的缓存空间大小敏感,但是只要分配了充足的缓存空间就可以达到较低缓存失效率;Devil,这类线程频繁发出对共享缓存的访存请求,但是无论占用多少可用缓存空间,总是会产生大量缓存失效。这类线程难以从分配到的更多缓存空间获得明显收益,并且侵略性很强,对于并行运行的其他线程有着消极影响。
动物分类法中用于对线程进行分类的指标包括:Access,一个线程对于共享缓存总的访存次数;Missessolo,一个线程独享全部共享缓存时产生的缓存失效数;MissRatesolo=Missessolo/Access,缓存失效率;WayNeededk,其中k 为一个百分数,该式表示至少需要多少路缓存才可以达到该线程独享缓存时性能的相应百分比。以上信息都可以通过UMON 获得。
针对UCP 中没有提出一个形式化的算法来对线程进行分类的缺点,文献中给出了一个具体的算法:
If (Access1000)
Animal:=Turtle;
Else if ((MissRatesolo>10%)OR (Missessolo>4000))
Animal:=Devil;
Else if (WayNeeded95%>N/2)
Animal:=Rabbit;
Else
Animal:=Sheep.
线程只产生很少的访存请求( 例如,Access1000),将其归类为Turtle 类;若线程即使占有全部缓存空间仍然产生大量缓存失效或者较高的缓存失效率( 例如, (MissRatesolo>10%) OR(Missessolo>4000)),则将其归类为Devil 类;当线程占有一定可用缓存空间时的性能表现即能够接近独占全部缓存空间时的性能时( 例如,WayNeeded95%>N/2),将其归类为Rabbit;否则,线程为Sheep 类。根据具体情况,还可以通过调节分类参数以取得合适的分类效果。
实际上很多情况下,过于具体的分类信息对于缓存分区并无太大帮助。最重要的是要筛选出并行运行线程中侵略性最强的Devil 类线程。因为这类线程会占用大量缓存空间,严重影响其他线程的性能。因此,上述算法也可以简化到只区分Devil 类和非Devil 类线程:
If ((Access>=1000) AND
((MissRatesolo>10%) OR (Missessolo>4000)))
Animal:=Devil;
Else
Animal:=Not_Devil.
当系统中不存在Devil 类线程时,可以认为线程间对共享缓存不会发生激烈争夺,因而直接采用LRU 替换策略;当存在Devil 类线程时,需要限制Devil 类线程对于系统中其他线程的影响,给其划分一块固定的可用缓存空间,其他线程共享剩余缓存。
简化后的算法复杂度和硬件开销都将大大降低,并且在线程较少时能取得较优的效果;当线程数目增多时,这种算法的效果则很难得到保证。
在文献中将线程的缓存失效分为两类:一种称为局部失效(local misses),这类缓存失效只要增加分配一路缓存,即可以变为命中状态;另一种称为全局失效(global misses),这类缓存失效需要增加分配一路以上的缓存才能由失效变为命中。
缓存分区模块监测每个线程的局部与全局失效,从而知道每一个线程的缓存需求。用CL,CL-1 分别统计单个线程在其缓存分区内LRU 和LRU-1 位置的缓存命中数;用一个计数器CG 来确定全局失效数。
将缓存分区策略的分区单位粒度设定为最多2路缓存,则存在-2,-1,0,1,2 路5 种可能的分区单位。当一个线程的缓存减少或增加时,其性能损失或增益情况表示如下:
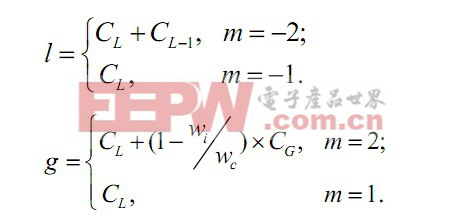
l 为性能损失函数,g 为性能增益函数,wi 和wc分别表示一个线程独占的缓存路数及系统总的缓存路数。
一个缓存分区方案所对应的总的系统性能增益为:

缓存分区策略需要在满足限制条件的前提下最大化G.这种算法是一种穷举的做法,需要列出所有的分区可能性并进行比较,在系统线程数目较少的情况下可以取得很好的效果;随着线程增加将发生状态空间的爆炸。
1.3.3 公平性
系统的性能好坏不止与吞吐量相关,公平性也是一个重要的衡量指标。前述研究的优化目标都主要集中于最大化系统吞吐量而忽略了公平性。这可能导致系统中某些线程的访存请求长时间得不到服务乃至饿死的情况发生,对该线程的性能造成影响,进而也会影响到系统的性能。本节的研究主要着眼于系统的公平性,以达到同时改善所有线程性能的目的。
Kim 等人在文献中从改善系统公平性的角度对缓存分区进行了研究。实验证明,以改善系统公平性为优化目标的缓存分区策略通常可以同时提高系统吞吐量,但是以最大化吞吐量为目标的缓存分区策略则对无法保障公平性。






评论