最小化ARM Cortex-M CPU功耗的方法与技巧

举个例子,即使在广受欢迎的ARM Cortex-M类的MCU中指令缓冲的运行方法也有不同。采用简单指令缓冲的MCU,例如来自Silicon Labs的EFM32产品,可以存储128x32(512 bytes)的目前大多数当前执行指令(通过逻辑判断请求的指令地址是否在缓冲中)。EFM32参考手册指出典型应用在这个缓冲中将有超过70%的命中率,这意味着极少的Flash存取、更快的代码执行速度和更低的整体功耗。相比之下,采用64x128位分支缓冲器的ARM MCU能够存储最初的几条指令(取决于16位或32位指令混合,每个分支最多为8条指令,最少为4条指令)。因此,分支缓冲实现能够在1个时钟周期内为命中缓冲的任何分支或跳转填充流水线,从而消除了任何CPU时钟周期延迟或浪费。两种缓冲技术与同类型没有缓冲特性的CPU相比,都提供了相当大的性能改善和功耗减少。
本文引用地址:https://www.eepw.com.cn/article/273202.htm4 M0+内核探究
对功耗敏感型应用来说每个nano-watt都很重要,Cortex-M0+内核是一个极好的选择。M0+基于Von-Neumann架构(而Cortex-M3和Cortex-M4内核是Harvard结构),这意味着它具有更少的门电路数量实现更低的整体功耗,并且仅仅损失极小的性能(Cortex-M0+的0.93DMIPS/MHz对比Cortex-M3/M4的1.25DMIPS/MHz)。它也使用Thumb-2指令集的更小子集(如图3所示)。几乎所有的指令都有16位的操作码(52x16位操作码和7x32位操作码;数据操作都是32位的),这使得它可以实现一些令人感兴趣的功能选项以降低CPU功耗。

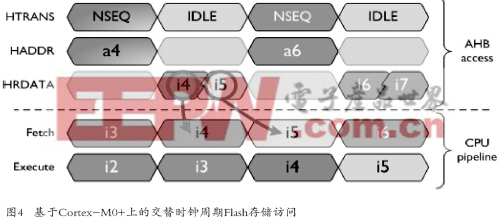
节能性功能选项首要措施就是减少Flash存储访问次数。一个主要的16位指令集意味着你可以交替时钟周期访问Flash存储器(如图4所示),并且可以在每一次Flash存储访问中为流水线获取两条指令。假设你在存储器中有两条指令并对齐成一个32位字;在指令没有对齐的情况下,Cortex-M0+将禁止剩余的一半总线以节省每一点能耗。

存储器相关文章:存储器原理




评论