相较于端到端,VLA给智驾带来了哪些改变?

一直以来,自动驾驶都是智能电动汽车市场竞争最为激烈的战线,发展最为迅速的赛道。万事万物皆有因果,自动驾驶这么火,资本倾情投入,消费者万众瞩目,主要是因为自动驾驶这项产品或服务能够创造巨大的用户价值。
说起来,自动驾驶系统的价值与自动驾驶等级密切相关,但是,在车企们看似无意、实则或许真无意的宣传下,朴素的人民群众往往把辅助驾驶系统当成自动驾驶系统来用,很少去研究不同自动驾驶等级之间的界限,以至于近几年经常出现因误用智驾系统导致的事故。
有的事故像鸿毛一般,消费者在事故之后还能好整以暇地发朋友圈,有的事故人命关天,或许到生命的最后一刻,当事人把那些开车睡觉被象征性罚款的高管骂了100遍才恋恋不舍地离开了人间。没办法,总会有无知的消费者不知道组合辅助驾驶和高等级自动驾驶的区别,不自觉地对它们抱持着同样的期待。
对于车企而言,唯有不断通过技术的进步,尽最大努力提升系统在各种场景下的表现,才不至于被突发的事故影响了销量表现。在卷了一年的端到端之后,各大车企和智驾方案供应商齐刷刷地转向VLA方案,期待着VLA能够实现惊天一跃,帮助系统迈进到真的可以让用户信赖的L3。
在这样的背景下,有必要探讨的是,VLA相较于端到端到底有哪些优点,以至于车企把端到端这个曾经的小甜甜冷落在了一边?以及,各大头部企业的VLA是长着同样的脸盘,还是有着不一样的路线?
VLA与端到端
6月17日,特斯拉自动驾驶前总监Andrej Karpathy在YC AI创业训练营上面发表了主题为《AI时代的软件》的演讲。在2017年提出软件2.0的概念之后,Andrej Karpathy再一次提出了软件3.0的概念,总结了近年来软件形式的重大转变。软件1.0的开发范式是编写代码,主体是code,软件2.0的开发范式是设计专用神经网络,主体是神经网络权重weight,软件3.0的开发范式是给出提示词,主体是作为操作系统的大语言模型及其交互接口。
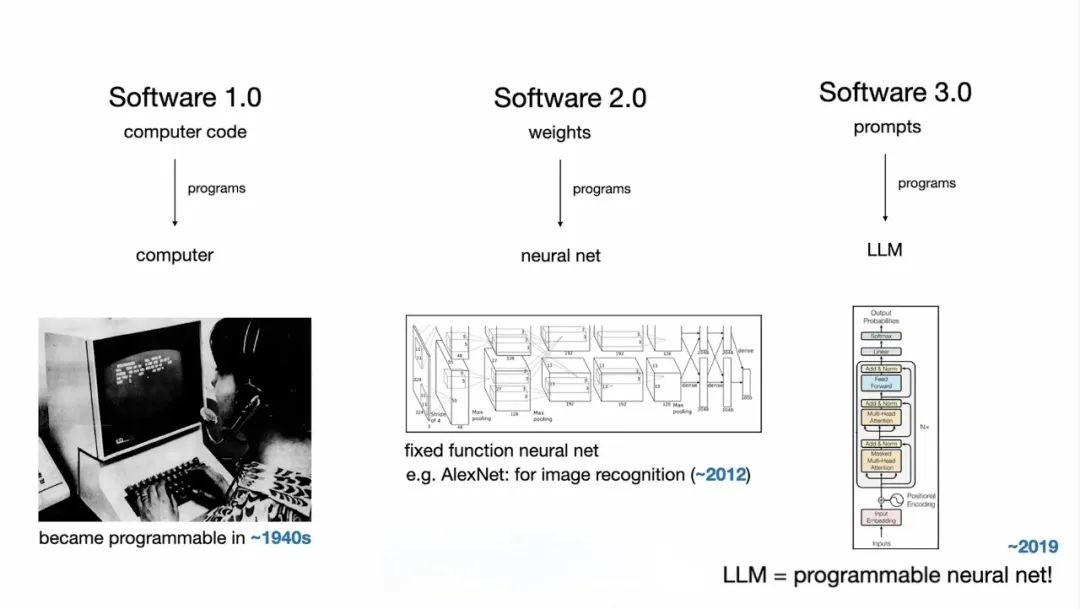
图片来源:Andrej Karpathy
借用这种代际划分来区分VLA和常规的端到端方案,很显然,端到端是软件2.0时代的产物,VLA是软件3.0时代的成果。当然,完全照搬也是不妥,毕竟,Andrej Karpathy的本意是讲软件开发方式上的变革。不过,大语言模型的问世是划分软件2.0时代和软件3.0时代的分界线,同样类比过来,常规的端到端方案是面向自动驾驶的专用小模型,而VLA引入了具备通用能力的大语言模型,核心区别同样在于大语言模型。除了专用和通用的分别,还可以认为传统端到端方案是端到端形式的小模型,而VLA在传统端到端方案的基础上引入了大语言模型LLM之后,成了端到端形式的大模型。
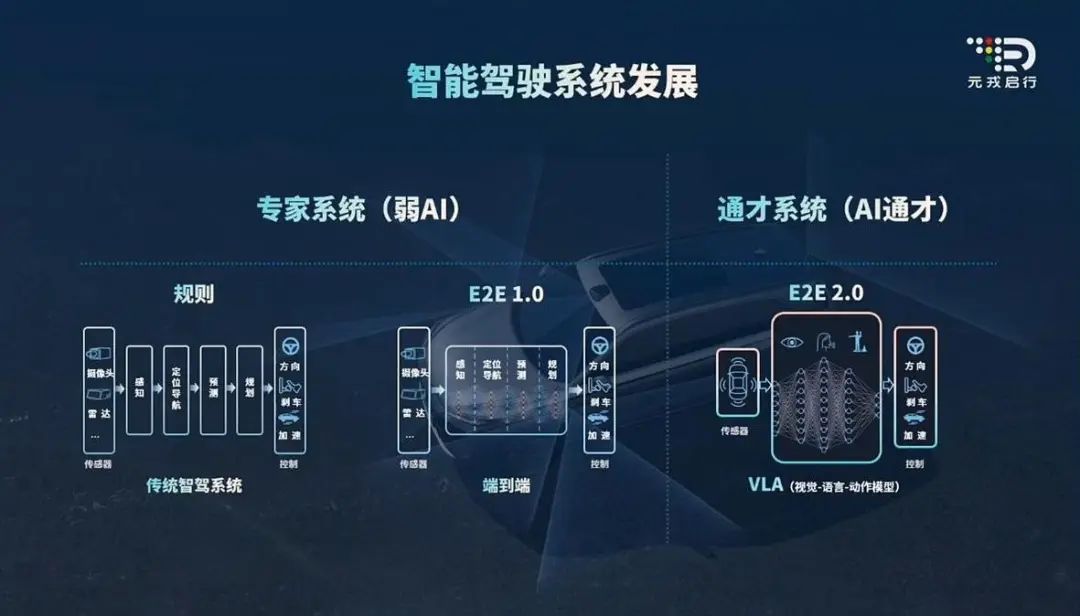
图片来源:元戎启行
和小模型相比,大模型显然更加吻合尺度定律Scaling Law:通过更多训练数据、更大参数规模提升模型的能力。要知道,传统端到端方案的神经网路架构过于简单,在数据训练量突破1000万个Clips之后,性能很难继续同步提升,而VLA引入了大语言模型,通过更大的参数提供了更高的表达自由度,能够在更大规模训练数据的驱动下,构建出可建立更多层次、更长时序、全局性语义特征的模型。引入大语言模型保证继续遵循尺度定律还意味着,在模型架构保持不变的情况下,企业可以实现对未来模型性能的准确预测。对于资源日益捉襟见肘的车企来说,这意味着它在模型上的训练不会白烧钱,当然,这也意味着智驾企业在VLA上的迭代和探索在很长一段时间之内都不会触及天花板。
除了形式和内容上的区别,常规端到端和VLA当然还有在功能作用上的区别。小鹏汽车掌门人何小鹏在G7预售发布会上以大脑和小脑为喻,间接地讲述过传统端到端和VLA的功能作用。大师兄表示,传统端到端方案发挥的是运动小脑的功能,起到的作用是“让汽车会开”,VLA这种进化版端到端方案额外引入了压缩了人类知识的大语言模型,发挥的是思考大脑的功能,起到的作用是“让汽车开好”。

图片来源:小鹏汽车
在这里可以做一个总结了。无论是形式、内容还是功能、作用,常规端到端和VLA的核心区别就在于端到端没有大语言模型,VLA则引入了可以起到决策中枢或大脑作用的大语言模型。
两种VLA路线
说到在传统端到端方案的基础上引入大语言模型,业界之前其实有过另外一种实践,其代表是理想汽车的双系统方案。24年7月份,理想汽车提出了单颗英伟达Orin X运行端到端方案、单颗Orin X运行视觉语言模型的双系统方案,通过VLM主动思考、理解世界的能力,其双系统方案可以识别公交车道、潮汐车道,能够鉴别复杂的交通标识,在一定程度上具备了只有人类大脑才能具备的交通信息阅读理解能力。
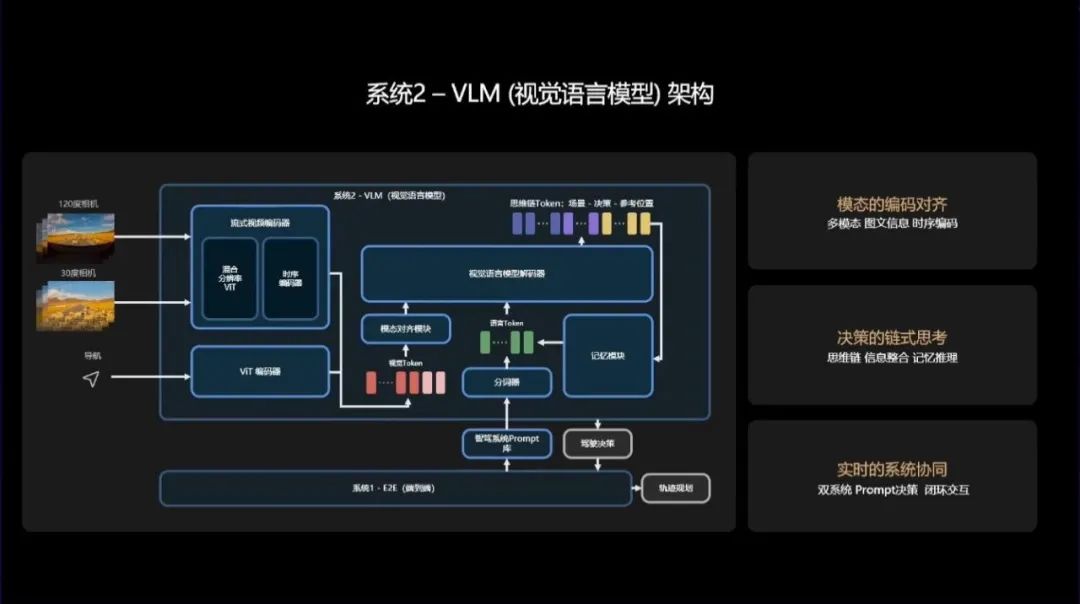 图片来源:理想汽车
图片来源:理想汽车
VLM尽管引入了大语言模型,却并不直接参与轨迹的生成,无法利用车端采集的大量“视觉输入-轨迹输出”数据做训练,再加上VLM不具备3D理解能力,业界纷纷摒弃了这种双系统方案。至于VLA,大路朝天,各走一边,作为本土车企中探索VLA方案的两个先行者,理想汽车和小鹏汽车走出了略微不同的路线。两者的不同主要体现在两个方面。第一,理想汽车先对云端基座大模型做蒸馏,然后再对蒸馏后的端侧模型做强化学习,小鹏汽车则是先对云端基座大模型做强化学习,然后再蒸馏到车端。第二,对于用户语音控车这种复杂任务处理,理想汽车走的是端云结合路线,由云端基座大模型做复杂任务拆解,再将拆解后的简单任务下发到端侧,小鹏汽车则是在座舱部署一个几十B(几百亿)参数的本地大模型,通过中央融合架构,将座舱端拆解的指令下发给智驾系统实现。
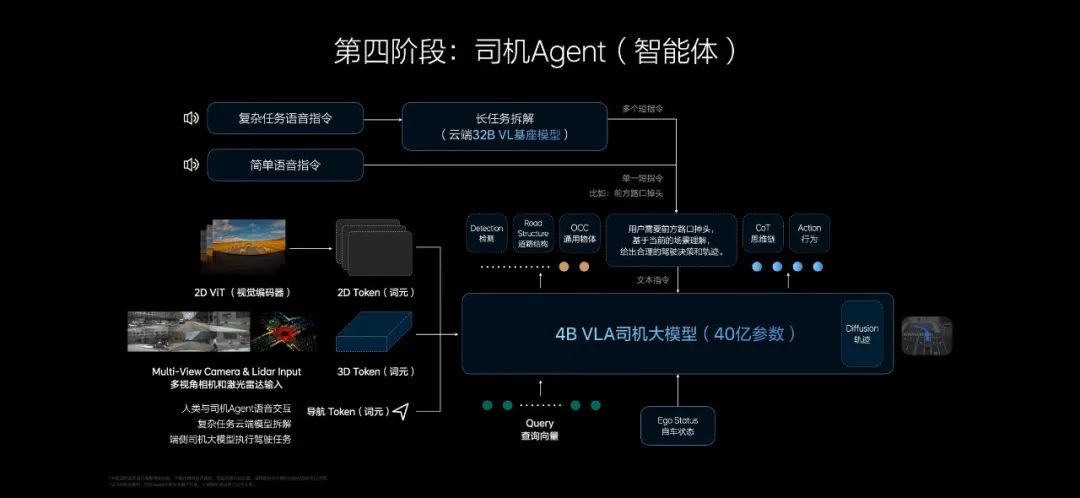
图片来源:理想汽车
区别一在于小鹏对几百亿参数的云端基座大模型做强化学习,理想对几十亿参数的车端VLA模型做强化学习,孰优孰劣,还得看具体的表现,不过,引入强化学习的步骤恰恰也是传统端到端方案和VLA的区别。传统端到端方案依赖数据驱动建立传感器数据-轨迹的因果关联,这种模仿学习缺乏对场景语义的深层解析,对驾驶场景只能做到知其然而不知其所以然,而VLA中的大语言模型经过强化学习,不仅可以知其然,还能做到知其所以然。
区别二在于如何在智驾系统不退出的情况下实现人机共驾。几十亿参数模型的语言理解能力显然不足以做复杂语音指令任务的处理,理想将这部分任务抛给云端,但可能会由于断网、弱网等因素出现不可接受的延迟,而且涉及到云端运营的问题,小鹏直接在座舱部署可处理复杂任务的几百亿参数大模型,缺点在于座舱需要用一颗等价算力高达大几百TOPS的AI芯片,如果没有自己的芯片,会比较烧钱。
写在最后





评论