看懂芯片后端报告 这篇文章最实用

对于动态功耗,后端还可以定制晶体管的源极和漏极的长度,越窄的电流越大,漏电越高,相应的,最高频率就可以冲的更高。所以我们有时候还能看到uLVT C16,LVT C24之类的参数,这里的C就是指Channel Length。
本文引用地址:https://www.eepw.com.cn/article/201702/344323.htm接下去就是Memory,又作Memory Instance,也有人把它称作FCI(Fast Cache Instance)。访问Memory有三个重要参数,read,write和setup。这三个参数可以是同样的时间,也可以不一样。对于一级缓存来说基本用的是同样的时间,并且是一个时钟周期,而且这当中没法流水化。从A73开始,我看到后端的关键路径都是卡在访问一级缓存上。也就是说,这段路径能做多快,CPU就能跑到多快的频率,而一级缓存的大小也决定了索引的大小,越大就越慢,频率越低,所以ARM的高端CPU一级缓存都没超过64KB,这和后端紧密相关。当然,一级缓存增大带来的收益本身也会非线性减小。之后的二三级缓存,可以使用多周期访问,也可以使用多bank交替访问,大小也因此可以放到几百KB/几MB。
逻辑和内存统称为Physical Library,物理库,它是根据工厂给的每个工艺节点的物理开发包(PDK)设计的,而Library是一个Fabless芯片公司能做到的最底层。能够定制自己的成熟物理库,是这家公司后端领先的标志之一。
最后一行,Margin。这是指的工厂在生产过程中,肯定会产生偏差,而这行指标定义了偏差的范围。如下图:
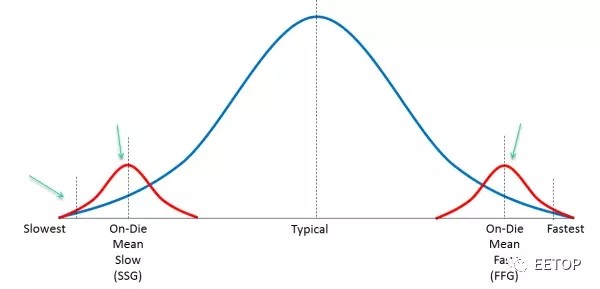
蓝色表示我们刚才说的一些Corner的分布,红色表示生产偏差Variation。必须做一些测试芯片来矫正这些偏差。SB-OCV表示stage-based on-chip variation,和其他的几个偏差加在一起,总共±7%,也就是说会有7%的芯片不在后端设计结束时确定的结果之内。
后面还有一些setup UC之类的,表示信号建立时间,保持时间的不确定性(Uncertainty),以及PLL的抖动范围。
至此,一张报告解读完毕,我们再看看对应的低功耗版实现版本:
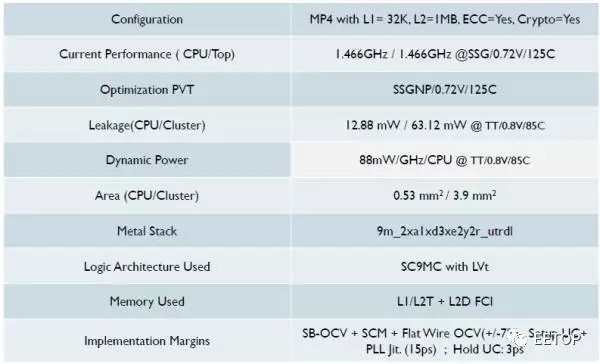
这里频率降到1.5G左右,每Ghz动态功耗少了10%,但是静态降到了12.88mW,只有25%。我们可以看到,这里使用了LVT,没有uLVT,这就是静态能够做低的原因之一。由于面积不是优化目标,它基本没变,这个也是可以理解的,因为Channel宽度没变,逻辑的面积没法变小。











评论