使用 NVIDIA BlueField DPU 和 DPDK 开发应用程序

数据中心转型
本文引用地址:https://www.eepw.com.cn/article/202205/433848.htmNVIDIA BlueField DPU (数据处理器)可用于网络功能加速。这种网络卸载可以用 DPDK ,也可以用 NVIDIA DOCA 软件框架。
在本系列中,我构建了一个应用并用两种方式进行了卸载:DPDK 和 NVIDIA DOCA SDK 。我将每个步骤记录为一个单独的代码补丁,并在每个系列中提供完整的步骤。这部分将向您展示如何用 DPDK 编程 BlueField DPU 。
用例
首先,我需要一个简单但有意义的用例来在 DPU 上部署应用程序。我选择了基于策略的路由( PBR )来根据第 3 层和第 4 层数据包属性将流量引导到不同的网关,覆盖(或补充) X86 主机选择的网关。现实世界中有各种原因需要这样做,包括以下示例:
· 将选定主机流量发送到外部防火墙以进行额外审核
· 增强 Anycast 服务器的负载平衡
· 应用 QoS
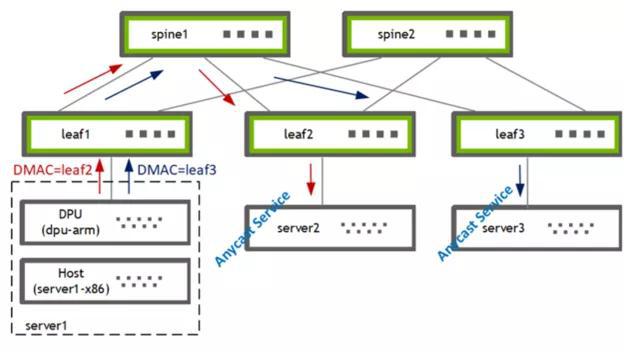
图 1 . 使用 PBR 将流量从主机引导到两个网关之一
我在 DPU (BF2-ARM)上使用 PBR 将流量从主机( server1-x86 )引导到两个网关 [leaf2, leaf3] 之一。叶交换机随后将流量转发给其本地连接的选播服务提供商 [server2, server3] 。
构建应用程序
第一个问题:我是写一个全新的应用程序,还是卸载一个现有的应用程序?
我决定卸载我最喜欢的开源路由软件栈 FRRouting ( FRR )的 PBR 功能。这使我能够扩展现有的代码库,并与现有的 sample apps 形成很好的对比。FRR 有一个支持多种数据平面插件的框架,可以轻松用 DPDK 和 DOCA 实现新的数据平面插件并集成到 FRR 。

图 2 . DPDK 和 DOCA 插件可以很容易地添加到 FRR中
DPU 应用程序原型
在本节中,我将介绍创建具有 DPU 硬件加速功能的应用程序所需的准备工作。
DPU 硬件
我有一个 x86 服务器并在上面安装了一块 BlueFied-2 DPU , 该 DPU 有两个 25G 上行链路和一个带有 8GB 内存的 ARM 处理器 。有关硬件安装的更多信息,请参阅 DOCA SDK 文档 。您也可以使用 DPU PocKit 来构建和引导你的系统环境.
我安装了 BlueField 启动流文件( BFB ),它为 DPU 提供了 Ubuntu 操作系统映像,并附带了 DOCA-1.2 和 DPDK-20.11.3 的库。
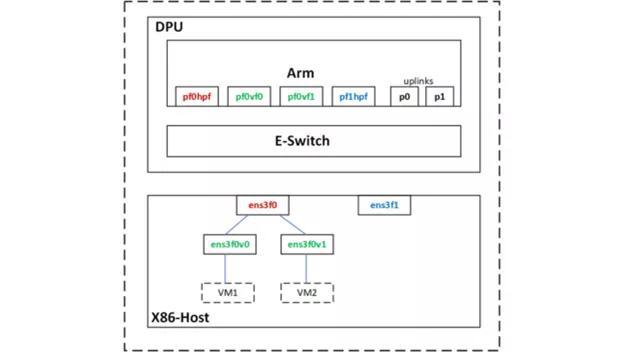
图 3 . Netdev Representors
使用 SR-IOV ,我在主机上为两个虚拟机创建了两个虚拟函数( VF )接口。
主机上的 PF 和 VF 分别映射到 DPU ARM 上的以下 netdev representors 。
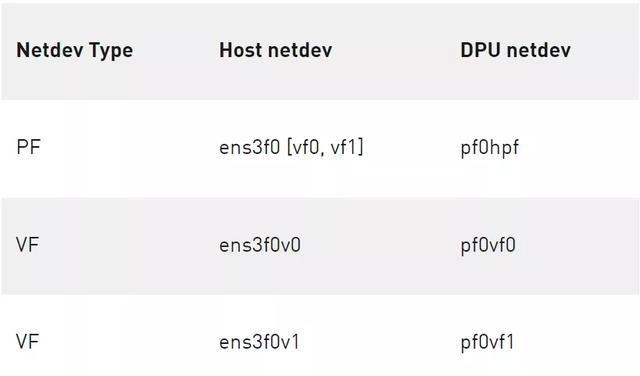
表 1 .主机上 PF 和 VF 的映射
使用 DPDK testpmd 应用程序进行原型设计
首先,我使用 DPDK 的 testpmd 进行了我的用例的原型化设计,它位于 DPU 的 / opt / mellanox / 目录下。
包括 testpmd 在内的任何 DPDK 应用程序都必须设置 hugepages 。

(可选)保留配置,使其在 DPU 重新启动后仍然有效。

启动 testpmd 。

Testpmd 会消耗比较多的内存,默认情况下会分配 3.5 GB 。由于我不需要在 CPU 中处理数据流量,我把 total-mem 的值设定为 200M ,其中 total-mem = total-num-mbufs * mbuf-size (默认 mbuf-size 为 2048 字节)。我还使用了 flow-isolation 模式,因为我必须将 ARP 数据包发送到 DPU 上的内核网络堆栈来解析 PBR 的下一跳)。初始化完成后,-i选项使得 testpmd 进入交互式 shell 。
作为 testpmd 完成 rte_eal 初始化的一部分, mlx5_pci 设备被探测并成为可以被访问的 DPDK 端口。
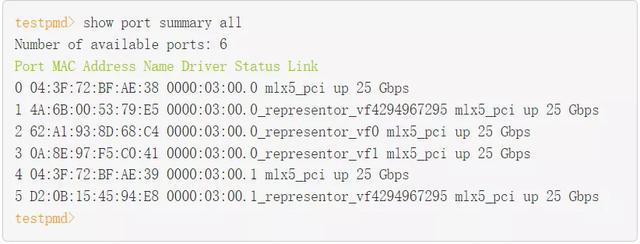
您在这里看到的 DPDK 端口对应 PF / VF representor 和两个上行链路。
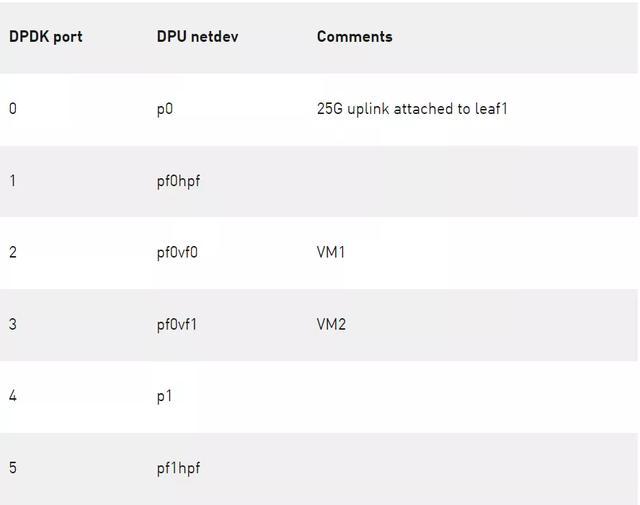
表 2 . DPDK 端口映射
流创建
接下来,通过定义 ingress port 、源 IP 、目标 IP 、协议和端口,我用 rte_flow 下发了PBR规则。除此之外,我还定义了对匹配数据包采取的 ACTION 。源 MAC 和目标 MAC 被重写, TTL 被递减,出口端口被设置为物理上行链路 p0 。

这条 PBR 规则从 VM1接收 DNS 流量,并将其发送到特定的 GW ( leaf2, server2 )。我还增加了一个计数器以便故障定位。

DPU 卸载可以工作在 Switch ( FDB )模式,也可以工作在 NIC 模式。在这个用例中,经过几次数据包修改后,我需要将流量从 X86 主机重定向到 25G 上行链路。所以从概念上讲,这里使用了 Switch ( FDB ) 模式,因此需要设置 rte_flow 的 transfer 属性。
流程验证
我从 VM1 发送了一些流量,看看它是否与我用 testpmd 创建的 flow 是否匹配,可以通过执行 query 命令来查看。

结果是匹配的,在 leaf2/server2 上可以看到这些流量且具有修改后的数据包头。因为被操作的流量是 DNS ,所以为了测试流量,我从 VM1 发送 DNS 请求。为了控制流量速率和其他数据包字段,我使用 mz 来生成测试流量。

另一个健全性检查是查看此流是否真的被卸载。有两种方法可以做到这一点:
· 在 Arm CPU 上使用 tcpdump 以确保内核不接收此类数据包。
· 检查硬件 eSwitch 是否有对应的流规则。
mlx_steering_dump 允许您查看硬件上已经下发成功的流规则。使用 git 下载并安装该工具。

使用 mlx_steering_dump_parser.py 脚本验证硬件中下发的流规则。

此命令打印出 testpmd 应用程序下发的所有流规则。我们可以看到硬件上设置的外部 头匹配信息和前面RTE_FLOW定义的匹配 [SIP = 172.20.0.8 , DIP = 172.30.0.8 , IP proto = UDP , UDP dport = 53] 是一致的。作为打印输出的一部分,流量计数器的值也被读取并被重置。
原型设计,作为应用程序设计思维过程的最后一步现在已经完成。我现在知道我可以在 DPDK 中建立一个 PBR 规则,把它安装在硬件中并对我们感兴趣的数据报文进行修改。现在在下一节中添加 DPDK 数据平面。
构建 DPDK 数据平面插件
在本节中,我将通过向 Zebra 添加一个 DPDK 数据平面插件,介绍 DPU 对 PBR进行 硬件加速的步骤。我将这些步骤分解为单独的代码提交,整个补丁集以 reference 的形式提供。
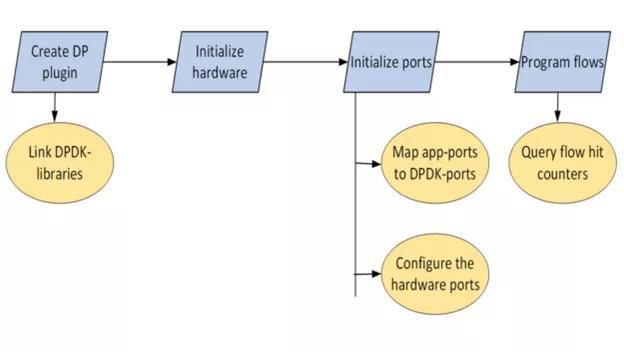
图 4 .基于策略的路由 DPDK 卸载工作流
开发环境
由于目标体系结构是 DPU Arm ,因此可以直接在 DPU Arm上构建、在 X86 CPU 上交叉编译或在云中构建。在这篇文章中,我直接在 DPU Arm 上进行编码和构建。
以 root 用户身份运行应用程序
FRR 通常作为非 root 用户运行。FRR 可以下载和上传整个互联网路由表;这可能会出什么问题?然而,几乎所有的 DPDK 应用程序都是以 root 用户身份运行, DPDK 库和驱动程序也都是基于这样设计的。
经过多次实验,并使用 root 用户选项重新编译 FRR, 我还是无法让 FRR 作为非 root 用户工作。这是可以接受的,因为我在一个安全的空间,即 DPU Arm 中运行 FRR 。
向 Zebra 添加新插件
Zebra 是 FRR 中的一个守护进程,负责整合路由协议守护进程的更新并构建转发表。Zebra 还有一个基础设施,可以将这些转发表推送到像 Linux 内核这样的数据平面。
将 DPDK 共享库链接到 zebra
FRR 有自己的构建系统,限制直接导入外部 make 文件。由于 pkg-config 的简单优雅,将相关库链接到 Zebra 很容易。
我找到了 libdpdk.pc 并将其添加到 PKG_CONFIG_PATH 值中:

FRR 有自己的构建系统,限制直接导入外部 make 文件。由于 pkg-config 的简单优雅,将相关库链接到 Zebra 很容易。
我找到了 libdpdk.pc 并将其添加到 PKG_CONFIG_PATH 值中:
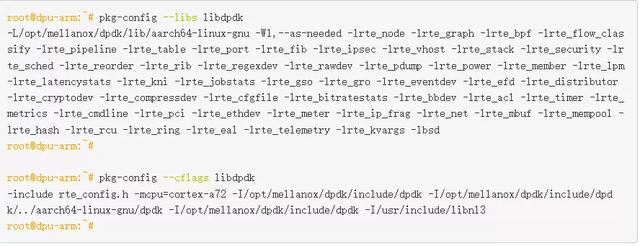
我在 FRR makefile (configure.ac)中为 DPDK 添加了 pkg check-and-define 宏。

我将 DPDK libs和cflags抽象包含在zebra-dp-dpdk make 宏( zebra/subdir.am )中。

有了这些,我就有了构建插件所需的所有头文件和库。
初始化硬件
第一步是初始化硬件。

这将探测 PCIe 设备并填充 DPDK rte_eth_dev 数据库。
初始化端口
接下来设置硬件端口。
设置应用程序的端口映射
FRR 有自己的基于 Linux netdevs 表的接口(端口)表,该表使用 NetLink 更新填充,并使用 ifIndex 键值来索引。PBR 规则锚定到此表中的一个接口。要编程 PBR 数据平面条目,需要一个 Linux ifIndex 和 DPDK port-id 值之间的映射表。netdev 信息已经在 DPDK 驱动程序中可用,可以通过 rte_eth_dev_info_get 查询。

配置硬件端口
此外,所有端口都需要置于 flow-isolation 模式并启动。

Flow-isolation 模式将未命中数据包发送到内核网络堆栈,允许它处理 ARP 请求之类的事情。

使用 rte _流 API 编程 PBR 规则
PBR 规则现在需要用 rte_flow 来编写,下面是一个示例规则:

这些参数通过 rte_flow_attributes 、 rte_flow_item ( match ) 和 rte_flow_action 数据结构填充。
流属性
此数据结构用于指示 PBR 流用于分组重定向或 transfer flow 。

流匹配项
DPDK 为数据包头中的每一层使用 {key, mask} 匹配结构:以太网、 IP 、 UDP 等。

填充这些数据结构需要大量重复的代码。
流动作
DPDK 为每个 Action 使用单独的数据结构,然后允许您在创建流规则时以可变长度数组的形式提供所有 Actions 。有关 Actions 如下:

流验证和创建
作为可选项,您可以验证 rte_flow_attr、rte_flow_item 和 rte_flow_action 列表。

流验证通常用于检查底层 DPDK 驱动程序是否支持特定的流配置。流验证是一个可选步骤,在最后的代码中,您可以直接跳转到流创建。

Rte_flow 命令被锚定到输入端口。可以创建多个流条目组并将这些组链起来。即使流条目不存在链的第一个组中,也就是不在组 0 中,它仍然必须锚定到输入端口。group-0 存在性能限制。
流量插入率在 group-0 中受到限制。要绕过该限制,您可以在 group-0 中安装一个默认流,以“跳转到 group-1 ”,然后在 group-1 中创建流规则。
流删除
流创建 API 返回一个流指针,该指针必须被缓存以进行后续的流删除。

FRR-PBR 守护进程管理状态机来解析,添加或删除 PBR 流。因此,我不必使用 DPDK 的原生函数来老化 PBR 规则。
流量统计
在创建流时,我将计数操作附加到流。可用于查询流量统计信息和命中次数。

为了便于测试和验证,我将该统计显示插入了 FRR 的 vtysh CLI 。
测试应用程序
我以 root 用户的身份启动了 FRR ,并通过 /etc/frr/daemons 文件启用了新添加的 DPDK 插件:
DPDK-port 映射表的 FRR 接口已填充:
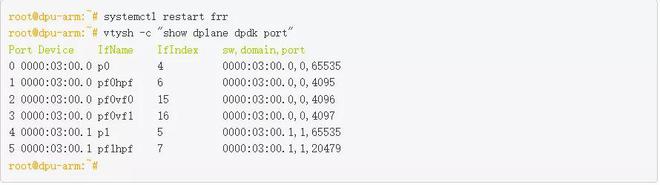
接下来,我将 PBR 规则配置为匹配来自 VM1 的 DNS 流量,并使用 frr.conf 将其重定向到 leaf2 。

我从 VM1 发送 DNS 查询到 anycast DNS 服务器。

匹配流,并使用修改后的数据包头将流量转发到目的地 leaf2/server2 。这可以通过连接到流的计数器和使用 mlx_steering_dump 做硬件转储来验证。

FRR 现在有一个功能齐全的 DPDK 数据平面插件,可以在 DPU 硬件上卸载 PBR 规则。
总结
这篇文章回顾了使用 DPDK RTE_FLOW库在 BlueField 上硬件加速 PBR 规则的 FRR 数据平面插件的创建。在下一篇文章中,我将带您了解 FRR DOCA 数据平面插件,并向您展示如何使用新的 DOCA_FLOW 库卸载 PBR 规则。


评论