UALink还是Ultra Ethernet,面向AI的数据中心协议

AI 和 HPC 数据中心中的计算节点越来越需要扩展到芯片或封装之外,以获取额外的资源来处理不断增长的工作负载。他们可能会征用机架中的其他节点(纵向扩展)或使用其他机架中的资源(横向扩展)。
问题是目前没有开放的 Scale-up 协议。到目前为止,这项任务一直由专有协议主导,因为大部分最高性能的计算都是在大型数据中心使用定制芯片和架构完成的。虽然以太网在横向扩展方面很受欢迎,但对于 AI 和高性能计算工作负载来说,它并不理想。
但两种新协议 UALink 和 Ultra Ethernet 旨在解决当前纵向扩展和横向扩展通信的缺陷。UALink 是一种全新的纵向扩展协议,而 Ultra Ethernet 则基于以太网构建,用于横向扩展。
多重通信职责
“计算节点” 是一个描述某些计算轨迹的抽象概念。它具有有限的容量,可以访问有限数量的内存和其他可能的资源,例如加速器。就其本身而言,它不足以应对高强度工作负载,并且依赖于其他节点来分配整体问题。提供交换数据和协调作所需通信的协议通常可分为三类。
最低级别的协议是 die-to-die 互连,由于先进的封装,它在今天具有相关性。软件包中看起来像单个计算节点的东西可能是多个小芯片一起工作。实现此目的的协议是 UCIe 和 Bunch of Wires (BoW) 以及一些专有协议。但所有这些通信在包装之外都是不可见的。
满载的计算节点可以看作是连接了计算、内存和加速器的服务器主板。但是,主板上可能有多个处理器,因此系统软件会确定哪些工作负载在哪些处理器上运行。但这对于训练 AI 模型所需的任务类型来说还不够。这需要伸手进入机架或 Pod 以利用更多资源。
目标是组装多个计算节点,同时保持单个计算空间的感觉 — 多个处理器和加速器充当具有统一地址的单个大型处理器或加速器。这个中间通信级别是纵向扩展的,这就是 UALink 的用武之地。它与 PCIe 和 CXL 一起工作,但只有 UALink 具有统一分配资源的作用。
“UALink 旨在连接您的主要 GPU 单元,以实现 GPU 到 GPU 的扩展,”Synopsys 高性能计算 IP 解决方案产品管理副总裁 Michael Posner 说。“它旨在增加带宽并减少该连接的延迟。”
GPU 只是加速器的一种类型,UALink 可以广泛地与任何类型的加速器配合使用。然后,UALink 抽象出加速器之间的划分。
“我们的想法是将 AI 处理器互连起来,看起来像这个 Pod 中的一个大型处理器,”Synopsys 首席产品经理 Jon Ames 说。
内存访问是 UALink 角色的重要组成部分。Cadence 硅解决方案集团设计 IP 高级产品营销组总监 Arif Khan 在一篇博文中表示:“UALink 优化了 pod 中加速器之间的 xPU 到 xPU 内存通信,无论是直接连接还是通过完全连接的高基数开关。
超越机架
机架中的资源之外,其他机架中也有类似的资源。但是,这些机架无法通过将单个机架固定在一起的同一互连进行访问。以太网通常在机架之间通信,这就是横向扩展 — 最高通信级别。它类似于 Scale-up,但其覆盖范围比 Scale-up 所能提供的更广泛。此架构在机架内有一个网络(例如 PCIe),在机架外(或网络的另一个层)具有另一个网络。这是纵向扩展和横向扩展之间的主要区别。
“超级以太网解决了横向扩展问题,”Posner 说。“它建立在传统以太网之上。”
Khan 对此表示赞同。“跨 Pod 的扩展依赖于 Ultra Ethernet 来加速数据中心以太网(本质上是替代当今依赖远程 DMA/RoCE 的批量传输),”他说。
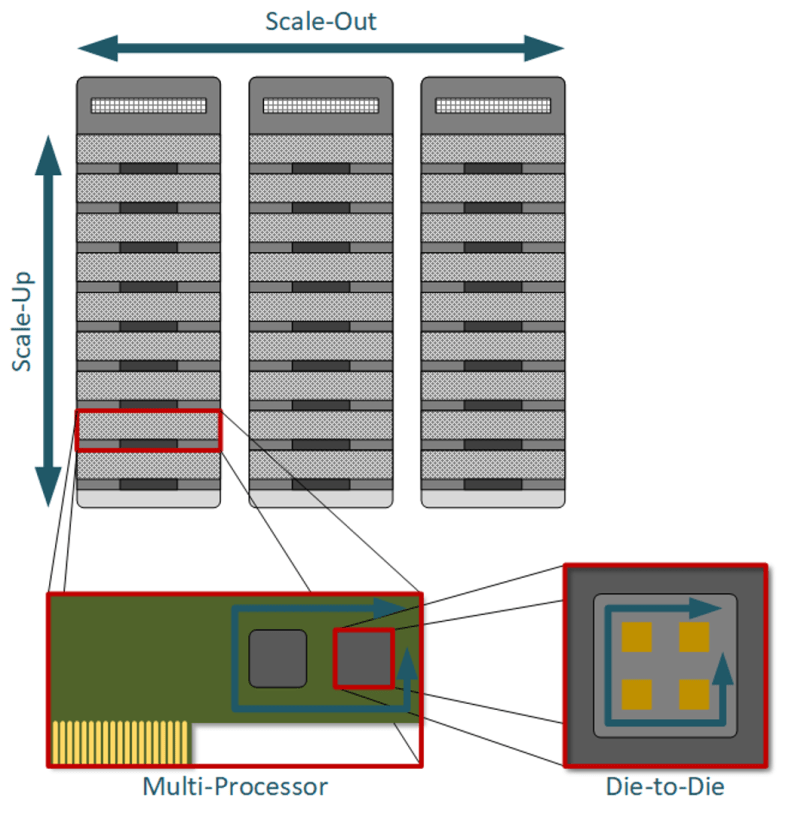
图 1:数据中心互连的四个级别。在整个数据中心中,从一个机架移动到另一个机架构成了横向扩展通信。在同一机架内进行纵向扩展。在高级处理器封装中,晶粒间互连处理晶粒间通信。来源:Bryon Moyer/Semiconductor Engineering
die-to-die 协议和其他协议之间的一个根本区别是链路的基本性质 — 串行与并行。UCIe 和 BoW 都是 parallel interface,通常带有 forwarded clocks。这提供了最低的延迟,同时需要更多的引脚,并使 skew 成为一个更重要的问题。
UALink 和 Ultra Ethernet 使用串行链路。这大大减少了必要信号的数量,但它增加了提取 clock 和解析非 non-return-to-zero (NRZ) 格式的 symbol 值的开销。这种额外的处理是导致 die-to-die 协议提供的链接延迟增加的原因。“与任何接口相比,UCIe 和 BoW 等并行接口的 NoC 到 NoC 延迟都非常低,”Siemens EDA 中央工程解决方案总监 Pratyush Kamal 指出。
纵向扩展:一个绿地
如今,PCIe 和 CXL 可以在机架级别运行,但它们不提供 UALink 创建者正在设计的语义。因此,现有技术由广泛的专有解决方案组成。每家实施 Scaleup 的公司都必须投入资源来设计协议,而多家公司做同样的事情会消耗行业的效率。
“我们看到 UALink 取代了许多专有互连,”Synopsys 的 IP 战略营销经理 Ron Lowman 说。“[创建专有版本的设计师] 使用了从 PCIe 到以太网以及介于两者之间的一切,并通过定制来处理扩展,UALink 正在解决这个问题。”
UALink 联盟于去年秋天正式召开会议,其既定目标是“开发互连技术规范,促进 AI 加速器之间的直接加载、存储和原子作”。事实上,UALink 中的 UA 代表 Ultra Accelerator。它并没有排除 PCIe 或 CXL,这三者的职责之间存在重叠。但是,UALink 正在专门针对 AI 和 HPC 工作负载进行优化。
它由三个主要层组成 — 一个顶部的事务层,用于管理完整事务,一个位于中间的数据链路层,用于管理每个跃点,以及一个处理信号的物理层 (PHY)。前两个是新的,但 PHY 层利用现有的功能来加快实施和采用。
在某种程度上,纵向扩展一直是 PCIe 的领域,但没有针对 AI 进行优化。Lowman 说:“你在 PCIe 中看到的是许多不同的芯片执行许多不同的任务,而 UALink 实际上是在尝试采用 AI 加速器,并将其从 1 扩展到 1,000 来处理单个工作负载。“UALink 不具备 PCIe 的所有功能和向后兼容性,但它可以满足特定的 AI 工作负载需求,例如全局内存寻址和共享内存。”
UALink 的两个初始版本将首次亮相,一个是 224 Gbps,另一个可以放宽半速(-200 和 -100 版本)。两者都将采用以太网 PHY。在初始版本发布后,计划推出 -128 版本,该版本将利用 PCIe Gen 7 的 PHY。
该联盟开发 UALink 并不是为了理想,而是为了快速实现,因为该行业发展得如此之快。“AI 硬件软件的发展速度比硬件的响应速度要快得多,”Lowman 说。“因此,尽快推出有助于扩大规模的产品将对整个行业有益。”
这意味着尽可能多地重复使用现有标准。“我们的想法并不是说以太网和 PCI 是绝对最好的选择,”Lowman 说。“我们的想法是,我们可以使用标准化协议快速进入市场,该协议可以完成纵向扩展架构所需的基本工作。因此,该联盟采用了现有的技术。UALink 128 利用了类似 PCIe 的 PHY,UALink 200 利用了基于以太网的 PHY。
预计 UALink 不会挑战 PCIe 或 CXL。“我们已经就 PCIe、CXL 和 UALink 的定位进行了很多对话,我们坚信它们在市场上都有自己的利基市场,”他说。
UALink 1.0 规范应在下个季度提供,并可免费下载。
横向扩展:基于以太网
构建 由于能够很好地处理广泛的应用程序,以太网已被广泛采用。但它的一些策略会损害性能,主要是由于尾部延迟。
以太网中的通信延迟不是固定的或可预测的。一个事务可能完成而没有问题,而另一个事务可能会遇到链路拥塞,并丢弃数据包,因此需要重新发送。尽管大多数事务可以在最短的时间内完成,但这些工作负载需要所有节点同步才能继续,并且一个链接比其他链接花费的时间更长可能会阻碍一切。术语 tail latency 指的是由这些(希望)少数事务引起的延迟。它们是延迟分布的尾部。
在考虑延迟时,还必须认识到 die-to-die 连接增加的延迟不仅仅是物理层延迟。“重要的是 NoC 到 NoC 的延迟,而不是 PHY 到 PHY 的延迟,”Kamal 说。
由于通信方式的性质,此问题对于 AI 和 HPC 工作负载尤其严重。以太网最常用于传递东西向或南北向的数据流。有一种方向性和一种感觉,“我们完成了那个流程,这是我们最后一次看到它。但 AI/HPC 工作负载与发送数据进行计算,然后返回结果有关。这不仅仅是一条消失的溪流。它是数据输出和结果,一遍又一遍。它更像是呼吸而不是流动,每次发送数据都是呼气,结果是吸气。每次“呼吸”都涉及节点之间的多个交易。
“以太网是专门为成为通用网络而开发的,”超级以太网联盟指导委员会主席 J Metz 说。“如果你有南北交通或东西交通,那就太好了。如果你有集群流量执行 all-to-all、all-reduce 或任何其他集合,那就不太好了。当你来回传递消息,以便它们可以进行自己的处理,然后将其发送回去时,这更像是那种呼吸环境。
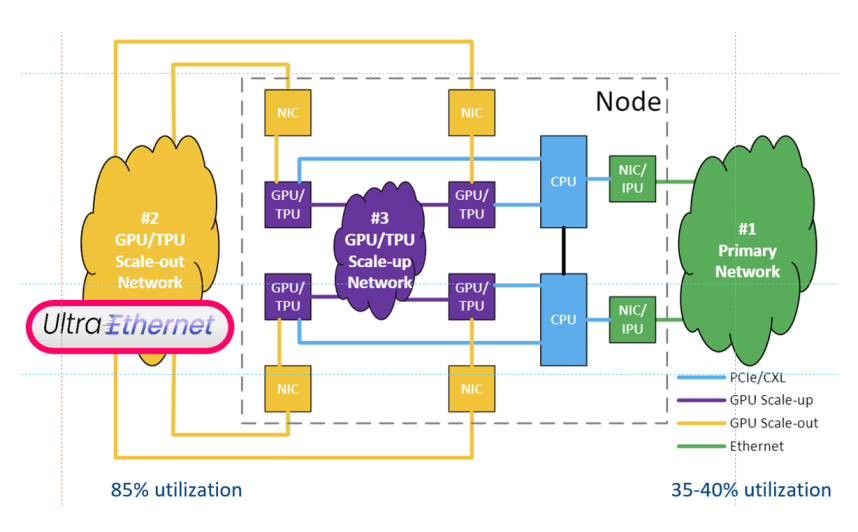
无花果。 2:Ultra Ethernet 在数据中心网络中的位置。纵向扩展发生在节点内,使资源集合看起来像一个虚拟节点。Ultra Ethernet 扩展这些节点。虽然此处未说明,但 CPU 和 GPU 都可以参与。来源:Ultra Ethernet Consortium
尽管 Ultra Ethernet 可以通过网络接口卡 (NIC) 进行连接,但这不是必需的。“结构端点 (FEP) 可以是任何具有结构地址的设备,它可以是加速器本身的合适以太网点,”Metz 说。“FEP 的魔力发生了,包括拥塞、语义和数据包交付控制。”
图 2 展示了一个简化的数据中心网络,重点是 GPU 。但 CPU 也可以参与。“AI 工作流程不是铁板一块,”Metz 说。“在不同集群的 CPU 和 GPU 之间,甚至在集群内部,都存在许多阶段。有些工作最好在 CPU 中完成,有些在 GPU 中完成。
超级以太网联盟 (UEC) 专门针对这种类型的通信,具有一些强制性功能和一些可选功能。给定一个事务,只有终端节点具有强制行为。这是有意为之的,以便可以使用标准以太网交换机构建 Ultra Ethernet 网络。虽然没有提供 Ultra Ethernet 的所有优势,但端点安装可以继续进行,而无需等待新交换机。
向以太网
添加层 标准以太网 指定第 2 层(数据链路)及以下层的功能。它不知道事务或终端节点。它只是逐个跃点移动数据。Ultra Ethernet 在此基础上增加了第 3 层(网络)和第 4 层(传输)。它是管理事务语义的传输层。它必须是安全的吗?所有数据包都必须按顺序到达吗?它必须可靠吗?
“传输部分是 Ultra Ethernet 的重要组成部分,”Ames 说。“它为您提供了可以减少整体系统延迟的机制。”
层的神圣性在传统以太网中没有得到很好的尊重。其他功能已经悄悄渗入了一些层次,而这些层次可能更适合其他层次。Ultra Ethernet 正在努力避免这种情况。“你要确保当你在第二层做某事时,它会做第二层,”Metz 说。“你想在第三层做点什么,它就是第三层。你不做你不在 MAC 层做路由协议。
第 3 层仅使用互联网协议 (IP),保持不变。“[我们]目前没有解决网络层问题,”他说。“从某种意义上说,这很好,因为它有助于简化流程,并使使用 Clos 或叶脊配置的传统数据中心环境变得非常容易。一旦您开始研究 dragonfly、megafly 或 torus [网络拓扑] 等内容,您将在 HPC 环境中更频繁地看到这些,我们就不关注这些了。我们将来必须解决这个问题。
传输层是标准的强制性部分,在端点中实现。“源终端节点将成为核心决策者,然后接收终端节点将提供 [这些决策] 所需的反馈,”Metz 说。在出现问题数据包的情况下,目标不会发送通常的 ACK(确认),而是发送 NACK(否定确认)以及一些诊断信息。
“您可以识别丢失或速度较慢的数据包,并将其发送回源头,”Metz 解释说。“来源将其与它最初选择的任何路径相结合,并在重新提交时选择了不同的路径。”
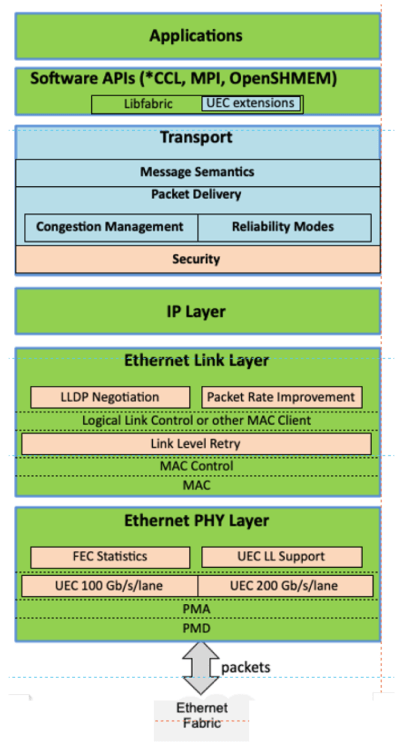
图 3: 超级以太网堆栈包括传输层和网络层,其中传输层是强制性的。到目前为止,网络层采用的 IP 没有变化。数据链路层和物理层添加了新的可选功能。蓝色元素是必需的,绿色元素与以太网相同,米色元素是可选的。来源:Ultra Ethernet Consortium。
新功能有助于减少尾部延迟
展示 Ultra Ethernet 减少延迟的方法的四项功能是无序交付、链路级重试、流量控制和数据包喷射。其中许多交易只是将数据从一个地方发送到另一个地方,只要数据全部到达那里,它到达的顺序就无关紧要。您仍然可以选择按顺序交付,但这不是必需的。
如果某些数据未到达,则无需重新发送整个事务。目标终端节点可以识别任何缺失的数据包,只有那些数据包会被重新发送。此外,如果中间节点沿路径收到一个坏数据包,它可以立即请求重试该数据包,而无需在堆栈上移动并在事务级别处理它。
“链路级重试可以防止堆栈上层的协议不必确定是否需要重新传输某些内容,”Ames 说,并指出了在较低级别响应更快的好处,以及需要只重新发送坏数据包而不是整个事务。
由于链路级重试是一项可选功能,因此在使用新链路层升级交换机之前,早期的 Ultra Ethernet 网络不会具有此功能。
另一个链路层修改与流控制有关。“在链路级别有一个基于信用的流量控制机制,”Ames 说。
最后,标准以太网通常会为流或事务选择一条路径,并在事务期间坚持使用。如果选择了拥塞或其他受损的路径,则该事务可能需要很长时间才能在任何必要的重试后完全到达。数据包喷射是一项可选功能,允许源为每个数据包做出单独的路径决策。
Ames 通过将其与标准以太网进行比较来描述它。“如果节点 A 与节点 Q 通信,则通过一条路径,如果节点 A 与节点 X 通信,则可能会采用不同的路径,”他解释说。“这就是多路径在常规以太网中的工作方式。使用数据包喷射,您可以通过不同的链路发送数据包,网络将在远端处理重组。但通常这只是一次数据传输,所以如果事情不按顺序到达也没关系。
最终,这些功能提供了更快地移动数据包的选项,并且重试次数更少或更多。某些功能(例如安全性)可能会增加典型事务的延迟,但是当系统等待最后一个数据包到达时,尾部延迟是限制因素,而不是标称延迟。是的,每笔交易的到达速度可能会慢一点,但由于最后一个数据包的提前到达,每个人都可以更快地开始。
与 UALink
Ultra 以太网的 1.0 规范类似的时间即将到来。“我们正在考虑在 4 月或 5 月发布,”Metz 说。“它将对所有人开放下载。”一旦发布,就可以快速创建终端节点,而路由上的交换机可能需要更长的时间来升级。
“最终,为端点使用 ASIC 比为交换机使用 ASIC 更快,”Metz 说。“一般来说,交换 ASIC 不是单一用途的,开发周期比端点长得多。它们比端点有更多的功能要求,并且必须经过大量的回归测试。
尽管 UEC 使用的是由 IEEE 管理的标准以太网,但它计划持续保持超级以太网控制,而不是将结果交给 IEEE 处理。“UEC 是一个标准组织,”Metz 解释说。“我们确实与 IEEE 建立了合作关系,与他们合作并共享信息,但 Ultra Ethernet 是一种 UEC 协议。”
挑战在于,IEEE可以在Ultra Ethernet 1.0锁定后对其链路层进行一些更改。现在,链路层的 IEEE 和超级以太网版本不同,它们可能仍然不同。该组织意识到了这一挑战,并通过与与以太网有关系的组织保持沟通来应对这一挑战。
“我们正在与 IEEE、OCP、OIF、SNIA、以太网联盟和 UALink 联盟合作,我们都在共同努力,以确保不会发生这种分叉,”Metz 说。UALink Consortium 证实他们正在以类似的方式工作。
事实上,一个方面已经在发挥作用——为 400 Gbps PHY 做准备,预计可能在 2028/9 年的时间范围内。这似乎很遥远,但已经在进行讨论,以协调任何将依赖该 PHY 的组织之间的努力。最终,目标是所有衍生产品都可以基于一组统一的基本以太网功能进行构建。
结论
目前尚不清楚 HPC 本身是否能证明在这些新协议中付出的努力是合理的,但 AI 无处不在,而且它更像是 HPC 的杀手级应用程序。HPC 当然可以顺势而为,即使发送的交易的具体细节可能与 AI 不同。甚至 AI 也会在不同时间有不同的交易风格。正是出于这个原因,存在各种选项,Ultra Ethernet 允许发送者选择适合给定交易的最佳语义。
有趣的是,这两项努力几乎同时到期,尽管两个组织之间没有协调。鉴于规范将在 2025 年上半年推出,可能会有一个审查期,在此期间,公司会在采用之前评估规范。然后将它们加工成硅至少需要一年时间,因此这些协议可能会在 2026 年底开始出现在数据中心。










评论