无人驾驶技术中的激光雷达和摄像头都干些什么?

在无人驾驶环境感知设备中,激光雷达和摄像头分别有各自的优缺点。
摄像头的优点是成本低廉,用摄像头做算法开发的人员也比较多,技术相对比较成熟。摄像头的劣势,第一,获取准确三维信息非常难(单目摄像头几乎不可能,也有人提出双目或三目摄像头去做);另一个缺点是受环境光限制比较大。
激光雷达的优点在于,其探测距离较远,而且能够准确获取物体的三维信息;另外它的稳定性相当高,鲁棒性好。但目前激光雷达成本较高,而且产品的最终形态也还未确定。

就两种传感器应用特点来讲,摄像头和激光雷达摄像头都可用于进行车道线检测。除此之外,激光雷达还可用于路牙检测。对于车牌识别以及道路两边,比如限速牌和红绿灯的识别,主要还是用摄像头来完成。如果对障碍物的识别,摄像头可以很容易通过深度学习把障碍物进行细致分类。但对激光雷达而言,它对障碍物只能分一些大类,但对物体运动状态的判断主要靠激光雷达完成。
多线激光雷达----多少线合适?
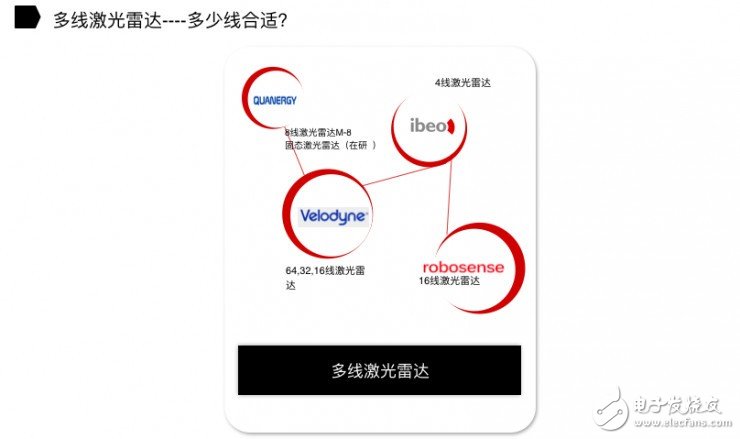
目前,国外和国内做激光雷达的厂商并不多。比如 Velodyne 推出 16 线、32 线和 64 线激光雷达产品。Quanergy 早期推出的 8 线激光雷达产品 M-8(固态激光雷达在研)。Ibeo 主要推出的是 4 线激光雷达产品,主要用于辅助驾驶。速腾聚创(RoboSense)推出的是 16 线激光雷达产品。
到底多少线的激光雷达产品才能符合无人驾驶厂商,包括传统汽车厂商、互联网造车公司的需求?
多线激光雷达,顾名思义,就是通过多个激光发射器在垂直方向上的分布,通过电机的旋转形成多条线束的扫描。多少线的激光雷达合适,主要是说多少线的激光雷达扫出来的物体能够适合算法的需求。理论上讲,当然是线束越多、越密,对环境描述就更加充分,这样还可以降低算法的要求。
业界普遍认为,像谷歌或百度使用的 64 线激光雷达产品,并不是激光雷达最终的产品形态。激光雷达的产品的方向肯定是小型化,而且还要不断减少两个相邻间发射器的垂直分辨率以达到更高线束。
激光雷达产品参数包括四方面:测量距离、测量精度、角度分辨率以及激光单点发射的速度。我主要讲分辨率的问题:一个是垂直分辨率,另一个是水平分辨率。
现在多线激光雷达水平可视角度是 360 度可视,垂直可视角度就是垂直方向上可视范围。分辨率与摄像头的像素是非常相似的,激光雷达最终形成的三维激光点云,类似于一幅图像有许多像素点。激光点云越密,感知的信息越全面。
水平方向上做到高分辨率其实不难,因为水平方向上是由电机带动的,所以水平分辨率可以做得很高。目前国内外激光雷达厂商的产品,水平分辨率为 0.1 度。
垂直分辨率是与发射器几何大小相关,也与其排布有关系,就是相邻两个发射器间隔做得越小,垂直分辨率也就会越小。可以看出来,线束的增加主要还是为了对同一物体描述得更加充分。如果是不通过减少垂直分辨率的方式来增加线束,其实意义不大。
如何去提高垂直分辨率?目前业界就是通过改变激光发射器和接收器的排布方式来实现:排得越密,垂直分辨率就可以做得很小。另一方面就是通过多个 16 线激光雷达耦合的方式,在不增加单个激光雷达垂直分辨率的情况下同样达到整体减小垂直分辨率的效果。
但是,这两种方法都有一定的缺陷。
第一种方法,如果在不增加垂直可视范围情况下增加线束,是有一定天花板的。因为激光发射器的几何大小很难进一步再缩小,比如说做到垂直 1 度的分辨率,如果想做到 0.1 度,几乎不可能。
第二种方法,多传感器耦合,即多个激光雷达耦合,因为它不是单一产品,那么对往后的校准将会有很高的要求。

激光雷达和摄像头分别完成什么工作?
无人驾驶过程中,环境感知信息主要有这几部分:一是行驶路径上的感知,对于结构化道路可能要感知的是行车线,就是我们所说的车道线以及道路的边缘、道路隔离物以及恶劣路况的识别;对非结构道路而言,其实会更加复杂。
周边物体感知,就是可能影响车辆通行性、安全性的静态物体和动态物体的识别,包括车辆,行人以及交通标志的识别,包括红绿灯识别和限速牌识别。
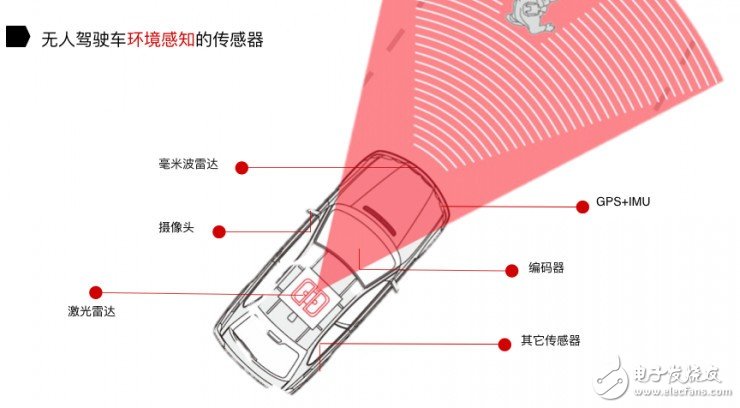
对于环境感知所需要的传感器,我们把它分成三类:
感知周围物体的传感器,包括激光雷达、摄像头和毫米波雷达这三类;
实现无人驾驶汽车定位的传感器,就是 GPS 、IMU 和 Encoder;
其他传感器,指的是感知天气情况及温、湿度的传感器。
今天主要讲的是感知周围物体的传感器,即:激光雷达、毫米波雷达和摄像头。其实他们都有各自的优缺点。

在无人驾驶环境感知中,摄像头完成的工作包括:
车道线检测;
障碍物检测,相当于把障碍物识别以及对障碍物进行分类;
交通标志的识别,比如识别红绿灯和限速牌。

对车道线的检测主要分成三个步骤:
第一步,对获取到的图片预处理,拿到原始图像后,先通过处理变成一张灰度图,然后做图像增强;
第二步,对车道线进行特征提取,首先把经过图像增强后的图片进行二值化( 将图像上的像素点的灰度值设置为 0 或 255,也就是将整个图像呈现出明显的黑白效果),然后做边缘提取;
第三步,直线拟合。
车道线检测难点在于,对于某些车道线模糊或车道线被泥土覆盖的情况、对于黑暗环境或雨雪天气或者在光线不是特别好的情况下,它对摄像头识别和提取都会造成一定的难度。
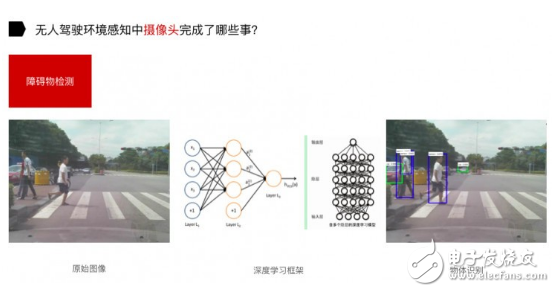
另一个是障碍物检测。上图是我们在十字路口做的实验,获取到原始图像后,通过深度学习框架对物体进行识别。在这当中,做训练集其实是主要的难点。

还有一个是道路标识的识别,这一部分的研究比较多,这里不再赘述。

激光雷达能够完成什么工作?
第一是路沿检测,也包括车道线检测;第二是障碍物识别,对静态物体和动态物体的识别;第三是定位以及地图的创建。
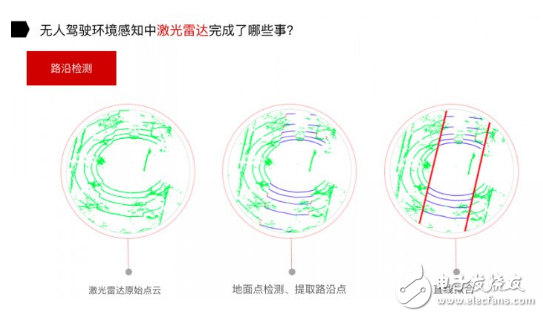
对于路沿检测,分为三个步骤:拿到原始点云,地面点检测、提取路沿点,通过路沿点的直线拟合,可以把路沿检测出来。

接下来是障碍物识别,识别诸如行人、卡车和私家车等以及将路障信息识别出来。

障碍物的识别有这样几步,当激光雷达获取三维点云数据后,我们对障碍物进行一个聚类,如上图紫色包围框,就是识别在道路上的障碍物,它可能是动态也可能是静态的。
最难的部分就是把道路上面的障碍物聚类后,提取三维物体信息。获取到新物体之后,会把这个物体放到训练集里,然后用 SVM 分类器把物体识别出来。

如上图,左上角、左下角是车还是人?对于机器而言,它是不清楚的。右上角和右下角(上图)是我们做的训练集。做训练集是最难的,相当于要提前把不同物体做人工标识,而且这些标识的物体是在不同距离、不同方向上获取到的。
我们对每个物体,可能会把它的反射强度、横向和纵向的宽度以及位置姿态作为它的特征,进行提取,进而做出数据集,用于训练。最终的车辆、行人、自行车等物体的识别是由SVM分类器来完成。我们用这种方法做出来的检测精确度还是不错的。
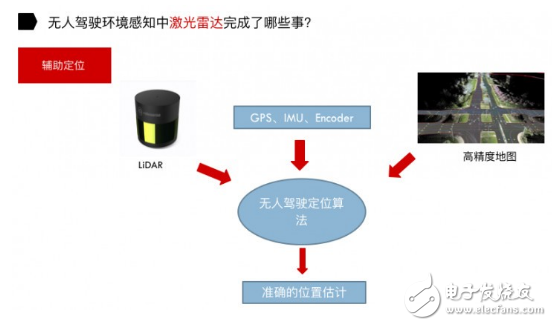
利用激光雷达进行辅助定位。定位理论有两种:基于已知地图的定位方法以及基于未知地图的定位方法。
基于已知地图定位方法,顾名思义,就是事先获取无人驾驶车的工作环境地图(高精度地图),然后根据高精度地图结合激光雷达及其它传感器通过无人驾驶定位算法获得准确的位置估计。现在大家普遍采用的是基于已知地图的定位方法。
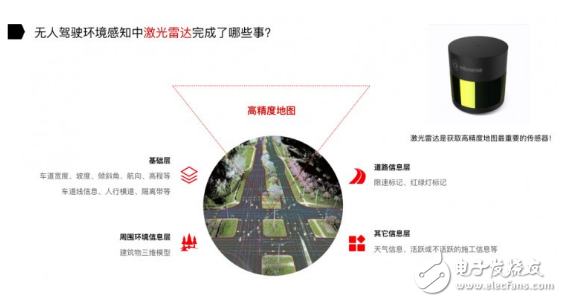
制作高精度地图也是一件非常困难的事情。举个例子,探月车在月球上,原来不知道月球的地图,只能靠机器人在月球上边走边定位,然后感知环境,相当于在过程中既完成了定位又完成了制图,也就是我们在业界所说的 SLAM 技术。
激光雷达是获取高精度地图非常重要的传感器。通过 GPS、IMU 和 Encoder 对汽车做一个初步位置的估计,然后再结合激光雷达和高精度地图,通过无人驾驶定位算法最终得到汽车的位置信息。




评论