如何在32个处理器中编辑并且翻译64固定的点进位计

摘要:介绍嵌式32位CPU在编译器中解决64位运算的方法,并列举一个加法运算的例子,给出可供参考的指令模板。包括32位RISC体系嵌入式CPU层次结构和编译器后端结构。 关键词:RTL 指令模板 编译优化 1 概述 在信息化飞速发展的今天,计算机已成为人们学习和工作不可缺少的工具,我国业已取得了电脑生产大国的地位;但是,作为计算机的核心——CPU的设计与制造,却成了几代计算机工作者的未了习愿,也给国家的安全带来了隐忧。顺应潮流,中芯微系统公司于2001年推出了国内第一颗实用化的32位CPU(方舟一号),主频达到166MHz。下一代方舟CPU将采用0.18μm工艺,超流水结构,主频能达到600MHz以上,在嵌入式CPU领域走到国际前列。 传统的32位计算机处理64位运算通常是设计具体的逻辑电路实现。随着SoC(System on Chip)的出现,芯片上集成各种功能部件越来越多,特别对于嵌入式系统,片上能利用的空间就列加有限,这也要求将部分功能用软件来实现。对于64位长字运算软件实现的方法通常有两种:一是设计系统软件供操作系统内核调用;二是在相关的编译器中设计指令模板来解决。前者执行效率高,但每使用一次就要编译一次;后者只需编译一次,总的效率要高于前者。因此,实际采用在编译器中设计指令模板予以解决。 2 32位RISC体系嵌入式CPU层次结构描述 图1是一个集成了DSP(数字信号处理器)嵌入式CPU的层次图。
本文引用地址:https://www.eepw.com.cn/article/201609/303812.htm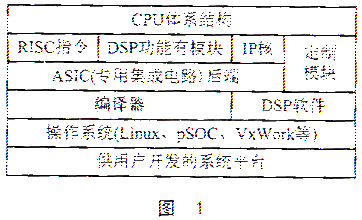
从图1可看到,编译器在整个CPU结构中处于ASIC硬件电路之下和操作系统之上,担负着将高级的、抽象的表达式转化为相对低级的表达式,最终生成系统指令集。 3 CPU编译器后端结构 CPU编译器分为前端和后端:前端主要完成词法/语法分析并生成语法树,这里不再论述;后端是编译的主体部分,它将语法树转换成不间语言,在此不间语言基础上进行各种编译优化,最终生成汇编指令代码。编译后端在进行优化的过程中要跟具体的目标机的机器描述文件多次匹配,生成RTL语言(Register Transfer Language)—GNU CC的中间语言。 机器描述文件由各种与目标机有关的指令模板、功能模板、C语言形式的预处理函数等构成。本文涉及到的64位运算就是由RTL和指令模板多次匹配后生成汇编指令来解决的,过程如图2所示。 限于篇幅,这里仅举64位加法运算的部分例子,其它运算与此类似。 4 64位加法运算指令板 ① RTL识别指令模板,第一次匹配。 (define_insn “adddi3”) [(set(match_operand:DI 0 register_operand =r) (plus:DI (match_operand:DI 1“register_operand”“0”) (match_operand:DI 2 register_operand“r”))) (clobber(reg:SI 6))]//6号寄存器作进位使用 ) ② 将64位加法分解成高32位和低32位运算,第二次匹配。 (define_split [(set(match_operand:DI 0 register_operand“=r”) (plus:DI (match_operand:DI 1“register_operand”“0”) (match_operand:DI 2 “register_operand”“r”))) (clobber(reg:SI 6))] reload_complete “{ [(const_int 0)] //寄存器使用前清零 rtx low[3],high[3]; //rtx为一种处理表达式的数据类型 low[0]=gen_lowpart(Simode,operands[0]); low[1]=gen_lowpart(Simode,operands[1]); low[2]=gen_lowpart(Simode,operands[2]); high[0]=gen_rtx(REG,Simode,REGNO(operands[0]-1); high[1]=gen_rtx(REG,Simode,REGNO(operands[1]-1); high[2]=gen_rtx(REG,Simode,REGNO(operands[2]-1); //由于方舟CPU地址存储方式采用的是Big-Endian,即字节中的最高有效位具有最低序号,所以高位硬寄存器号要减1。 emit_insn(gen_addsi3_set_carry(low[0],low[1],low[2])) //低32位加并设置进位 emit_insn(gen_addsi3_use_carry(high[0],high[1],high[2])); //高32位加并处理进位 DONE;

} ③ 处理低32位加。 (define_insn addsi_set_carry [(set(match_operand:SI 0 (match_operand:SI1 register_operand r) (match_operand:SI 2 register_operand“r”))) (clobber(reg:SI6))] //以下判断是否有进位。有,则6号寄存器置1(set(reg:SI6) (itu:SI(plus:SI(match_dup 1)match_dup 2))(match_dup 1)))] addt%0,%1,%2 //生成低32位汇编模板 ) ④处理高32位加。 (define_insn addi3_use_carry (define_insn adddi3_use_carry [(set(match_operand:SI 0 register_operand“=r”) (plus:SI(plus:SI(match_operand:SI 1 register_operand r)) (reg:SI 6))) (clobber(reg:SI 6))] “” add%0,%1,%2;addt%0,%0,r6 //生成高32位带进位加汇编模板 ) 在机器描述文件中,DI为64位机器方式,SI为32位方式。该文件由机器描述处理程序进行格式转换,它将调用编译内部一套专门的函数和数据结构作为接口,生成gen_开头的预处理函数对指令模板作进一步的处理,再生成由insn_开头的函数对模板作匹配后生成汇编代码。 结语 在方舟二号CPU上测试的结果达到了64运算的要求,相关的指令代码如下: …… 132 r18,[r15,4] 132 r19,[r15,8] add r16,r16,r18 add r17,r17,r19 add r17,r17,r6 …… 用SPEC95进行定点运算测试,可达280MIPS以上,收到了较好的预期结果。







评论