用Synplify Premier加快FPGA设计时序收敛

传统的综合技术越来越不能满足当今采用 90 纳米及以下工艺节点实现的非常大且复杂的 FPGA 设计的需求了。问题是传统的 FPGA 综合引擎是基于源自 ASIC 的方法,如底层规划、区域内优化 (IPO,In-place Optimization) 以及具有物理意识的综合 (physically-aware synthesis) 等。然而,这些从 ASIC 得来的综合算法并不适用于 FPGA 的常规架构和预定义的布线资源。
最终的结果是,所有的三种传统 FPGA 综合方法需要在前端综合与下游的布局布线工具之间进行多次耗时的设计反复,以获得时序收敛。这个问题的解决方案是一种基于图形的独特物理综合技术,能够提供一次通过、按钮操作的综合步骤,不需要 ( 或者需要很少 ) 与下游的布局布线引擎的设计反复。而且,基于图形的物理综合在总体的时钟速度方面可以将性能提高 5% 到 20% 。 Synplify Premier 先进 FPGA 物理综合工具就是这样一种工具,专门针对那些设计很复杂的高端 FPGA 设计工程师而定制,他们的设计需要真正的物理综合解决方案。
本文首先介绍了主要的传统综合方法,并说明这些方法存在的相关问题,然后介绍基于图形的物理综合概念,并指出这种技术如何满足当前先进 FPGA 的设计需求。
传统综合解决方案存在的问题
对于 2 微米的 ASIC 技术节点以及上世纪 80 年代早期以前来说,电路单元 ( 逻辑门 ) 相关的延时与互连 ( 连接线 ) 相关延时的比例约 80:20 ,也就是说门延时约占每个延时路径的 80% 。这样一来,设计师可以用连线负载模型来估计互连延时,在连线负载模型中,每个逻辑门输入被赋予某个 “ 单位负载 ” 值,与某个特定路径相关的延时可以作为驱动门电路的强度和连接线上的总电容性负载的函数来计算得出。
类似地,当在上世纪 80 年代后期 ( 大约引入 1 微米技术节点的时候 ) 第一个 RTL 综合工具开始用在 ASIC 设计中的时候,电路单元的延时与连线延时相比还是占主导地位,比例约为 66:34 。因此,早期的综合工具还是基于它们的延时估计方法,并使用简单的连线负载模型进行优化。由于电路单元的延时占据主导,因此初期综合引擎使用的基于连线负载的时序估计足够准确,下游的布局布线引擎通常能在相对较少的几次反复 ( 在 RTL 和综合阶段之间 ) 条件下实现设计。
然而,随着每个后续技术节点的引入,互连延时大大地增加 ( 事实上,就 2005 年采用 90 纳米技术实现的标准单元 ASIC 来说,电路单元与互连的延时比例现在已经接近 20:80) 。这使得综合引擎的延时估计与布局布线后实际延时的关联性越来越低。
这具有一些很重要的牵连性,因为综合引擎在不同的优化方法之间选择,以及在实现功能的替代方法 ( 诸如基于它们的时序预测的加法器 ) 之间选择。例如,假设某个包含一个加法器 ( 以及其它组件 ) 的特定时序路径被预知具有一些 ( 时序 ) 裕量,这种情况下,综合工具可以选择一个占用芯片面积相对较小的较慢加法器版本。但是,如果时序估计与实际的布局布线后延迟情况出入比较大的话,这个路径可能最后非常慢。这样一来,不准确的延时估计意味着综合引擎最后才对不正确的对象进行优化,只有在完成了布局布线后你才发现问题并不是像你 ( 或综合引擎 ) 所想的那样,其结果是获得时序收敛所需的工作量将大大地增加,因为从前端到后端的设计反复次数大大增加了。
为了解决这些问题,有必要了解在综合过程中与设计相关的物理特性。因此,随着时间的推移, ASIC 综合技术 ( 紧跟着 FPGA 综合技术 ) 采用了一系列的方法 ( 某些情况下也抛弃了一些方法 ) ,例如下面讨论的底层规划、 IPO 和具有物理意识的综合。
底层规划
对于 ASIC 的 RTL 综合,底层规划技术在上世纪 90 年代早期出现,稍晚于综合技术本身的问世。底层规划工具允许设计师在器件上定义物理区域,通过手工或者使用自动交互技术来对这些区域布局,并将设计的不同部分分配到这些区域。
底层规划涉及到逐个模块地综合和优化设计,然后在最后将所有东西 “ 缝合 ” 在一起 ( 早期底层规划工具使用的综合算法都是基于连接线负载模型 ) 。这意味着底层规划工具不能按每个单元优化逻辑,只能影响逻辑模块的布局。而且,在定义上,底层规划工具不会全局性地考虑布线资源,在设计完全布线完成之前,它不可能准确分析所有的时序路径。这会导致在前端和后端工具之间的大量耗时的设计反复。尽管这种方法可以提高 ASIC 设计的时序性能和降低功耗,但它需要对设计的复杂分析和很高的专业技术水准。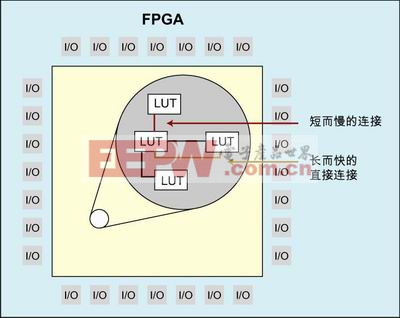
图 1 : FPGA 的主流架构。
在早期,采用 ASIC 底层规划有下面几个原因:作为一种获得时许收敛的方法解决有限容量的问题,并支持基于逐个模块的递增变化。最近,底层规划不再被认为是一种其本身能获得时序收敛的方法;底层规划依然是一种有用的方法,但只是在与其它方法 ( 例如物理优化 ) 结合的时候才有用,使用综合后门级网表的底层规划依然需要非常多的专门技术。
对于 FPGA 来说,直到上世纪 90 年代晚期,底层规划技术还没有成为主流应用。平均而言,在一个 FPGA 设计中,关键路径一般会经过 3 个区域。由于 FPGA 一般用到的设计方法,如果使用综合后 (“ 门级 ”) 网表来执行底层规划,即使对 RTL 的相对较小的改变都可能导致先前所做的底层规划工作付之东流。解决这个问题的方法是在 RTL 级进行底层规划。然而,为了更有用,这必须和某种形式的物理优化相结合,源于 ASIC 的物理综合算法并不适合于 FPGA 的常规架构以及预定义的布线资源。
布局优化
随着底层规划在 ASIC 领域的作用逐渐弱化,在上世纪 90 年代中期, IPO 技术对其进行了强化 / 或者替代。这再次地涉及到时序分析和估计是基于连接线负载模型的综合。
在这种情况下,所产生的网表被传递到下游的布局布线引擎。在布局布线和寄生提取之后,实际的延时被背注到综合引擎。这些新值触发器在综合引擎中的递增优化,例如逻辑重构和复制。其结果是得到一个被部分修改的新网表。然后,这个网表被递交到递增布局布线引擎,产生一个改进的设计拓扑。
基于 IPO 流程所得到的最后结果比那些采用底层规划方法获得的通常更好。然而,这种方法同样可能需要在前端和后端工具之间进行很多次设计反复。而且基于 IPO 方法的一个重要的问题是对布局布线的修改可能导致新的关键路径,这个路径在前一次反复中是看不到的,即修正一个问题可能会激起其它的问题,这可能导致收敛的问题。
对于 FPGA 设计,基于 IPO 的设计流程大约在 2003 年开始受到主流关注。然而,尽管这样的流程已经可用,但那时这些流程并没有以一种有意义的方式得到采用,因为单个地优化时序路径的 IPO 技术通常导致其它路径时序的劣化和时序收敛不完全。设计师需要可使他们在不牺牲之前设计版本获得的成果的基础上对设计进行改变的可靠结果。但是基于 IPO 的方法并不能在多次设计反复之上产生稳定的结果,因为在一次反复中优化关键路径会在下一次反复中产生新的关键路径。类似地,增加约束以改进一个区域的时序可能使其它的区域的时序恶化。
具有物理意识的综合
当前先进的 ASIC 综合技术是具有物理意识的综合,这种综合技术在大约 2000 年开始受到主流关注。不考虑实际的技术 ( 有几种不同的算法 ) ,具有物理意识的综合的基本概念是在一次性完成的过程中结合布局和综合。
这在 ASIC 领域中的实践效果很好,因为了解布局的综合引擎能根据已布局的单元的周边和 Steiner 以及 Manhattan 布线估计进行时序的预估。这种综合方法在 ASIC 中效果很好的原因是连接线有序地布置。这意味着与最后的布局和布线设计相关的延时与综合引擎所估计的结果具有非常好的相关性。












评论