揭秘FPGA:为什么比 GPU 的延迟低这么多?

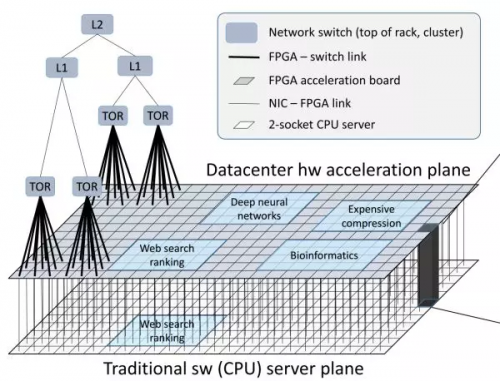
▲FPGA 构成的数据中心加速平面,介于网络交换层(TOR、L1、L2)和传统服务器软件(CPU 上运行的软件)之间。来源:[4]
通过高带宽、低延迟的网络互联的 FPGA 构成了介于网络交换层和传统服务器软件之间的数据中心加速平面。
除了每台提供云服务的服务器都需要的网络和存储虚拟化加速,FPGA 上的剩余资源还可以用来加速 Bing 搜索、深度神经网络(DNN)等计算任务。
对很多类型的应用,随着分布式 FPGA 加速器的规模扩大,其性能提升是超线性的。
例如 CNN inference,当只用一块 FPGA 的时候,由于片上内存不足以放下整个模型,需要不断访问 DRAM 中的模型权重,性能瓶颈在 DRAM;如果 FPGA 的数量足够多,每块 FPGA 负责模型中的一层或者一层中的若干个特征,使得模型权重完全载入片上内存,就消除了 DRAM 的性能瓶颈,完全发挥出 FPGA 计算单元的性能。
当然,拆得过细也会导致通信开销的增加。把任务拆分到分布式 FPGA 集群的关键在于平衡计算和通信。
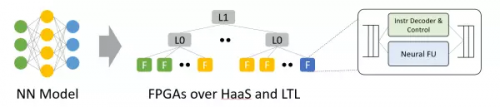
▲从神经网络模型到 HaaS 上的 FPGA。利用模型内的并行性,模型的不同层、不同特征映射到不同 FPGA。来源:[4]
在 MICRO'16 会议上,微软提出了 Hardware as a Service (HaaS) 的概念,即把硬件作为一种可调度的云服务,使得 FPGA 服务的集中调度、管理和大规模部署成为可能。
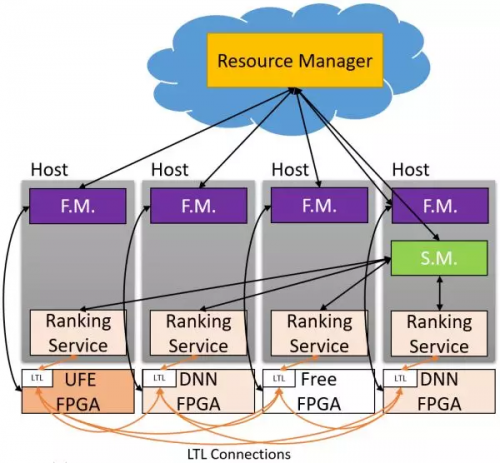
▲Hardware as a Service (HaaS)。来源:[4]
从第一代装满 FPGA 的专用服务器集群,到第二代通过专网连接的 FPGA 加速卡集群,到目前复用数据中心网络的大规模 FPGA 云,三个思想指导我们的路线:
硬件和软件不是相互取代的关系,而是合作的关系;
必须具备灵活性,即用软件定义的能力;
必须具备可扩放性(scalability)。
FPGA在云计算中的角色
最后谈一点我个人对 FPGA 在云计算中角色的思考。作为三年级博士生,我在微软亚洲研究院的研究试图回答两个问题:
FPGA 在云规模的网络互连系统中应当充当怎样的角色?
如何高效、可扩放地对 FPGA + CPU 的异构系统进行编程?
我对 FPGA 业界主要的遗憾是,FPGA 在数据中心的主流用法,从除微软外的互联网巨头,到两大 FPGA 厂商,再到学术界,大多是把 FPGA 当作跟 GPU 一样的计算密集型任务的加速卡。然而 FPGA 真的很适合做 GPU 的事情吗?
前面讲过,FPGA 和 GPU 最大的区别在于体系结构,FPGA 更适合做需要低延迟的流式处理,GPU 更适合做大批量同构数据的处理。
由于很多人打算把 FPGA 当作计算加速卡来用,两大 FPGA 厂商推出的高层次编程模型也是基于 OpenCL,模仿 GPU 基于共享内存的批处理模式。CPU 要交给 FPGA 做一件事,需要先放进 FPGA 板上的 DRAM,然后告诉 FPGA 开始执行,FPGA 把执行结果放回 DRAM,再通知 CPU 去取回。
CPU 和 FPGA 之间本来可以通过 PCIe 高效通信,为什么要到板上的 DRAM 绕一圈?也许是工程实现的问题,我们发现通过 OpenCL 写 DRAM、启动 kernel、读 DRAM 一个来回,需要 1.8 毫秒。而通过 PCIe DMA 来通信,却只要 1~2 微秒。
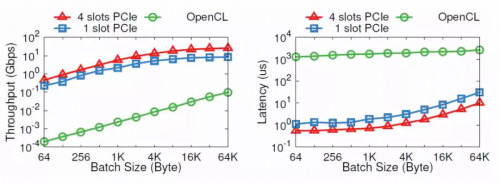
▲PCIe I/O channel 与 OpenCL 的性能比较。纵坐标为对数坐标。来源:[5]
OpenCL 里面多个 kernel 之间的通信就更夸张了,默认的方式也是通过共享内存。
本文开篇就讲,FPGA 比 CPU 和 GPU 能效高,体系结构上的根本优势是无指令、无需共享内存。使用共享内存在多个 kernel 之间通信,在顺序通信(FIFO)的情况下是毫无必要的。况且 FPGA 上的 DRAM 一般比 GPU 上的 DRAM 慢很多。
因此我们提出了 ClickNP 网络编程框架 [5],使用管道(channel)而非共享内存来在执行单元(element/kernel)间、执行单元和主机软件间进行通信。
需要共享内存的应用,也可以在管道的基础上实现,毕竟 CSP(Communicating Sequential Process)和共享内存理论上是等价的嘛。ClickNP 目前还是在 OpenCL 基础上的一个框架,受到 C 语言描述硬件的局限性(当然 HLS 比 Verilog 的开发效率确实高多了)。理想的硬件描述语言,大概不会是 C 语言吧。
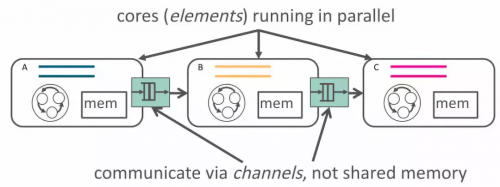
▲ClickNP 使用 channel 在 elements 间通信,来源:[5]
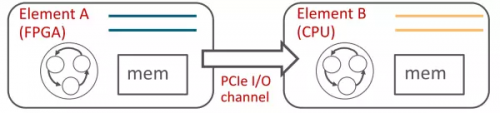
▲ClickNP 使用 channel 在 FPGA 和 CPU 间通信,来源:[5]
低延迟的流式处理,需要最多的地方就是通信。
然而 CPU 由于并行性的限制和操作系统的调度,做通信效率不高,延迟也不稳定。
此外,通信就必然涉及到调度和仲裁,CPU 由于单核性能的局限和核间通信的低效,调度、仲裁性能受限,硬件则很适合做这种重复工作。因此我的博士研究把 FPGA 定义为通信的「大管家」,不管是服务器跟服务器之间的通信,虚拟机跟虚拟机之间的通信,进程跟进程之间的通信,CPU 跟存储设备之间的通信,都可以用 FPGA 来加速。
成也萧何,败也萧何。缺少指令同时是 FPGA 的优势和软肋。
每做一点不同的事情,就要占用一定的 FPGA 逻辑资源。如果要做的事情复杂、重复性不强,就会占用大量的逻辑资源,其中的大部分处于闲置状态。这时就不如用冯·诺依曼结构的处理器。
数据中心里的很多任务有很强的局部性和重复性:一部分是虚拟化平台需要做的网络和存储,这些都属于通信;另一部分是客户计算任务里的,比如机器学习、加密解密。
首先把 FPGA 用于它最擅长的通信,日后也许也会像 AWS 那样把 FPGA 作为计算加速卡租给客户。
不管通信还是机器学习、加密解密,算法都是很复杂的,如果试图用 FPGA 完全取代 CPU,势必会带来 FPGA 逻辑资源极大的浪费,也会提高 FPGA 程序的开发成本。更实用的做法是FPGA 和 CPU 协同工作,局部性和重复性强的归 FPGA,复杂的归 CPU。
当我们用 FPGA 加速了 Bing 搜索、深度学习等越来越多的服务;当网络虚拟化、存储虚拟化等基础组件的数据平面被 FPGA 把持;当 FPGA 组成的「数据中心加速平面」成为网络和服务器之间的天堑……似乎有种感觉,FPGA 将掌控全局,CPU 上的计算任务反而变得碎片化,受 FPGA 的驱使。以往我们是 CPU 为主,把重复的计算任务卸载(offload)到 FPGA 上;以后会不会变成 FPGA 为主,把复杂的计算任务卸载到 CPU 上呢?随着 Xeon + FPGA 的问世,古老的 SoC 会不会在数据中心焕发新生?
「跨越内存墙,走向可编程世界」(Across the memory wall and reach a fully programmable world.)
参考文献:
[1] Large-Scale Reconfigurable Computing in a Microsoft Datacenter https://www.microsoft.com/en-us/research/wp-content/uploads/2014/06/HC26.12.520-Recon-Fabric-Pulnam-Microsoft-Catapult.pdf
[2] A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA'14 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/Catapult_ISCA_2014.pdf
[3] Microsoft Has a Whole New Kind of Computer Chip—and It’ll Change Everything
[4] A Cloud-Scale Acceleration Architecture, MICRO'16 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/10/Cloud-Scale-Acceleration-Architecture.pdf
[5] ClickNP: Highly Flexible and High-performance Network Processing with Reconfigurable Hardware - Microsoft Research
[6] Daniel Firestone, SmartNIC: Accelerating Azure's Network with. FPGAs on OCS servers.













评论