揭秘FPGA:为什么比 GPU 的延迟低这么多?

▲本地和远程的 FPGA 均可以降低搜索延迟,远程 FPGA 的通信延迟相比搜索延迟可忽略。
FPGA 在 Bing 的部署取得了成功,Catapult 项目继续在公司内扩张。
微软内部拥有最多服务器的,就是云计算 Azure 部门了。
Azure 部门急需解决的问题是网络和存储虚拟化带来的开销。Azure 把虚拟机卖给客户,需要给虚拟机的网络提供防火墙、负载均衡、隧道、NAT 等网络功能。由于云存储的物理存储跟计算节点是分离的,需要把数据从存储节点通过网络搬运过来,还要进行压缩和加密。
在 1 Gbps 网络和机械硬盘的时代,网络和存储虚拟化的 CPU 开销不值一提。随着网络和存储速度越来越快,网络上了 40 Gbps,一块 SSD 的吞吐量也能到 1 GB/s,CPU 渐渐变得力不从心了。
例如 Hyper-V 虚拟交换机只能处理 25 Gbps 左右的流量,不能达到 40 Gbps 线速,当数据包较小时性能更差;AES-256 加密和 SHA-1 签名,每个 CPU 核只能处理 100 MB/s,只是一块 SSD 吞吐量的十分之一。

▲网络隧道协议、防火墙处理 40 Gbps 需要的 CPU 核数。
为了加速网络功能和存储虚拟化,微软把 FPGA 部署在网卡和交换机之间。
如下图所示,每个 FPGA 有一个 4 GB DDR3-1333 DRAM,通过两个 PCIe Gen3 x8 接口连接到一个 CPU socket(物理上是 PCIe Gen3 x16 接口,因为 FPGA 没有 x16 的硬核,逻辑上当成两个 x8 的用)。物理网卡(NIC)就是普通的 40 Gbps 网卡,仅用于宿主机与网络之间的通信。
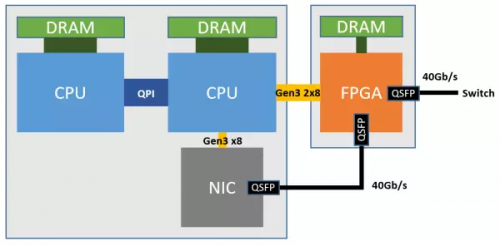
▲Azure 服务器部署 FPGA 的架构。
FPGA(SmartNIC)对每个虚拟机虚拟出一块网卡,虚拟机通过 SR-IOV 直接访问这块虚拟网卡。原本在虚拟交换机里面的数据平面功能被移到了 FPGA 里面,虚拟机收发网络数据包均不需要 CPU 参与,也不需要经过物理网卡(NIC)。这样不仅节约了可用于出售的 CPU 资源,还提高了虚拟机的网络性能(25 Gbps),把同数据中心虚拟机之间的网络延迟降低了 10 倍。
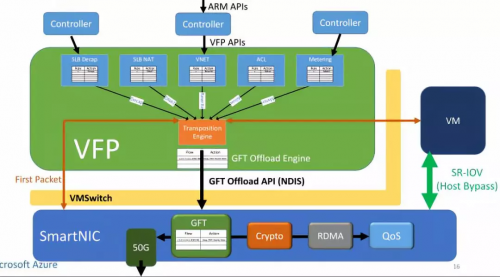
▲网络虚拟化的加速架构。来源:[6]
这就是微软部署 FPGA 的第三代架构,也是目前「每台服务器一块 FPGA」大规模部署所采用的架构。
FPGA 复用主机网络的初心是加速网络和存储,更深远的影响则是把 FPGA 之间的网络连接扩展到了整个数据中心的规模,做成真正 cloud-scale 的「超级计算机」。
第二代架构里面,FPGA 之间的网络连接局限于同一个机架以内,FPGA 之间专网互联的方式很难扩大规模,通过 CPU 来转发则开销太高。
第三代架构中,FPGA 之间通过 LTL (Lightweight Transport Layer) 通信。同一机架内延迟在 3 微秒以内;8 微秒以内可达 1000 块 FPGA;20 微秒可达同一数据中心的所有 FPGA。第二代架构尽管 8 台机器以内的延迟更低,但只能通过网络访问 48 块 FPGA。为了支持大范围的 FPGA 间通信,第三代架构中的 LTL 还支持 PFC 流控协议和 DCQCN 拥塞控制协议。
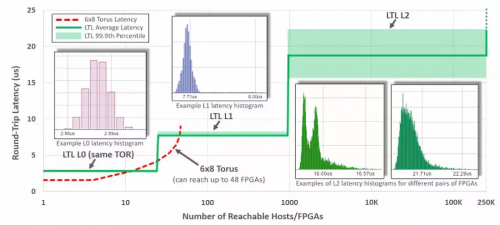
▲纵轴:LTL 的延迟,横轴:可达的 FPGA 数量。来源:[4]
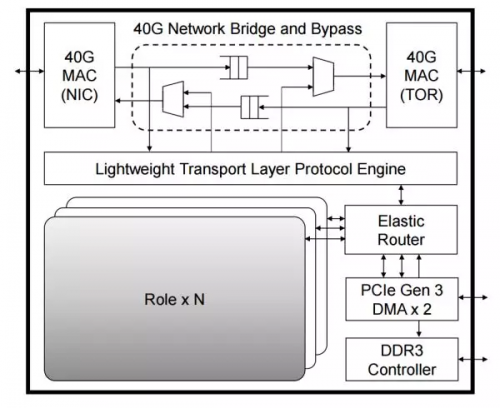
▲FPGA 内的逻辑模块关系,其中每个 Role 是用户逻辑(如 DNN 加速、网络功能加速、加密),外面的部分负责各个 Role 之间的通信及 Role 与外设之间的通信。来源:[4]












评论