基于Q-Coder算术编码器的IP核设计与仿真

1 概述
本文引用地址:https://www.eepw.com.cn/article/170822.htm JPEG2000[1,2]是新的静止图像压缩标准,它具有的多种特性使得它有着广泛的应用前景。目前为止,JPEG2000的解决方案比较少,并且其中的绝大部分是软件解决方案:Jasper[3]软件是经IEC JTC1/SC29/WG1小组推荐使用的实现JPEG2000的为数不多的软件之一。
由于软件实现JPEG2000的时间开销比较大,因此,JPEG2000编码系统很难应用于实际系统中;硬件解决方案由于处理速度大大提高,因而用硬件实现JPEG2000具有广泛的市场前景。但是,JPEG2000算法复杂,完全用硬件实现比较困难;然而使用硬件实现JPEG2000中的某些模块,相对而言就比较容易实现,同时也能大大提高编码效率。
图1为JPEG2000的几个基本模块。文献[4]指出,软件处理中,图1中的算术编码模块的时间开销占据了整个软件时间开销的40%左右,若使用硬件实现算术编码模块必然能大大提高编码速度,对于提高JPEG2000的编码速度有着重要的意义。
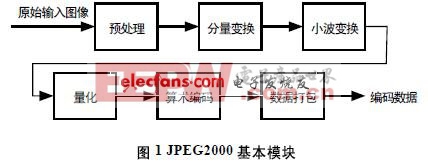
Q-coder算术编码是一种特殊的高效自适应二进制算术编码器。其输入是成对待编码数据D(DATA)以及上下文CX(CONTEXT),数据D和上下文CX是由比特平台(bit plane)[1]产生的;输出则是压缩数据CD(COMPRESSED DATA)。在JPEG2000中,上下文指D周围8个相邻比特的状态,这些状态被特定的规则划分为19类,称为19种上下文。每种上下文都包含两部分内容,一部分选择了对数据D编码时使用的概率估计值对应的索引,另一部分决定了当前大概率符号所代表的符号,这两部分内容将在编码后被更新。
2.1 区间的递归划分
概率区间的递归划分是二进制算术编码的基础。每执行一次二元判定,当前概率区间就被划分成为两个子区间,并在必要的时候修改输出码流,使之指向该符号所在的概率子区间的下界。
在区间划分时,小概率符号的子区间和大概率符号的子区间这样排序:通常取靠近0的区间作为MPS的子区间,因此,若编码的是MPS,则应向输出码流中加入LPS子区间的长度。这种约定要求把编码的符号区别为LPS或MPS,而不是0或者1。因此在对一次二元判定编码时,必须知道该判定的LPS子区间的长度和MPS的含义。
2.2 编码约定和近似计算
Q-coder算术编码器设置两个寄存器:一个是概率区间宽度寄存器A,用于存放子区间的宽度,另一个是码字寄存器C,用来表示概率区间的下限。编码过程使用固定精度的整数运算和小数的整型表示形式,即X‘8000’代表十进制小数0.75。概率区间A的范围是,并且当A的整型值小于X‘8000’时,把A翻倍,即把A限制在十进制范围0.75–1.5之间,这个“翻倍”过程称为重整化。当A进行重整化时,C也必须同时翻倍。为了防止寄存器C发生上溢,每隔一段时间,应将寄存器C的高位部分移出并送至另外的寄存器中。
将A限制在十进制范围0.75~1.5之间,概率区间的划分可以使用简单的算术近似方法。如果LPS当前的概率估计值是,则子区间的精确计算如下进行:










评论