嵌入式零树小波EZW编码及其算法改进

在基于小波变换的图象压缩方案中,嵌入式零树小波 EZW(Embedded Zerotree Wavelets)[1]编码很好地利用小波系数的特性使得输出的码流具有嵌入特性。近年来,在对EZW改进的基础上,提出了许多新的性能更好的算法,如多级树集合分裂算法(SPIHT :Set Partitioning In Hierarchical Trees)[2],集合分裂嵌入块编码(SPECK:Set Partitioned Embedded bloCK coder),可逆嵌入小波压缩算法(CREW:Compression with Reversible Embedded Wavelets)[3] 。本文对这些算法进行了原理分析、性能比较,说明了嵌入式小波图象编码的研究方向。
本文引用地址:https://www.eepw.com.cn/article/150328.htm 1. 1算法原理:
内嵌编码[1](embedded coding)就是编码器将待编码的比特流按重要性的不同进行排序,根据目标码率或失真度大小要求随时结束编码;同样,对于给定码流解码器也能够随时结束解码,并可以得到相应码流截断处的目标码率的恢复图象。内嵌编码中首先传输的是最重要的信息,也就是幅值最大的变换系数的位信息。图1显示了一个幅度值由大到小排序后的变换系数的二进制列表。表中每一列代表一个变换系数的二进制表示,每一行代表一层位平面,最上层为符号位,越高层的位平面的信息权重越大,对于编码也越重要。内嵌编码的次序是从最重要的位(最高位)到最不重要的位(最低位)逐个发送,直到达到所需码率后停止。
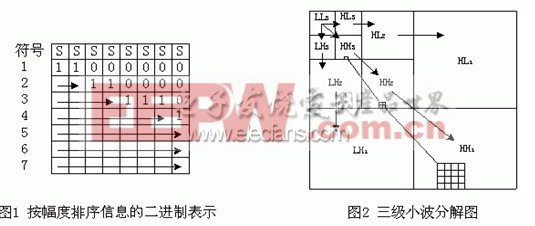
由图1可知内嵌编码的输出信息主要包括两部分:排序信息和重要象素的位信息。其中,位信息是编码必不可少的有效信息,对应于表中箭头所划过的比特位;而排序信息则是辅助信息,按其重要性从左到右排列,反映了重要象素在原图上的空间位置,用于恢复原始的数据结构。因此,内嵌算法中排序算法的优劣和排序信息的处理决定了整个编码算法的效率。
一副图象经过三级小波分解后形成了十个子带,如图2所示。小波系数的分布特点是越往低频子带系数值越大,包含的图象信息越多,如图2中的LL3子带。而越往高频子带系数值越小,包含的图象信息越少。就是在数值相同的情况下,由于低频子带反映的是图象的低频信息,对视觉比较重要,而高频子带反映的是图象的高频信息,对视觉来说不太重要。这样对相同数值的系数选择先传较低频的系数的重要比特,后传输较高频系数的重要比特。正是由于小波系数具有的这些特点,它非常适合于嵌入式图象的编码算法。在JPEG2000标准中以小波变换作为图象编码的变换方法。
EZW算法利用小波系数的特点较好地实现了图象编码的嵌入功能,主要包括以下三个过程:零树预测,用零树结构编码重要图,逐次逼近量化。
1) 零树预测
一副经过小波变换的图象按其频带从低到高形成一个树状结构,树根是最低频子带的结点,它有三个孩子分别位于三个次低频子带的相应位置,见图2左上角,其余子带(最高频子带除外)的结点都有四个孩子位于高一级子带的相应位置(由于高频子带分辨率增加,所以一个低频子带结点对应有四个高频子带结点,即相邻的2×2矩阵,见图2)。这样图2所示的三级小波分解就形成了深度为4的树。
定义一个零树的数据结构:一个小波系数x,对于一个给定的门限T,如果|x|
2) 用零树结构编码重要图
重要图包括三种要素:即重要系数、孤立零和零树根。其中,对于一个给定的阈值T,如果系数X本身和它的所有的子孙都小于T,则该点就称为零树根;如果系数本身小于T,但其子孙至少有一个大于或等于T,则该点就称为孤立零点。在编码时分别用三种符号与之对应。当编码到最高分辨率层的系数时,由于它们没有子孙,零树根不再存在,只需其余两种符号即可。为了有利于内嵌编码,将重要系数的符号与重要图一起编码,这样就要使用四种符号:零树根、孤立零、正重要系数、负重要系数。
3) 逐次逼近量化(Successive-Approximation Quantization,SAQ)
内嵌编码的核心在于采用了逐次逼近的量化方法(SAQ)。SAQ按顺序使用了一系列阈值T0、T1,┄,TN-1来判决重要性,其中Ti=Ti-1/2,初始阈值T0按如下条件选择,OXjO2T0,其中Xj表示所有变换系数。
在编(译)码过程中,始终保持着两个分离的列表:主表和辅表。主表对应于编码中的不重要的集合或系数,其输出信息起到了恢复各重要值的空间位置结构的作用,而辅表是编码的有效信息,输出为各重要系数的二进制值。编码分为主、辅两个过程:在主过程中,设定阈值为Ti,按上述原理对主表进行扫描编码,若是重要系数,则将其幅值加入辅表中,然后将该系数在数组中置为零,这样当阈值减小时,该系数不会影响新零树的出现;在辅过程中,对辅表中的重要系数进行细化,细化过程类似于比特平面编码。对阈值Ti来说,重要系数的所在区间为[Ti,2Ti],若辅表中的重要系数位于[Ti,3Ti/2],则用符号“0”表示,否则用符号“1”表示。编码在两个过程中交替进行,在每个主过程前将阈值减半。译码时系数的重构值可以位于不确定区间的任意处,如果采用MMSE准则,则重构值应位于不确定区间的质心处。实际中为简单起见使用区间的中心作为重构值。
1. 2算法分析:
研究表明,在图象的低比特率编码中,用来表示非零系数所在位置的开销远远大于用来表示非零系数值的开销。零树结构正是一种描述图象经过小波变换后非零数值位置的有效方法。EZW的编码思想是不断扫描变换后的图象,生成多棵零树来对图象编码:一棵零树的形成需要对图象进行两次扫描。在生成第一棵零树时,首先找出变换后图象的最大绝对值系数,用它对应的T0作初始阈值,对图象进行第一次扫描。将图象中绝对值小于阈值系数都看作零,然后按前面的符号定义形成零树。在第二次扫描中,对那些绝对值大于阈值的结点(POS和NEG)按其绝对值是否大于阈值的1.5倍附加一个比特1或0来描述其精度。这样做的目的是减小非零结点系数值的变化范围,使其适应下一次阈值减半后的比特附加(具体细节见文[1])。而后将阈值减半,再经两次扫描生成第二棵零树,在第一次扫描生成零树时,以前已经大于阈值的结点不再考虑,而第二次扫描附加比特时则要考虑以前数值较大的结点以保证精度。如此重复下去,不断生成零树,直到达到需要的编码精度为止。
研究发现EZW算法存在的问题是:
(1).由于编码时它形成多棵零树,因而要多次扫描图象,造成效率很低。而且每一棵树必须在前一棵树形成之后才能形成,所以也很难用并行算法优化。
(2).对所有的频域进行等同重要度的编码,不能充分利用小波变换的特点。改进办法之一是把最低频子图与其它子图分开处理,对其进行单独的无失真编码。
(3).在一棵零树中包含的元素越多,则越有利于数据压缩。在EZW算法中存在这样的树间冗余,在SPIHT算法中则进一步利用了这种树间冗余。
(4).通过对小波系数的分析发现,在同一子带中相邻元素间有一定的相关性,尤其在高频子带存在大量的低值元素,所以可以通过子带中的集合把大量的这种低值元素组织到一起,达到数据压缩的目的。而EZW算法并没有充分利用这种相关性。在SPECK算法中利用这种相关性达到了数据压缩的目的。
2. 多级树集合分裂算法 SPIHT
原理分析:
EZW算法是一种基于零树的嵌入式图象编码算法,虽然在小波变换系数中,零树是一个比较有效的表示不重要系数的数据结构,但是,在小波系数中还存在这样的树结构,如图2,即它的树根是重要的,除树根以外的其它结点是不重要的。对这样的系数结构零树就不是一种很有效的表示方法。A.Said和W.A.Pearlman根据Shapiro零树编码算法(EZW)的基本思想,提出了一种新的且性能更优的实现方法,即基于分层树集合分割排序(Set Partitioning in Hierarchical Trees,SPIHT)的编码算法。它采用了空间方向树(SOT:spatial orientation tree)、集合D(i,j)和L(i,j)更有效地表示这样的系数结构,从而提高了编码效率。
1)SPIHT算法中用到的概念
算法中的一些符号和概念说明如下:
● H:空间方向树所有根结点的坐标集合;
● Z(i,j):点(i,j)及其所有的后代的坐标集合,即指空间方向树;
● D(i,j):点(i,j)的所有后代(子孙)的坐标集合,不包括(i,j)点本身;
● O(i,j):点(i,j)的直接后代(儿子)的坐标集合,在分层塔形结构的最高层H有O(i,j)={(i+LL,j),(i,j+LL),(i+LL,j+LL)},除此之外的结点有O(i,j)={(2i,2j),(2i,2j+1),(2i+1,2j), (2i+1,2j+1)},这里LL为最高层H的尺度。
● L(i,j):点(i,j)除直接后代外所有后代坐标的集合;
linux操作系统文章专题:linux操作系统详解(linux不再难懂)




评论