基于FPGA有限域构造的QC-LDPC分层译码器设计

低密度奇偶校验(Low Density Parity—Check,LDPC)码最早于1962年由R.Gallager提出,其实质是一类具有稀疏校检矩阵的线性分组码。1996年,Mackay、Neal等人证明了LDPC码是一种具有逼近Shannon极限性能的好码,但其随机构成特性又给编译码的实现带来了较大复杂度,在码长较长时,这种复杂度是硬件设计所难以接受的。准循环低密度奇偶校检(Quasi-Cyclic Low Density Party-Check,QC-LDPC)码的出现,因其准循环特性,使得以更低的复杂度实现编译码成为可能。同时,QC-LDPC码在误码率上和随机LDPC码具有同样优秀的性能,因此,QC—LDPC码成为众多标准采用的信道编码方案。QC—LDPC码译码器设计初期多采用部分并行结构,此后出现了分层译码结构。分层译码结构拥有更快的译码速度,更好的性能和更简单的硬件结构,成为QC—LDPC译码器的主流结构。但是,分层译码要求QC—LDPC码的校验矩阵每个分层的列重≤1。本文中采用有限域乘群构造的QC—LDPC码的校验矩阵每个分层的列重恰好等于1,满足分层译码的要求。为进一步降低硬件复杂度,采用归一化最小和算法(NMSA),整个译码过程中只包括比较、移位和加减运算,优化了硬件结构,降低了硬件实现复杂度。
本文引用地址:https://www.eepw.com.cn/article/201610/308315.htm设q是任意质数或质数的幂,则整数集{0,1,2,…,q-1}在模q加法和模q乘法下构成有限域GF(q)。GF(q)的q-1个非0元素构成GF(q)在乘法操作下的乘法群,简称乘群。对于其中的每个非0元素i,定义M位置矢量z(i)为GF(2)上的(q-1)维数组z(i)=(z1,z2,…,zn-1),其第i个分量zi=1,所有其余q-2个分量均为0。GF(q)的0元素对应的M位置矢量定义为q-1维全0数组。显然,GF(q)中的任意元素i+2的M位置矢量z(i+2)可由i的位置矢量z(i)循环右移2位得到。
构造QC—LDPC码校验矩阵的步骤如下:
步骤1 由本原元确定构成有限域GF(q)的全部元素。
设本原元α,则
构成GF(q)的所有元素。根据预期构造校验矩阵的大小选择合适的有限域GF(q)。
步骤2 构成在GF(q)上的(q-1)×(q-1)的基矩阵W(1)。
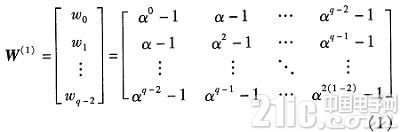
矩阵W(1)具有以下结构特性:(1)任意两行或者两列在所有位置上的元素都不相同。(2)任一行或一列中的条目是GF(q)中不同元素。(3)每行或列中有且仅有一个0元素,第i行(1≤i≤q-2)的0元素位于第i行第(q-1-i)mod(q-1)列。(4)矩阵中每一行是上一行的左循环移位,第一行是最后一行的左循环移位。
步骤3 矩阵W(1)先后经乘对折垂直扩展,乘对折水平扩展得到矩阵H(1)。

H(1)具有以下结构特性:(1)A0,0,A1,q-2,A2,q-3,…,Aq-2,1均是(q-1)×(q-1)的0矩阵,其他子矩阵都是同维数的循环置换矩阵。(2)H(1)的每一行或每一列中有且仅有一个0矩阵。(3)H(1)子矩阵的每一行是上一行左循环移位的结果,第一行是最后一行的左循环移位。(4)H(1)是在GF(2)上的(q-1)2×(q-1)2矩阵,行重和列重都是q-2。
步骤4 构造QC—LDPC的校验矩阵Hqc。
构造行重为λ,列重为ρ(1≤λ,ρ≤q-1)的规则QC—LDPC码校验矩阵Hqc的步骤:(1)从0~q-2之间选择λ和ρ个不相等的随机数组成随机坐标对。(2)从H(1)中选取相应的元素作为基矩阵。(3)将基矩阵填充到Hqc时,选取的λ×ρ个循环移位矩阵之间的相对位置保持不变。
采用反正法来证明所构造的QC—LDPC码对应的Tanner图中不存在长为4的环。

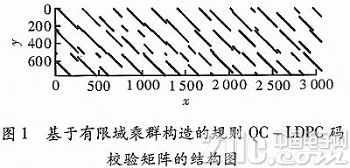
图1给出了该方法构造的规则(3 060,765,3,12)QC—LDPC码校验矩阵的结构,其中该矩阵的基矩阵是一个3×12矩阵,每个子矩阵的大小为255×255,矩阵的列重为3,行重为12,码率为,码长为3 060。
2 QC-LDPC码的译码方案
2.1 LDPC码传统译码算法
置信度传播(Belief Propagation,BP)译码算法是传统的LDPC码译码算法,对它进行改进又出现了最小和算法(Min Sum Algorithm,MSA),归一化最小和算法(Normalizat ion Min Sum Algorithm,NMSA)等。这类算法因其通过校验节点更新和变量节点更新两个步骤完成一次迭代译码,被称为2项置信传播(Two Phase Message Passing,TPMP)算法。TPMP算法在一次迭代译码过程中,全部的校验节点更新结束后,所有的变量节点才开始更新,即在一次迭代过程中,所有信息只更新一次。所以,该算法的收敛速度较慢,译码延迟较大。
2.2 并行分层置信传播译码算法
并行分层置信传播译码算法的出现改变了TPMP算法的译码方式,它是将校验矩阵按行或列分成几个分层,分别进行更新。在一次迭代译码过程中,首先对第一分层的所有校验节点以及相关变量节点进行更新,然后逐层进行信息更新。因此,后面分层更新时要利用到前面分层已更新的信息,这样变量节点在一次迭代过程中得到多次更新,大幅加快了译码收敛速度,提高了译码性能。但分层译码算法能分层进行变量节点更新的要求是:校验矩阵每个分层的列重不大于1。按上述方法构造的校验矩阵每个分层的列重恰好等于1。
假设高斯白噪声信道的噪声方差为σ2,接收到的信号序列为y,校验矩阵的大小为M×N。迭代过程中,变量节点信息用Zn,m表示,校验节点信息用Lm,n表示,后验概率信息用Fn表示。采用BPSK调制方式,分层译码算法的译码过程简述如下:
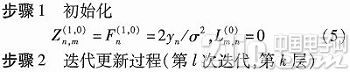

3 分层译码器结构设计
对构造的(3 060,765,3,12)QC—LDPC码进行分层译码器的设计,按照校验矩阵的结构,将其按行分为3层,这样每个子块的列重恰好等于1。采用层内并行,层间串行的分层译码算法,每个分层包含255个校验节点,因此,需要255个校验节点处理模块(PCNPM)同时工作,即并行度为255。在硬件设计时,将修正因子α设为0.75,这样只需要简单的带符号右移和加法运算即可做到数据的修正。对译码器的数据进行7 bit量化,在计算过程中,若出现了数据溢出,则采用截断法来处理溢出数据,这样的处理方法对译码性能带来约0.1 dB的损失,但大幅降低了设计复杂度,节约了硬件资源。
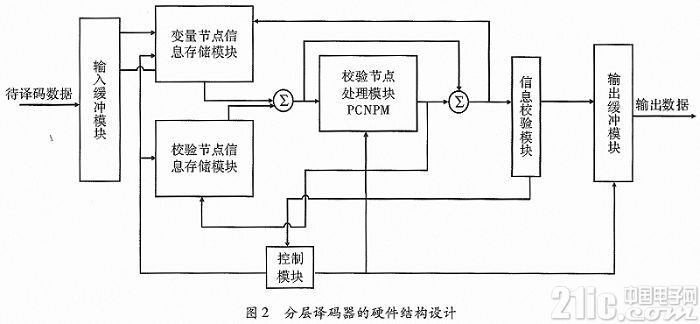
3.1 输入缓冲模块
输入缓冲模块主要有以下两个功能:(1)从信道接收译码数据,且保证数据不丢失。(2)将接收到的译码数据传递给变量节点信息存储模块,完成迭代译码过程中的部分初始化工作。
3.2 信息存储模块
信息存储模块包括两部分:(1)校验节点信息存储模块Rmem,因为有255个校验节点处理模块同时工作,因此需要255个Rmem双端口RAM来存储校验节点更新数据,每个RAM的存储容量为3×7×12=252 bit。(2)变量节点信息存储模块Lmem,用来存储后验概率信息Fn。基于校验矩阵结构,将3 060个后验概率信息分为12块来存储,每块存储255个数据,即每块RAM的存储容量为256×7 bit。
3.3 校验节点处理模块
该模块是整个译码器的核心部分,完成迭代译码过程中的校验节点和变量节点的信息更新。在更新结构上,采用分层间串行,分层内并行的处理机制。该部分的结构如图3所示。
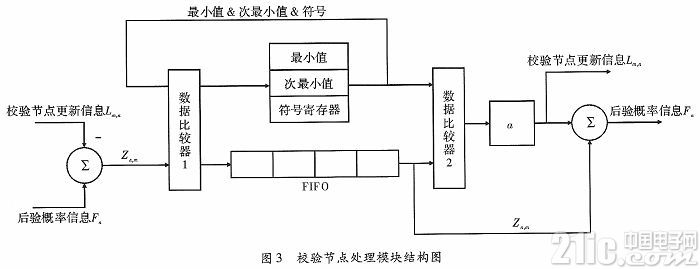
如图3所示,该模块分为6部分:(1)减法器,后验概率信息Fn和校验节点信息Lm,n通过减法器后更新变量节点信息Zn,m。(2)数据比较器1,寻找与一个校验节点连接的12个变量节点中变量节点信息绝对值最小和次最小的数据,并记录这组数据的符号。(3)FIFO和最小值、次最小值、符号寄存器,将接收到的数据与最小值寄存器和次最小值寄存器中的数据进行比较,并更新最小值和次最小值寄存器;将数据的符号位与符号寄存器的值做异或运算,更新符号寄存器,之后将该时刻输入的数据存入FIFO。(4)数据比较器2,将从FIFO中读出的数据与最小值和次最小值寄存器中的数值进行比较,然后做出选择。(5)校正因子,将从数据比较器2中输出的数据做带符号位的右移一位和右移两位,再求和,得到修正数据。(6)加法器,将从校正因子部分输出的数据和从FIFO中读出的变量节点信息通过加法器相加,得到变量节点后验概率信息Fn。
3.4 控制模块
该模块分为两部分:(1)地址控制模块,该模块包含一个存储着校验矩阵所有子块位置和偏移量信息的ROM,从中读取信息来产生变量、校验节点存储模块的读地址和写地址。(2)状态控制模块,设置整个译码过程的状态机,控制每个模块的工作状态。
3.5 信息校验模块
在迭代译码的过程中,每个分层更新结束之后,对所有更新的变量节点进行校验,若所有变量节点满足校验方程,就无需进行下面分层的译码,此次迭代结束;否则继续进行迭代译码,直到达到最大迭代次数。
3.6 输出缓冲模块
暂存迭代译码过程中产生的判决结果,并在译码结束后向外部输出数据。
4 FPGA综合结果及分析
在实现译码器的过程中,采用Altera公司StratixII系列的器件EP2S60F484C4,综合结果如表1所示。

吞吐率和纠错能力是衡量一个译码器性能的两个主要指标。其中吞吐率用式(10)进行评估

其中,f是译码器的工作频率;N是码长;R是码率;dini表示译码器的初始化时延;dpro表示译码器的译码时延。
在译码过程中,首先从输入缓冲模块读出数据对变量节点信息存储模块进行初始化,共需128个时钟周期。每个分层进行校验、变量节点信息更新需要16个时钟周期,则此迭代过程共需要花费3×5×16+128×5=880个时钟周期。因此,译码器的吞吐率可达(35.38×3 060×0.75)/880=92.27 Mbit·s-1。
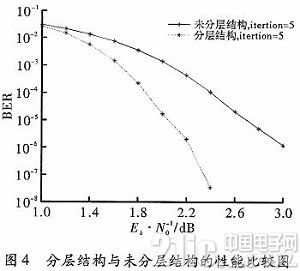
将构造的(3 060,765,3,12)QC—LDPC码分别采用分层结构和未分层结构,在NMSA基础上进行的性能仿真如图4所示。从图中可看出,BER=10-6时,分层结构比未分层结构有约0.8 dB的性能增益。
5 结束语
本文基于有限域乘群构造了Tanner图中无4环的QC—LDPC码,随后基于构造的QC—LDPC码,采用分层译码算法设计了分层译码器,分层结构较未分层结构有更好的收敛性。最后采用Altera公司StratixII系列的器件,将分层译码器在FPGA上得以实现,并得到较高的译码吞吐率。












评论