雷达信号处理:FPGA还是GPU?

FPGA和CPU一直是雷达信号处理不可分割的组成部分。传统上FPGA用于前端处理,CPU用于后端处理。随着雷达系统的处理能力越来越强,越来越复杂,对信息处理的需求也急剧增长。为此,FPGA不断在提高处理能力和吞吐量,CPU也在发展以满足下一代雷达的信号处理性能需求。这种努力发展的趋势导致越来越多的使用CPU加速器,如图形处理单元(GPU)等,以支持较重的处理负载。
本文引用地址:https://www.eepw.com.cn/article/221498.htm本文对比了FPGA和GPU浮点性能和设计流程。最近几年,GPU已经不仅能完成图形处理功能,而且成为强大的浮点处理平台,被称之为GP-GPU,具有很高的峰值FLOP指标。FPGA传统上用于定点数字信号处理器(DSP),而现在足以竞争完成浮点处理功能,也成为后端雷达处理加速功能的有力竞争者。
在FPGA前端,40 nm和28 nm均报道了很多可验证的浮点基准测试结果。Altera的下一代高性能FPGA将采用Intel的14 nm三栅极技术,性能至少达到5 TFLOP。使用这种先进的半导体工艺,性能可实现100 GFLOPs/W。而且,Altera FPGA现在支持OpenCL,这是GPU使用的一款优秀的编程语言。
峰值GFLOPS指标
目前的FPGA性能可达到1TFLOP以上峰值,AMD和Nvidia最新的GPU甚至更高,接近4 TFLOP。但在某些应用中,峰值GFLOP,即TFLOP,提供的器件性能信息有限。它只表示了每秒能完成的理论浮点加法或乘法总数。这一分析表示,在雷达应用中,很多情况下,FPGA在算法和数据规模上超过了GPU吞吐量。
一种中等复杂且常用的算法是快速傅里叶变换(FFT)。大部分雷达系统由于在频域完成大量处理工作,因此会经常用到FFT算法。例如,使用单精度浮点处理实现一个4,096点FFT。它能在每个时钟周期输入输出四个复数采样。每个FFT内核运行速度超过80 GFLOP,大容量28 nm FPGA的资源支持实现7个此类内核。
但如图1所示,该FPGA的FFT算法接近400 GFLOP。这一结果基于“按键式”OpenCL编译,无需FPGA专业知识。使用逻辑锁定和设计空间管理器(DSE)进行优化,7内核设计接近单内核设计的fMAX,使用28 nm FPGA,将其提升至500 GFLOP,超过了10 GFLOPs/W。
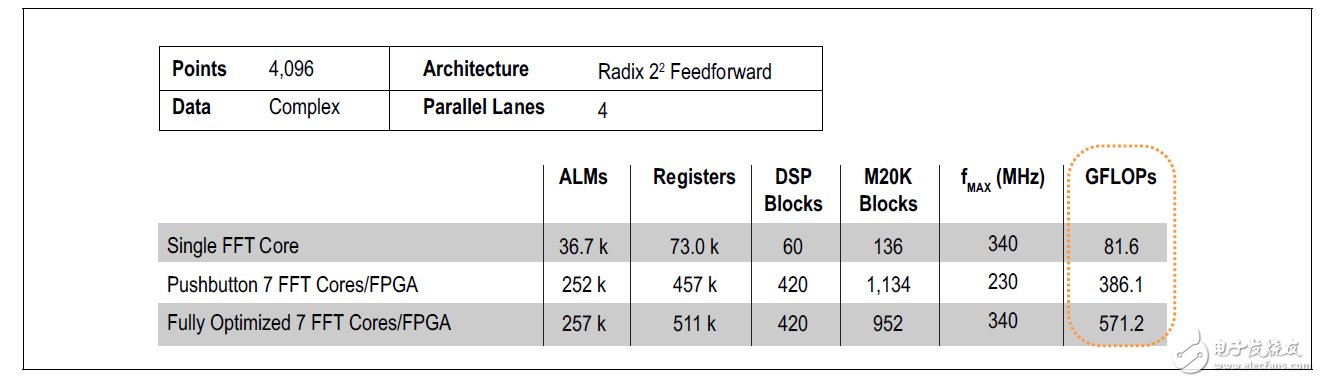
图1.Stratix V 5SGSD8 FPGA浮点FFT性能
这一GFLOPs/W结果要比CPU或者GPU功效高很多。对比GPU,GPU在这些FFT长度上效率并不高,因此没有进行基准测试。当FFT长度达到几十万个点时,GPU效率才比较高,能够为CPU提供有效的加速功能。但是,雷达处理应用一般是长度较短的FFT,FFT长度通常在512至8,192之间。
总之,实际的GFLOP一般只达到峰值或者理论GFLOP的一小部分。出于这一原因,更好的方法是采用算法来对比性能,这种算法能够合理的表示典型应用的特性。随着基准测试算法复杂度的提高,其更能代表实际雷达系统性能。
算法基准测试
相比依靠供应商的峰值GFLOP指标来驱动处理技术决策,另一方法是使用比较复杂的第三方评估。空时自适应处理(STAP)雷达常用的算法是Cholesky分解。这一算法经常用于线性代数,高效的解出多个方程,可以用在相关矩阵上。
Cholesky算法在数值上非常复杂,要获得合理的结果总是要求浮点数值表示。计算需求与N3成正比,N是矩阵维度,因此,一般对处理要求很高。雷达系统一般是实时工作,因此,要求有较高的吞吐量。结果取决于矩阵大小以及所要求的矩阵处理吞吐量,通常会超过100 GFLOP。
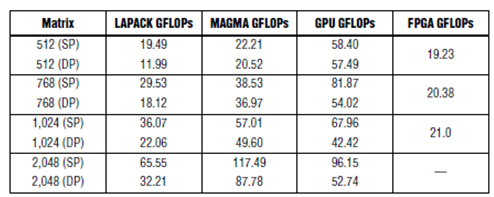
表1显示了基于Nvidia GPU指标1.35 TFLOP的基准测试结果,使用了各种库,以及Xilinx Virtex6 XC6VSX475T,其密度达到475K LC,这种FPGA针对DSP处理进行了优化。用于Cholesky基准测试时,这些器件在密度上与Altera FPGA相似。LAPACK和MAGMA是商用库,而GPU GFLOP则是采用田纳西州大学开发的OpenCL实现的(2)。对于小规模矩阵,后者更优化一些。
表1.GPU和Xilinx FPGA Cholesky基准测试 (2)
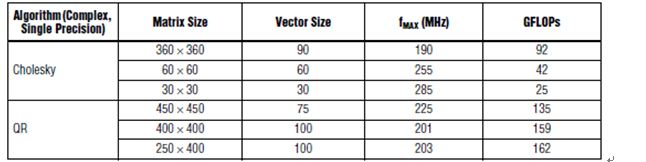
Altera测试了容量中等的Altera Stratix® V FPGA (460K逻辑单元(LE)),使用了单精度浮点处理的Cholesky算法。如表2所示,在Stratix V FPGA上进行Cholesky算法的性能要比Xilinx结果高很多。Altera基准测试还包括QR分解,这是不太复杂的另一矩阵处理算法。Altera以可参数赋值内核的形式提供Cholesky和QRD算法。
表2.Altera FPGA Cholesky和QR基准测试
应指出,基准测试的矩阵大小并不相同。田纳西州大学的结果来自[512 × 512]的矩阵,而Altera基准测试的Cholesky是[360x360],QRD则高达[450x450]。原因是,矩阵规模较小时,GPU效率非常低,因此,在这些应用中,不应该使用它们来加速CPU。作为对比,在规模较小的矩阵时,FPGA的工作效率非常高。雷达系统对吞吐量的要求很高,每秒数千个矩阵,因此,效率非常关键。采用了小矩阵,甚至要求把大矩阵分解成小矩阵以便进行处理。
而且,Altera基准测试是基于每个Cholesky内核的。每个可参数赋值的Cholesky内核支持选择矩阵大小,矢量大小和通道数量。矢量大小大致决定了FPGA资源。较大的[360 × 360]矩阵使用了较长的矢量,支持FPGA中实现一个内核,达到91 GFLOP。较小的[60 × 60]矩阵使用的资源更少,因此,可以实现两个内核,总共是2 × 42 = 84 GFLOP。最小的[30 × 30]矩阵支持实现三个内核,总共是3 × 25 = 75 GFLOP。
FPGA看起来更适合解决数据规模较小的问题,很多雷达系统都是这种情况。GPU之所以效率低,是因为计算负载随N3而增大,数据I/O随N2增大,最终,随着数据的增加,GPU的I/O瓶颈不再是问题。此外,随着矩阵规模的增大,由于每个矩阵的处理量增大,矩阵每秒吞吐量会大幅度下降。在某些点,吞吐量变得非常低,以至于无法满足雷达系统的实时要求。
对于FFT,计算负载增加至N log2 N,而数据I/O随N增大而增大。对于规模较大的数据,GPU是高效的计算引擎。作为对比,对于所有规模的数据,FPGA都是高效的计算引擎,更适合大部分雷达应用,这些应用中,FFT长度适中,但是吞吐量很大。

fpga相关文章:fpga是什么
锁相环相关文章:锁相环原理







评论