雷达信号处理:FPGA还是GPU?
为降低桶形移位频率,综合过程尽可能使用较大的尾数宽度,从而不需要频率归一化和去归一化。27 × 27和36 × 36硬核乘法器支持比单精度实现所要求的23位更大的乘法计算,54 × 54和72 × 72结构的乘法器支持比52位更大的双精度计算,这通常是双精度实现所要求的。FPGA逻辑已经针对大规模定点加法器电路进行了优化,包括了内置进位超前电路。
本文引用地址:http://www.eepw.com.cn/article/221498.htm当需要进行归一化和去归一化时,另一种可以避免低性能和过度布线的方法是使用乘法器。对于一个24位单精度尾数(包括符号位),24 × 24乘法器通过乘以2n对输入移位。27 × 27和36 × 36硬核乘法器支持单精度扩展尾数,可以用于构建双精度乘法器。
在很多线性代数算法中,矢量点乘是占用大量FLOP的底层运算。单精度实现长度是64的长矢量点乘需要64个浮点乘法器,以及随后由63个浮点加法器构成的加法树。这类实现需要很多桶形移位电路。
相反,可以对64个乘法器的输出进行去归一化,成为公共指数,最大是64位指数。可以使用定点加法器电路对这些64路输出求和,在加法树的最后进行最终的归一化。如图4所示,这一本地模块浮点处理过程省掉了每一加法器所需要的中间归一化和去归一化。即使是IEEE 754浮点处理,最大指数决定了最终的指数,因此,这种改变只是在计算早期进行指数调整。
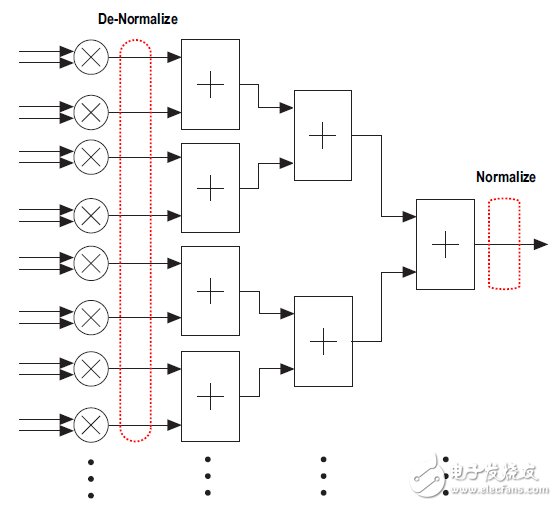
图4.矢量点乘优化
但进行信号处理时,在计算最后尽可能以高精度来截断结果才能获得最佳结果。这种方法传递除单精度浮点处理所需要尾数位宽之外的额外的尾数位宽,一般从27位到36位补偿了单精度浮点处理所需要的早期去归一化这种次优方法,。采用浮点乘法器进行尾数扩展,因此,在每一步消除了对乘积进行归一化的要求。
这一方法每个时钟周期也会产生一个结果。GPU体系结构可以并行产生所有浮点乘法,但不能高效并行进行加法。原因是因为不同的内核必须通过本地存储器传输数据实现通信,因此缺乏FPGA架构的连接的灵活特性。
融合数据通路方法产生的结果比传统IEEE 754浮点结果更加精确,如表3所示。
表3.Cholesky分解准确性(单精度)
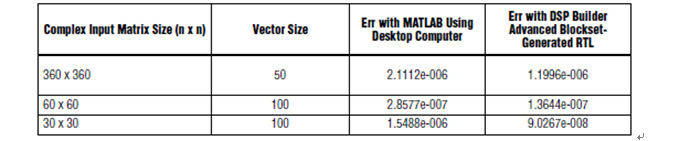
使用Cholesky分解算法,实现大规模矩阵求逆,获得了这些结果。相同的算法以三种不同的方法实现:
♦ 在MATLAB/Simulink中,采用IEEE 754单精度浮点处理。
♦ 在RTL单精度浮点处理中,使用融合数据通路方法。
♦ 在MATLAB中,采用双精度浮点处理。
双精度实现要比单精度实现精度高十亿倍(109)。
MATLAB单精度误差、RTL单精度误差和MATLAB双精度误差对比确认了融合数据通路方法的完整性。采用了这一方法来获得输出矩阵中所有复数元素的归一化误差以及矩阵元素的最大误差。使用Frobenius范数计算了总误差:
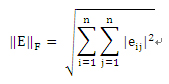
由于范数包括了所有元素的误差,因此比单一误差大很多。
此外,DSP Builder高级模块库和OpenCL工具流程都针对下一代FPGA体系结构,支持并优化目前的设计。由于体系结构创新和工艺技术创新,性能可以达到100峰值GFLOPs/W。
结论
高性能雷达系统现在有新的处理平台选择。除了更好的SWaP,与基于处理器的解决方案相比,FPGA能提供低延时和高GFLOP。随着下一代高性能计算优化FPGA的推出,这种优势会更明显。
Altera的OpenCL编译器为GPU编程人员提供了几乎无缝的通路来评估这一新处理体系结构的指标。Altera OpenCL符合1.2规范,提供全面的数学库支持。它解决了传统FPGA遇到的时序收敛、DDR存储器管理以及PCIe主处理器接口等难题。
对于非GPU开发人员,Altera提供DSP Builder高级模块库工具流程,支持开发人员开发高fMAX定点或浮点DSP设计,同时保持基于Mathworks的仿真和开发环境的优点。使用FPGA的雷达开发人员多年以来一直使用该产品,实现更高效的工作流程和仿真,其fMAX性能与手动编码HDL相同。

fpga相关文章:fpga是什么
锁相环相关文章:锁相环原理






评论