部署边缘检测AI与卡尔曼滤波,实现自锁与打嗝模式

1 滤波
卡尔曼滤波是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。它在信号处理、控制理论、导航等领域有着广泛应用。
1.1 核心思想与基本假设
核心思想:通过融合系统的动态模型(预测)和实际观测数据(校正),以递归方式估计系统状态,最小化估计误差的方差。
基本假设:系统是线性的(或可近似线性化)。噪声符合高斯分布(过程噪声和观测噪声均为白噪声)。初始状态的估计误差已知。
1.2 数学模型与递归过程
卡尔曼滤波基于两个关键方程:预测方程和校正方程,通过迭代更新实现最优估计。
1>状态空间模型
状态方程(系统动态模型):(x_k = A_kx_{k-1}+B_ku_k+w_k)其中:
(x_k)为k时刻的状态向量;
(A_k)为状态转移矩阵;
(u_k)为控制输入向量,(B_k)为控制矩阵;
(w_k)为过程噪声,服从高斯分布(w_k sim N(0,Q_k))。
观测方程(测量模型):(z_k = H_kx_k + v_k)其中:
(z_k)为观测向量;
(H_k)为观测矩阵;
(v_k)为观测噪声,服从高斯分布(v_k sim N(0,R_k))。
2> 递归过程(两个阶段)
阶段1:预测(时间更新)
状态预测:(hat{x}_{k|k-1} = A_khat{x}_{k-1|k-1} +B_ku_k)(基于前一时刻的最优估计预测当前状态)。
误差协方差预测:(P_{k|k-1} = A_kP_{k-1|k-1}A_k^T + Q_k)(预测当前状态估计的不确定性)。
阶段2:校正(测量更新)
卡尔曼增益计算:(K_k = P_{k|k-1}H_k^T(H_kP_{k|k-1}H_k^T + R_k)^{-1})(确定观测数据对状态估计的权重,平衡预测与观测的不确定性)。
状态更新:(hat{x}_{k|k} = hat{x}_{k|k-1} + K_k(z_k -H_khat{x}_{k|k-1}))(结合观测数据修正预测状态,得到最优估计)。误差协方差更新:(P_{k|k} = (I - K_kH_k)P_{k|k-1})(更新当前状态估计的不确定性,为下一时刻做准备)。
1.3 优势
1> 无需存储历史数据,仅需当前观测和前一时刻的估计,计算效率高,适合实时应用。
2> 可处理噪声统计特性已知的系统,通过调整噪声协方差矩阵(Q、R)适应不同场景。
1.4 使用
1> 添加程序,这里我放在了SOFTWARE 目录下,将其添加到路径下,与屏幕驱动引入相同,头文件引入等,这里不赘述。
2> 变量声明,首先需要声明变量,每个数据源设置一个变量,若使用一个,各个数据会相互影响,


3>初始化,将我们上一步声明的变量取地址,后面跟参数,

4>滤波,调用函数

代码如下




![]()
这个函数以用于多种单片机中,可自行移植尝试。
2 串口发送
这里和串口接收分开写,前期还用不到接收,就不写明。如果使用官方板卡建立工程,那么可以跳过第一步的cubemx 配置。
2.1 cubemx配置

使能串口2,设置为异步模式,其他保持默认,而后更新代码。
2.2 重映射到printf函数


2.3 滤波后发送到串口
将下列放置在while中,cureer为浮点数,请确保已经打开浮点数pritf。

3 VOFA简单配置
此时可以打开VOfa+进行数据收集选择当前对应端口号,串口,波特率115 200。


其他默认即可,按左上角按钮开启串口:

查看有无数据进入:

左侧选择第四项控件,第一个就是示波器。

拖动到右侧tab栏,右击全部填充。

再右击,如图将数据引入Y轴。

可以通过修改输入传入是否滤波,观察对比滤波前后的样子。

4 模型训练
完成上两部分准备工作后,我们就可以进行模型的训练了新建项目需要通过串口进行数据采集,简单介绍一下Nanoedge AI Studio是用于STM32部署边缘AI的软件,Studio可生成四种类型的库:异常检测、单分类、多分类、预测。
它支持所有类型的传感器,所生成的库不需要任何云连接,可以直接在本地学习与部署,支持STM32所有MCU系列。

意味着你可以将模型部署在任意的MCU,大小限制可以自行选择。
其他厂商的MCU不确定能否支持这里的模型。
正式开始前请先关闭VOfa+的串口连接。
4.1 新建模型训练工程
打开NanoEdge AI Studio,点击NEW PROJECT:

选择第一项,大意是使用设备学习检测信号中的异常使用模型识别数据中的异常模式。
该模型可以在学习阶段适应并逐步收集知识,以预测潜在的异常行为。
我们需要用到检测,选择这个即可:

设置工程名称,选择MCU或板卡等,数据类型选第二项Current电流:

4.2 信号采集
进入这个界面,上面是正常信号,下面是异常信号,配置方式相同。

以正常信号为例。

串行USB信号,文件导入和采集器。
我们刚刚使用串口发送电流信号,因此选择串行USB信号。

其他默认,如果你只想采集需要的数据条数,勾选最多数据限制。
确保你的电机正常运转,点击START开始。

采集完成导入数据。
完成后再进行异常信号采集。
需要注意一点,请将电机在故障状态下运行,例如负载过大限制转速等。
其他步骤与上述正常采集相同,这里不在赘述。
4.3 模型训练
选择左上角添加,打开如下界面,勾选正常与异常数据后开始训练。

整个过程相对较慢。

运行时主要使用CPU,设置中也没有GPU 的相关选项,此过程大概不需要显卡(截至2025 年5 月23 日5.02 版本)。笔者的配置如下:
13th Gen Intel(R) Core(TM)i9-13900H 加32G 内存
105 条正常信号,229 条异常信号。
总共用时两2 小时12 分25 秒。

先看一下跑完的样子,这是整个模型的参数,质量指数99.3 分,质量高还是很高的,准确率99.8%,占用RAM 0.1 kB,占用flash 1.9 kB。

这个是演变图,蓝色是质量指数,绿色是精准度,蓝色是RAM,红色是flash。
这里能实时且直观的展示整个模型训练的状态。

训练轨迹:

历史迭代:

还有其他图像这里就不展示了,如果你训练过yolo模型会发现这个过程的演变和迭代是很相似的。
4.4 模型测试与继续训练

这个过程可以继续对模型进行训练,也可以进行测试,模型训练结果我比较满意,就不继续训练了。
测试
点击本地运行:

先是对正常信号进行采集学习,确保电机正常工作后,点击开始:

采集足够的信号后,点击进行GO TO DETECTION转到检测:

整个过程很准确,效果如下:

4.5 获取模型与部署
按照如下勾选,我们是单模型,需要程序接口,数据类型是浮点数。
而后点击部署库:

将得到的压缩包解压后得到如下文件,主要用到这两个文件,一个是库,另一个是调用的API接口。


5 工程构建
5.1 文件配置
如图所示。这样放置是个人习惯,你也可以将它放置在任意顺眼的地方。

添加路径到源文件。

包含:

库路径。

库名称,命名为neai。

5.2 添加必要程序
参考生成伪代码:



引用头文件后和定义后,添加必要参数,写入缓存。

学习,这里我用OLED显示进行的过程,由于学习速度太快,我这里用了延时。

更新事件:

串口回传数据:
printf(“%d,%.2f,%.2f,%.2frn”,similarity,current,busVoltage,power);
整个工程框架构建完成。
详细过程请参考附件的工程。
6 加入中断接收
回到cubeMX,找到串口,使能串口中断。

重新生成后在while前添加开启中断。

重新定义中断回传函数,先判断是不是我们的串口2发送过来的,然后在里面写入我们的需求。



其中回传末尾重新开启中断:

![]()

![]()
串口结束与清除位数:


中断接收完成。
7 自锁模式与打嗝模式
以下是自锁模式与打嗝模式,请分别注释后使用。


其中switch_clocks 是全局变量,会根据中断接收到的字符进行更新,从而实现自锁或打嗝。
继电器函数定义


定义的继电器GPIO。
(本文来源于《EEPW》202508)

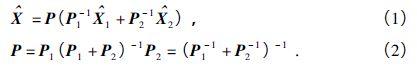
评论