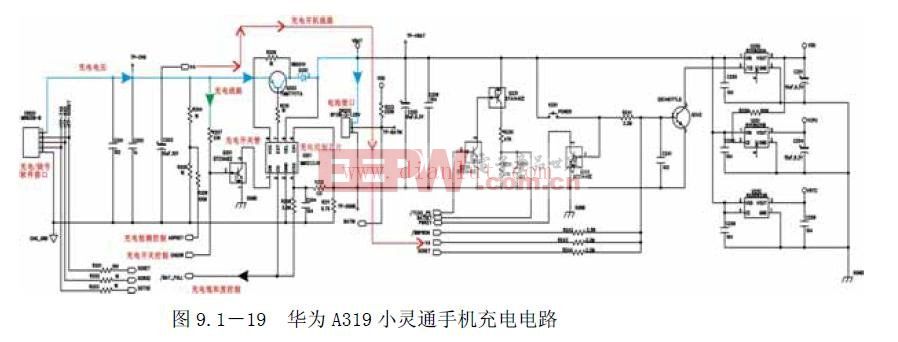
华为首次线下展出昇腾384超节点

7月26日,2025世界人工智能大会(WAIC)在上海世博中心启幕,华为首次线下展出昇腾384超节点,即Atlas 900 A3 SuperPoD。具体性能上,昇腾384超节点单集群BF16稠密算力300PFLOPs,约为英伟达GB200 NVL72的1.7倍。

据介绍,该产品基于超节点架构,采用全对等(Peer-to-Peer)UB总线,将384颗NPU+192颗鲲鹏CPU通过无阻塞Clos架构互联,单跳时延<200ns,带宽392GB/s,比传统RoCE提升15倍。3168根光纤+6912个400G光模块实现百纳秒级互联,支持2m以上长距部署,突破了铜缆距离限制。
这些大带宽低时延互联技术,解决了昇腾384超节点集群内计算、存储等各资源之间的通信瓶颈,通过系统工程的优化,实现资源的高效调度 —— 能效比(MFU)从行业平均30%提升到45%以上,已用于训练7180亿参数的盘古Ultra MoE大模型。
值得一提的是,在今年5月的鲲鹏昇腾开发者大会上,华为推出了昇腾超节点(CloudMatrix 384),成功实现业界最大规模的384卡高速总线互联。华为表示CloudMatrix 384超节点算力集群可实现业界最大单卡推理吞吐量2300Tokens/s,业界最大集群算力6万卡。

据国际知名半导体研究和咨询机构SemiAnalysis披露,华为云CM384基于384颗昇腾芯片构建,通过全互连拓扑架构实现芯片间高效协同,可提供高达300PFLOPs的密集BF16算力,接近达到英伟达GB200 NVL72系统的两倍。此外,CM384在内存容量和带宽方面同样占据优势,总内存容量超出英伟达方案3.6倍,内存带宽也达到2.1倍,为大规模AI训练和推理提供了更高效的硬件支持。华为云表示,新一代昇腾AI云服务,是最适合大模型应用的算力服务。
华为云最新推出的AI算力集群解决方案CloudMatrix 384凭借其颠覆性的系统架构设计与全栈技术创新,在多项关键指标上实现对英伟达旗舰产品GB200 NVL72的超越,标志着中国在人工智能基础设施领域实现里程碑式突破。SemiAnalysis还特别指出,华为的规模化解决方案“领先于英伟达和AMD目前市场上的产品一代”,并认为中国在AI基础设施上的突破将对全球AI产业格局产生深远影响。



评论