什么是HPC内存墙,如何跨越它?

高性能计算 (HPC) 内存墙通常是指处理器速度和内存带宽之间不断扩大的差距。当处理器性能超过内存访问速度时,这会在整体系统性能中造成瓶颈,尤其是在人工智能 (AI) 等内存密集型应用程序中。
本文引用地址:https://www.eepw.com.cn/article/202505/470860.htm本文首先探讨了内存墙的传统定义,然后着眼于另一种观点,该视图将内存容量与 AI 模型中参数数量的增长进行比较。无论从哪个定义来看,记忆墙已经到来,这是一个严重的问题。它以一些翻越墙壁或至少降低墙壁高度的技术结束。
当然,HPC 的定义正在不断发展。几年前被认为是 HPC 的东西不再符合最新的定义。根据处理器在峰值每秒浮点运算数 (FLOP) 与内存带宽方面的性能比较,这个问题已经存在了 25 年多(图 1)。虽然内存性能显著提高,但访问和传输数据的能力并没有跟上数据处理者的能力。
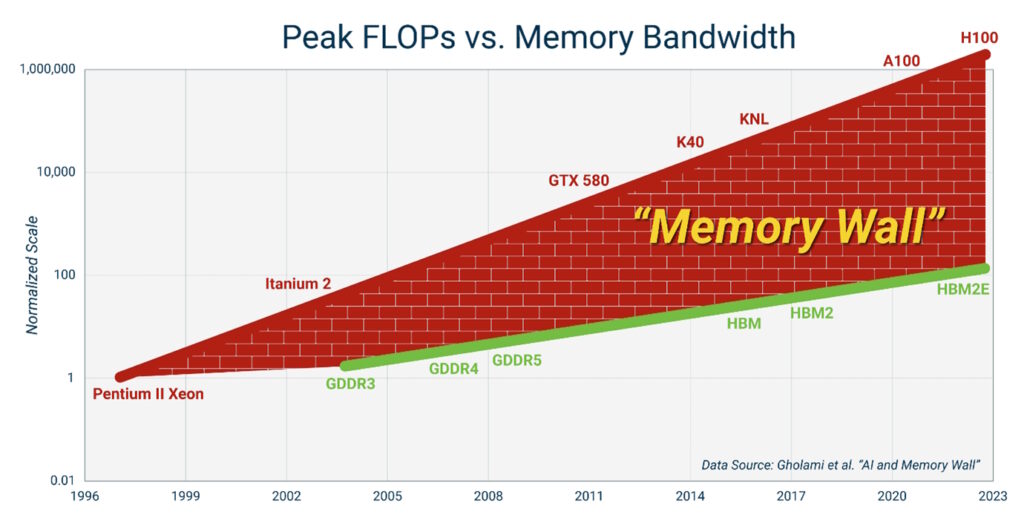 图 1.HPC 内存墙是处理器性能和内存带宽之间的差距。(图片:Astera Labs))
图 1.HPC 内存墙是处理器性能和内存带宽之间的差距。(图片:Astera Labs))
由于内存壁,处理器在等待内存上花费的时间越来越多。这意味着无法使用昂贵的高性能处理器的某些功能。在涉及大型数据库和复杂计算的 HPC 应用程序中,这可能是一个严重的问题。
AI 视角
HPC 是 AI 的重要工具,尤其是用于训练 AI 模型。当 AI 在 2015 年左右出现时,典型模型中的参数数量相对较少。它不需要最高的 HPC 性能,因此其他应用程序遇到的内存墙不是问题。
这种情况在 2019 年左右发生了变化,因为 AI 模型复杂性的快速增加超过了处理器性能的提高(图 2)。在随后的几年里,AI 应用的内存墙高度持续增长,并可能成为 AI 性能进一步进步的限制因素。AI 的重要性日益增加,这增加了处理 HPC 内存墙的紧迫性。
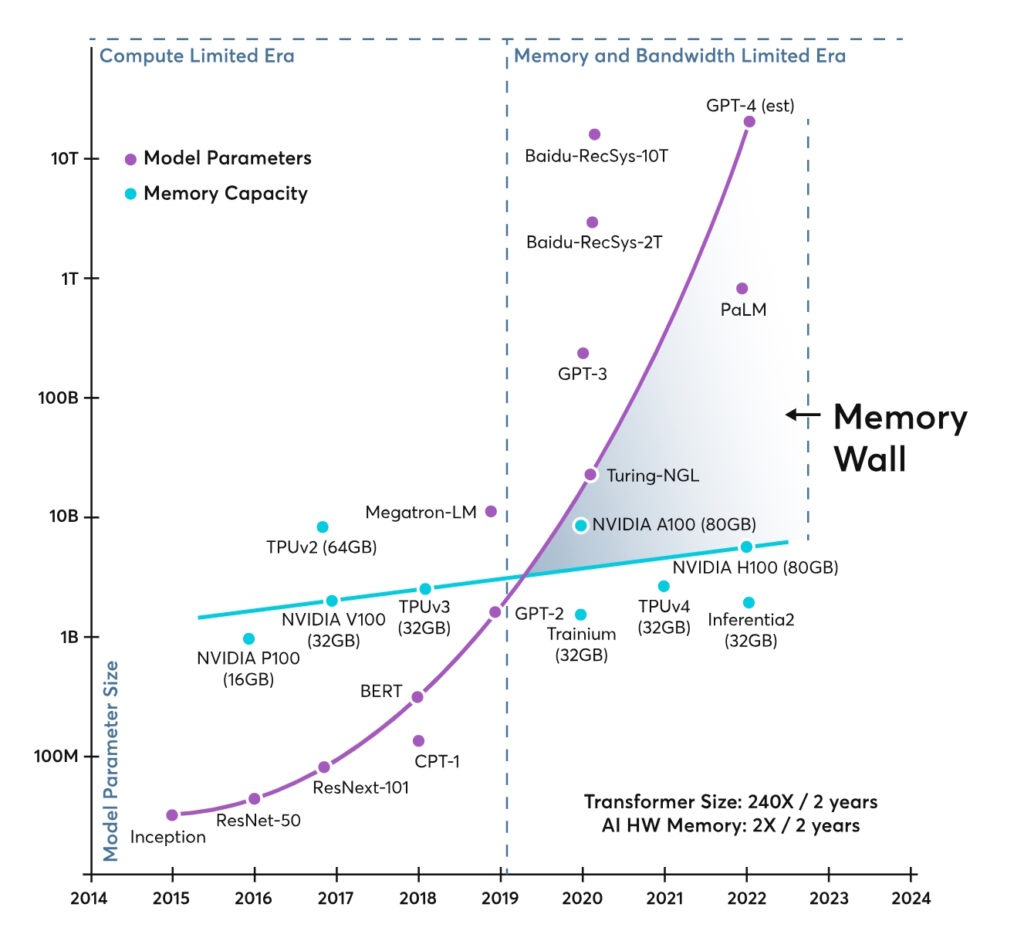 图 2.HPC 内存墙也可以从 AI 模型日益复杂的角度来看待。(图片:Ayar Labs))
图 2.HPC 内存墙也可以从 AI 模型日益复杂的角度来看待。(图片:Ayar Labs))
降低墙体高度
如上图 1 所示,多代图形双倍数据速率 (GDDR) 和高带宽内存 (HBM) 技术只是减缓了内存墙的增长速度,但并没有解决问题。
还使用了几种内存管理方法,包括多级分层缓存,其中常用数据存储在更靠近处理器的位置,以及预取指令,通过减少访问主内存的需求来提高性能。
最大化内存使用的优化算法也有助于减轻内存墙的影响。构建数据以更有效地使用可以最大限度地减少缓存未命中并提高性能。
最近的发展不是原始内存性能的改进,而是专注于新的计算和内存架构来扩展墙。
新架构方法的示例包括内存计算 (CIM),也称为内存处理 (PIM) 和内存计算 (IMC)。CIM 是一种基于硬件的架构,可直接在内存存储中执行计算。这减少了对数据传输的需求并加快了计算速度。
IMC 是一种硬件和软件方法。数据在 RAM 中处理以提高性能,并且可以利用多个内核和并行处理。CIM 和 IMC 可以从本地内存计算扩展 (CXL) 标准中受益。
用 CXL 征服墙壁
CXL 附加内存通过实现高效的内存共享和扩展多个处理器可用的内存容量和带宽来解决 HPC 内存壁问题。它利用 PCIe 物理层提供低延迟和高带宽通信,促进 CPU 和附加内存之间的高效数据传输。
CXL 确保内存访问是一致的,并且所有处理器都具有一致的内存视图,从而简化了内存管理。它为更高效的内存使用提供了结构和工具,帮助 HPC 系统克服了内存墙挑战。
总结
虽然 HPC 内存墙通常是指提高处理器速度和滞后内存带宽之间不断扩大的差距,但它也可以相对于 AI 模型日益复杂来定义。无论从哪个定义来看,它都在增长,并且是一个越来越严峻的挑战。设计人员可以使用多种工具来扩展或降低 HPC 内存墙的高度。



评论