中国芯片与摩尔定律

本周二,拜登政府收紧了对销往中国的先进人工智能(AI)芯片的出口管制;主要目标是英伟达(Nvidia)的 H800 和 A800 芯片,这些芯片是专门为规避去年实施的控制而设计的。H800/A800 和 H100/A100 之间的主要区别在于它们的通信带宽:A100 具有 600 Gb/s 的速度(H100 具有 900GB/s),这恰好是去年出口管制所禁止的限制,A800 和 H800 的通信速度仅限于 400 Gb/s。
本文引用地址:https://www.eepw.com.cn/article/202310/451870.htm通信速度之所以重要,与 Nvidia 首席执行官黄仁勋 (Jensen Huang) 的论点「摩尔定律已死」有关。摩尔定律最初于 1965 年提出,指出集成电路中晶体管的数量每年都会增加一倍。十年后,戈登·摩尔将他的预测修正为每两年翻一番,直到过去十年左右,这一预测才放缓至大约每三年翻一番。
但在实践中,摩尔定律已经变得更类似于科技行业的基本法则:随着时间的推移,计算能力将会增加,而且会变得更便宜。这一原则与戈登·摩尔的技术预测相关:较小的晶体管可以更快地切换,并且在切换时使用更少的能量,即使更多的晶体管可以集成在单个晶圆上;这意味着您可以在每个晶圆上获得更多芯片或更大的芯片,从而降低价格或以相同的价格提高功率。在实践中我们两者都得到了。
至关重要的是,科技行业的其它公司不需要了解摩尔定律的技术或经济细节:60 年来,简单地假设计算机会变得更快是安全的,这意味着最佳方法始终是专为尖端或超越而构建,并相信处理器速度能够赶上您的使用案例。
摩尔定律终结?
近几年,英伟达首席执行官黄仁勋一再宣称摩尔定律已死。从技术角度来看,速度确实放缓了,但密度在持续增加。以下是台积电按制程节点尺寸划分的晶体管密度,以每个节点尺寸的第一代工艺为例。
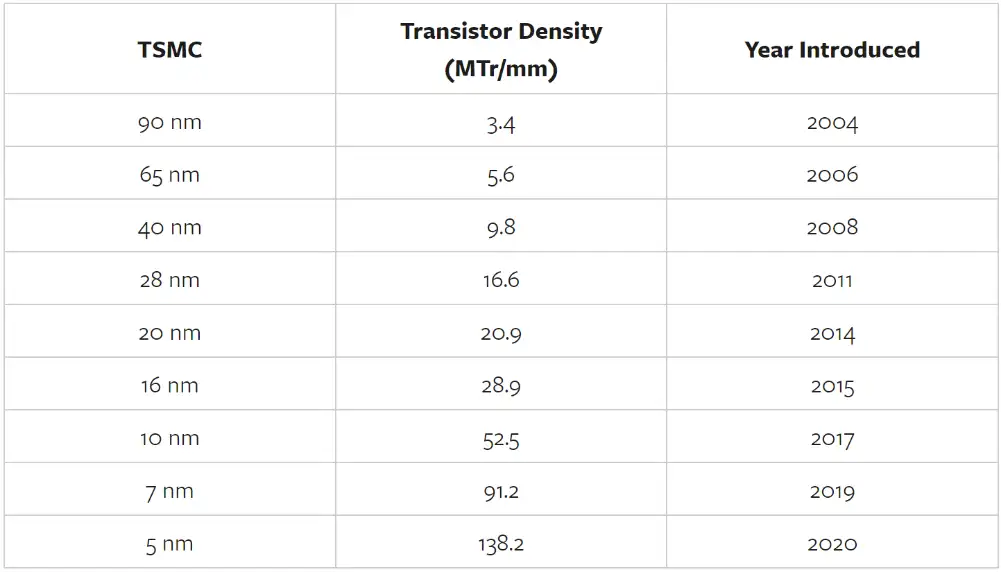
请记住,成本很重要,以下是台积电每晶圆介绍价格的同一张表,以及每十亿个晶体管的价格:
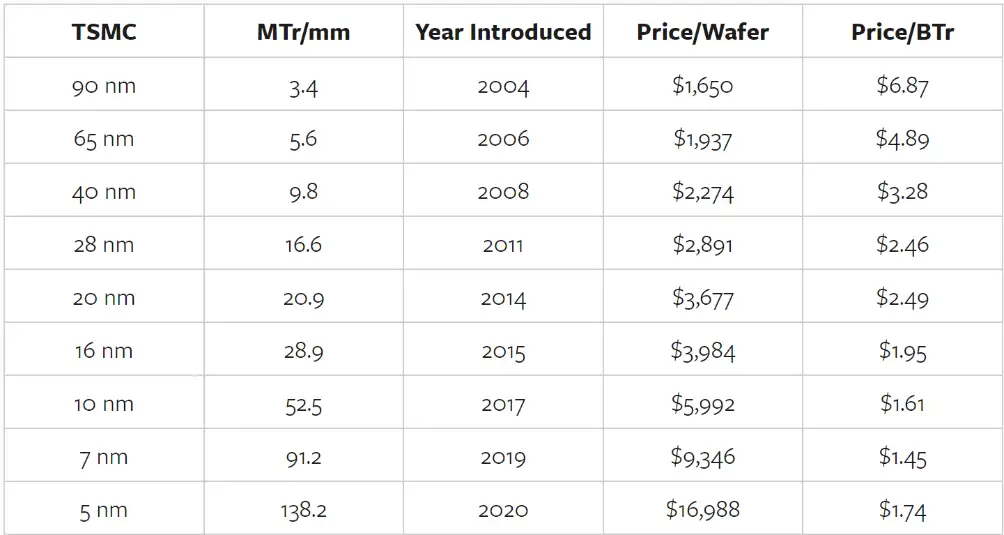
请注意右下角的数字:采用台积电的 5 nm 工艺,每个晶体管的价格上涨了,而且上涨了很多 (20%)。原因很明显:5nm 是第一个需要 ASML 极紫外 (EUV) 光刻技术的工艺,而 EUV 机器非常昂贵——每台约 1.5 亿美元。换句话说,虽然摩尔定律的技术定义将继续存在,但芯片总是变得更快、更便宜的原则却不会继续存在。
GPU 和令人尴尬的并行性
需要明确的是,黄仁勋的论点并不仅仅基于 5nm 芯片的成本,摩尔定律涉及速度和成本,而事实是,随着能源成为从移动设备到个人电脑再到数据中心的所有设备的限制,许多密度增益主要用于提高电源效率。黄仁勋多年来的论点是,Nvidia 拥有提高计算速度的解决方案:使用 GPU。
GPU 比 CPU 简单得多;这意味着它们可以更快地执行指令,但这些指令必须更简单,可以同时运行许多它们以获得巨大的结果。不出所料,图形是最明显的例子:每个「着色器」——GPU 的主要处理组件——计算将在屏幕的单个部分上显示的内容,该部分的大小是可用着色器数量的函数。如果您有 1024 个着色器,则每个着色器绘制屏幕的 1/1024。因此,如果您有 2048 个着色器,则绘制屏幕的速度可以提高两倍。图形性能是「令人尴尬的并行」,也就是说它随着解决问题的处理器数量而变化。
这种「令人尴尬的并行性」是 GPU 相对于 CPU 具有超强性能的关键,但挑战在于并非所有软件问题都可以轻松并行化;Nvidia 的 CUDA 生态系统旨在提供工具来构建可以利用 GPU 并行性的软件应用程序,并且是巩固 Nvidia 主导地位的主要护城河之一,但大多数软件应用程序仍然需要 CPU 才能运行。
事实证明,无论是在训练模型还是在推理模型方面,人工智能都是一个令人尴尬的并行应用程序。此外,最佳的可扩展性远远超出了计算机显示器显示图形的范围。这就是为什么 Nvidia AI 芯片具有芯片禁令所提到的高速互连功能:AI 应用程序同时在多个 AI 芯片上运行,但确保这些 GPU 繁忙的关键是向它们提供数据,而这需要那些高速互连。
话虽如此,我对传统数据中心应用程序大规模转向 GPU 持怀疑态度。
基于 CPU 的应用程序不仅更容易开发,而且大多已经构建完成。我很难想象哪些公司会花费时间和精力将已经在 CPU 上运行的东西移植到 GPU 上;归根结底,在云中运行的应用程序是由提供云资源需求的客户决定的,而不是寻求优化 FLOP/rack 的云提供商。
认为传统 CPU 仍有一定生命力的另一个原因是:事实证明摩尔定律可能又回到了正轨。
EUV 和摩尔定律
上文所示表格只跑到 5nm,iPhone 15 Pro 采用的是 N3 芯片,以下为相应的价格/晶体管表。
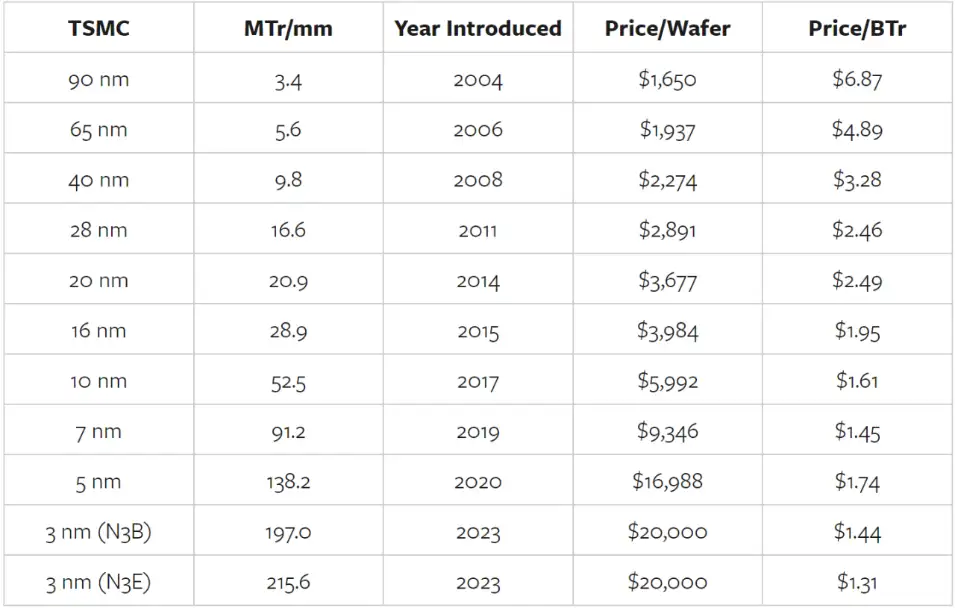
虽然我之前只给出了每个节点的第一个版本,但用于 iPhone A17 Pro 芯片的 N3B 工艺是一个死胡同;台积电改变了 N3E 的做法,这将成为未来 N3 系列的基础。这也使得 N3 在每晶体管价格方面的飞跃更加令人印象深刻:N3B 消除了 5nm 的倒退,N3E 比 7nm 有了显著的改进。
此外,EUV 机器成本很高,但摩尔定律中的价格下降并不是设备变得更便宜的结果。请注意,每片晶圆的价格一直在不断上涨。相反,不断下降的价格/晶体管是摩尔定律的函数,也就是说,EUV 等新设备让我们「将更多元件填充到集成电路上」。
5nm 发生的情况与 20nm 每晶体管价格上涨的情况类似:那是台积电开始使用双图案化的节点,这意味着他们必须将每个光刻步骤进行两次;这既使每片晶圆的光刻设备利用率增加了一倍,同时也降低了产量。至少对于该节点来说,制造更小的晶体管所带来的收益超过了成本。然而一年后,台积电推出了 16nm 节点。这正是 3nm 所发生的情况——EUV 的收益现在明显超过成本——而有关 2nm 密度和价格点的早期传言表明,另一个节点的收益应该会持续下去。
芯片禁令
考虑到华盛顿特区对华为最近推出的配备 7nm 芯片的智能手机感到焦虑,这似乎是对出口管制的蔑视。
简而言之,芯片禁令的问题在于在 10nm 上划定界限:这条界限是任意的,因为制造 10 nm 芯片所需的设备已经被证明能够生产 7 nm 芯片。
真正重要的是 5nm,换句话说,真正限制中国大陆长期发展的出口管制是 EUV。前些年,特朗普政府已经说服荷兰不允许出口 EUV 设备,拜登政府通过芯片禁令以及与荷兰的进一步协调进一步锁定了 EUV 的出口。现实情况是,很多芯片制造设备都是「多节点」的;许多机器可以在多个节点上使用,但您必须拥有 EUV 设备才能延续摩尔定律,因为它是驱动摩尔定律的关键技术。
H800 是台积电第三代 5nm 工艺(容易混淆的 N4)制造的,也就是说它是用 EUV 制造的;通信速度限制是有意义的,并且会使人工智能开发速度更慢、成本更高。
这引出了进一步的观点:芯片禁令的回报不会立即显现。整个想法有意义的唯一方法是摩尔定律是否继续存在,因为这意味着五年或十年后可用的芯片将比现在存在的芯片更快、更便宜,从而扩大差距。同时,这个想法也取决于认真对待黄的论点,因为人工智能不仅需要力量,还需要规模。幸运的是,两条战线的进展都朝着正确的方向发展。
反对芯片禁令也存在很好的论据,包括一个明显的事实,即中国大陆受到强烈激励从头开始建立替代品。也许在 20 年内,美国不仅会失去最有力的杠杆点,而且还将看到其最前沿的公司被中国的竞争削弱。

评论