基于联合损失函数的语音增强深度学习算法

DNN 根据获取的语音特征对学习目标参数进行准确估计,目前已被广泛应用于语音增强的研究中[1-2]。各类声学特征也对语音增强方面存在差异。根据传统语音特征进行分析并不能充分反馈语音内部信息,也不能获得音帧和帧快速转换的结果,因此该模型并不能准确预测时频掩蔽结果,导致实际语音增强性能较差[3-4]。在背景噪声滤除方面,时频掩模值发挥着关键作用,以常规时频掩模值进行处理时并未针对语音相位进行分析,语音相位谱则对改善语音可懂性具有关键作用[5]。
本文引用地址:https://www.eepw.com.cn/article/202307/448398.htm根据上述研究结果,本文优化了以语音增强实现的网络模型与损失函数[6]。为确保代价函数能够根据人耳感知特点开展分析过程,在上述基础上设计了一种联合损失函数。针对损失函数计算过程加入关于人耳听觉的数据。
1 联合损失函数
进行深度学习时,需要利用均方误差损失函数(MSE)对神经网络实施优化处理,而MSE 只对增强语音与纯净语音误差进行简单数据分析,并未考虑误差正负因素的影响,也未加入人耳感知的信号。此时只以MSE 构建损失函数不能确保增强语音达到理想的算法处理效果[7]。
采用频域加权分段的信噪分析方法可以对语音可懂度进行预测。以下为频域加权分段信噪比表达式:

(1)
式中,L 表示时频信号帧数,K 表示频带数,x(I,k)是第 l 帧第 k 个频带中包含的纯净语音信号幅度, 属于第 l 帧第 k 个频带包含噪声语音的幅度谱,W(I,k)为作用于各时频单元幅度谱的感知权重系数。
属于第 l 帧第 k 个频带包含噪声语音的幅度谱,W(I,k)为作用于各时频单元幅度谱的感知权重系数。
本文从语音信噪比特征出发,对以上函数实施动态结合,由此得到联合优化代价函数。建立了动态系数:
a(I,k)=![]() (2)
(2)
上述系数与时频单元信噪比存在直接关联,SNR(l,k) 表示第l 帧第k 个频带对应的信噪比数据,同时根据各时频单元信噪比获得相应的动态系数,处于较高信噪比条件下时,动态系数接近1。
在联合代价函数中融合了人耳心理声学感知的内容[8],以此训练网络来实现性能优化的目标,在确保提升话音质量的前提下使增强话音具备更高可懂度。
2 基于联合损失函数的语音增强算法
以联合损失函数建立语音增强算法经多次重复训练后,能够从含噪语音幅度谱内获得估计增强语音幅度谱。图1给出了系统框图。

图1 基于联合损失函数的语音增强算法系统框图
时频掩蔽因素是对神经网络产生影响而引起语音增强性能差异的重要条件,采用传统学习方法进行处理时只需对语音幅度进行分析。确定混合特征参数与学习目标后,再对神经网络开展输入、输出训练,同时利用最小均方误差优化网络算法。再以BP 算法反向传递方式完成网络参数的修正。从每次训练的结果中选择最优性能的网络模型进行记录后建立测试网络模型。
本文选择联合损失函数对两者差异进行评价,记录最优性能的网络模型参数。进行测试时,先将含噪语音幅度谱加入经过训练的模型内,之后通过模型对增强语音幅度谱进行预测,最后以语音相位参数完成信号重构。
3 实验结果分析
3.1 实验数据的选取
以上语音数据都是由IEEE 语音数据库提供,之后从NOISEX-92 噪声库内提取Pink、Factory 与White 三种噪声信号,这些信号保持一致频率。按照同样信噪比把剩余50 条纯净语音与噪声后半段进行混合后建立测试集。
本文设定语音频率为16 kHz,并以语音幅度谱作为输入语音特征。各项网络参数见表1。

3.2 对比实验分析
为了对本文建立的联合损失函数与自注意力机制进行有效性验证,构建得到表2 的对比算法。

从表3~5 中可以看到各噪声条件下的PESQ 值。其中,表3 显示,信噪比等于-5dB 的情况下,根据算法1 与2 测试结果可以发现,在各类噪声条件下,PESQ值提升均值达到0.13,同时STOI 值提升了0.01 的均值水平。比较算法2 与3 可以发现,PESQ 值提升了0.07,STOI 提升了0.01。

表4 显示,带噪语音信噪比等于0 dB 的条件下,根据算法1 与2 可以发现,各噪声下的PESQ 值都提升了0.11,此时STOI 值提升0.02。比较算法2 与3 可以发现,PESQ 值提升0.09,STOI 提升0.01。

表5 显示,带噪语音信噪比等于5 dB 的情况下,比较算法1 与2 可以发现,各噪声下的PESQ 值提升达到0.13 的均值,STOI 值提升了0.01。根据算法2 与3的比较结果可知,PESQ 值提升0.07,STOI 提升0.01。

综合分析表3~5 得到下述结果:
1)通过对比算法1 与2 测试结果得到:当噪声与信噪比都不同的情况下,以联合损失函数实现的增强语音PESQ 值提高0.12,STOI 提高0.01。根据算法1 与2 可知,本文设计的混合损失函数实现增强语音质量的明显优化。
2)对比算法2 与3 结果可以发现,为神经网络模型设置注意力机制后,可以使增强语音PESQ 值提高0.08,STOI 提高0.01。同时根据算法2 与3 结果可以推断,加入注意力机制后能够促进背景噪音的进一步减弱,从而获得更高可懂度。
3)比较算法1 与3 结果可知:以联合损失函数对神经网络开展训练时,同时加入自注意力机制来分析理神经网络特征的情况下能够实现增强语音质量的显著改善,此时PESQ 值提升0.2,STOI 提升0.03。
4 结束语
1)本文设计的混合损失函数实现增强语音质量的明显优化。加入注意力机制后能够促进背景噪音的进一步减弱,从而获得更高可懂度。
2)综合运用联合损失函数并融合注意力机制后,可以使神经网络获得更优质量增强语音。利用注意力机制提取特征参数以及结合联合损失函数进行神经网络优化能够促进增强语音质量的提升并达到更高的可懂度。
参考文献:
[1] BABY D, VIRTANEN T, GEMMEKE J F. Coupled dictionaries for exemplar-based speech enhancement and automatic speech recognition[J]. IEEE-ACM transactions on audio, speech, and language processing, 2015, 23(11):1788-1799.
[2] LI C X, DU Y J, WANG S D. Mining implicit intention using attention-based rnn encoder-decoder model[C]// International conference on intelligent computing. Springer, Cham, 2017: 413-424.
[3] 葛宛营,张天骐.基于掩蔽估计与优化的单通道语音增强算法[J].计算机应用,2019, 39(10): 6.
[4] 鲍长春,项扬.基于深度神经网络的单通道语音增强方法回顾[J].信号处理,2019,35(12): 11.
[5] GLOROT X, BENGIO Y. Understanding the difficulty of training deep feed forward neural networks[C]. Proceedings of the thirteenth international conference on artificial intelligence and statistics, Sardinia, Italy, 2010, 5: 249-256.
[6] MARTIN-DONAS J M, GOMEZ A M, Gonzalez J A, et al. A deep learning loss function based on the perceptual evaluation of the speech quality[J]. IEEE Signal processing letters,2018, 25(11):1680-1684.
[7] 李鸿燕,屈俊玲,张雪英.基于信号能量的浊语音盲信号分离算法[J].吉林大学学报(工学版),2015,(5): 6.
[8] 戴红霞,唐於烽,赵力.基于维纳滤波与理想二值掩蔽的数字助听器语音增强算法[J].电子器件,2019,42(4): 4.
(本文来源于《电子产品世界》杂志2023年6月期)

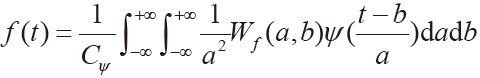


评论