国内外语音识别技术发展现状探讨

语音识别的意思是将人说话的内容和意思转换为计算机可读的输入,例如按键、二进制编码或者字符序列等。与说话人的识别不同,后者主要是识别和确认发出语音的人而非其中所包含的内容。语音识别的目的就是让机器听懂人类口述的语言,包括了两方面的含义:第一是逐字逐句听懂而不是转化成书面的语言文字;第二是对口述语言中所包含的命令或请求加以领会,做出正确回应,而不仅仅只是拘泥于所有词汇的正确转换。
本文引用地址:https://www.eepw.com.cn/article/201610/311278.htm自从1952年,AT&TBell实验室的Davis等人研制了第一个可十个英文数字的特定人语音增强系统一Audry系统1956年,美国普林斯顿大学RCA实验室的Olson和Belar等人研制出能10个单音节词的系统,该系统采用带通滤波器组获得的频谱参数作为语音增强特征。1959年,Fry和Denes等人尝试构建音素器来4个元音和9个辅音,并采用频谱分析和模式匹配进行决策。这就大大提高了语音识别的效率和准确度。从此计算机语音识别的受到了各国科研人员的重视并开始进入语音识别的研究。60年代,苏联的MaTIn等提出了语音结束点的端点检测,使语音识别水平明显上升;Vintsyuk提出了动态编程,这一提法在以后的识别中不可或缺。60年代末、70年代初的重要成果是提出了信号线性预测编码(LPC)技术和动态时间规整(DTW)技术,有效地解决了语音信号的特征提取和不等长语音匹配问题;同时提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。语音识别技术与语音合成技术结合使人们能够摆脱键盘的束缚,取而代之的是以语音输入这样便于使用的、自然的、人性化的输入方式,它正逐步成为信息技术中人机接口的关键技术。
一:语音识别技术发展现状-语音识别系统的分类
语音识别系统可以根据对输入语音的限制加以分类。如果从说话者与识别系统的相关性考虑,可以将识别系统分为三类:
(1)特定人语音识别系统。仅考虑对于专人的话音进行识别。
(2)非特定人语音系统。识别的语音与人无关,通常要用大量不同人的语音数据库对识别系统进行学习。
(3)多人的识别系统。通常能识别一组人的语音,或者成为特定组语音识别系统,该系统仅要求对要识别的那组人的语音进行训练。
如果从说话的方式考虑,也可以将识别系统分为三类:
(1)孤立词语音识别系统。孤立词识别系统要求输入每个词后要停顿。
(2)连接词语音识别系统。连接词输入系统要求对每个词都清楚发音,一些连音现象开始出现。
(3)连续语音识别系统。连续语音输入是自然流利的连续语音输入,大量连音和变音会出现。
如果从识别系统的词汇量大小考虑,也可以将识别系统分为三类:
(1)小词汇量语音识别系统。通常包括几十个词的语音识别系统。
(2)中等词汇量的语音识别系统。通常包括几百个词到上千个词的识别系统。
(3)大词汇量语音识别系统。通常包括几千到几万个词的语音识别系统。随着计算机与数字信号处理器运算能力以及识别系统精度的提高,识别系统根据词汇量大小进行分类也不断进行变化。目前是中等词汇量的识别系统,将来可能就是小词汇量的语音识别系统。这些不同的限制也确定了语音识别系统的困难度。
二:语音识别技术发展现状-语音识别的方法汇总分析
目前具有代表性的语音识别方法主要有动态时间规整技术(DTW)、隐马尔可夫模型(HMM)、矢量量化(VQ)、人工神经网络(ANN)、支持向量机(SVM)等方法。
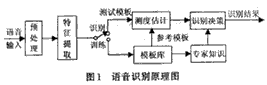
动态时间规整算法(Dynamic TIme Warping,DTW)是在非特定人语音识别中一种简单有效的方法,该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别技术中出现较早、较常用的一种算法。在应用DTW算法进行语音识别时,就是将已经预处理和分帧过的语音测试信号和参考语音模板进行比较以获取他们之间的相似度,按照某种距离测度得出两模板间的相似程度并选择最佳路径。
隐马尔可夫模型(HMM)是语音信号处理中的一种统计模型,是由Markov链演变来的,所以它是基于参数模型的统计识别方法。由于其模式库是通过反复训练形成的与训练输出信号吻合概率最大的最佳模型参数而不是预先储存好的模式样本,且其识别过程中运用待识别语音序列与HMM参数之间的似然概率达到最大值所对应的最佳状态序列作为识别输出,因此是较理想的语音识别模型。
矢量量化(Vector QuanTIzaTIon)是一种重要的信号压缩方法。与HMM相比,矢量量化主要适用于小词汇量、孤立词的语音识别中。其过程是将若干个语音信号波形或特征参数的标量数据组成一个矢量在多维空间进行整体量化。把矢量空间分成若干个小区域,每个小区域寻找一个代表矢量,量化时落入小区域的矢量就用这个代表矢量代替。矢量量化器的设计就是从大量信号样本中训练出好的码书,从实际效果出发寻找到好的失真测度定义公式,设计出最佳的矢量量化系统,用最少的搜索和计算失真的运算量实现最大可能的平均信噪比。
在实际的应用过程中,人们还研究了多种降低复杂度的方法,包括无记忆的矢量量化、有记忆的矢量量化和模糊矢量量化方法。
人工神经网络(ANN)是20世纪80年代末期提出的一种新的语音识别方法。其本质上是一个自适应非线性动力学系统,模拟了人类神经活动的原理,具有自适应性、并行性、鲁棒性、容错性和学习特性,其强大的分类能力和输入—输出映射能力在语音识别中都很有吸引力。其方法是模拟人脑思维机制的工程模型,它与HMM正好相反,其分类决策能力和对不确定信息的描述能力得到举世公认,但它对动态时间信号的描述能力尚不尽如人意,通常MLP分类器只能解决静态模式分类问题,并不涉及时间序列的处理。尽管学者们提出了许多含反馈的结构,但它们仍不足以刻画诸如语音信号这种时间序列的动态特性。由于ANN不能很好地描述语音信号的时间动态特性,所以常把ANN与传统识别方法结合,分别利用各自优点来进行语音识别而克服HMM和ANN各自的缺点。近年来结合神经网络和隐含马尔可夫模型的识别算法研究取得了显著进展,其识别率已经接近隐含马尔可夫模型的识别系统,进一步提高了语音识别的鲁棒性和准确率。
支持向量机(Support vector machine)是应用统计学理论的一种新的学习机模型,采用结构风险最小化原理(Structural Risk Minimization,SRM),有效克服了传统经验风险最小化方法的缺点。兼顾训练误差和泛化能力,在解决小样本、非线性及高维模式识别方面有许多优越的性能,已经被广泛地应用到模式识别领域。
三:语音识别技术发展现状-国外研究
语音识别的研究工作可以追溯到20世纪50年代AT&T贝尔实验室的Audry系统,它是第一个可以识别十个英文数字的语音识别系统。
但真正取得实质性进展,并将其作为一个重要的课题开展研究则是在60年代末70年代初。这首先是因为计算机技术的发展为语音识别的实现提供了硬件和软件的可能,更重要的是语音信号线性预测编码(LPC)技术和动态时间规整(DTW)技术的提出,有效的解决了语音信号的特征提取和不等长匹配问题。这一时期的语音识别主要基于模板匹配原理,研究的领域局限在特定人,小词汇表的孤立词识别,实现了基于线性预测倒谱和DTW技术的特定人孤立词语音识别系统;同时提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。
随着应用领域的扩大,小词汇表、特定人、孤立词等这些对语音识别的约束条件需要放宽,与此同时也带来了许多新的问题:第一,词汇表的扩大使得模板的选取和建立发生困难;第二,连续语音中,各个音素、音节以及词之间没有明显的边界,各个发音单位存在受上下文强烈影响的协同发音(Co-articulation)现象;第三,非特定人识别时,不同的人说相同的话相应的声学特征有很大的差异,即使相同的人在不同的时间、生理、心理状态下,说同样内容的话也会有很大的差异;第四,识别的语音中有背景噪声或其他干扰。因此原有的模板匹配方法已不再适用。
实验室语音识别研究的巨大突破产生于20世纪80年代末:人们终于在实验室突破了大词汇量、连续语音和非特定人这三大障碍,第一次把这三个特性都集成在一个系统中,比较典型的是卡耐基梅隆大学(CarnegieMellonUniversity)的Sphinx系统,它是第一个高性能的非特定人、大词汇量连续语音识别系统。




评论