内存受限系统的汉字显示设计研究

引言
在微电子技术、计算机技术不断发展的推动下,仪器仪表工业也发生了巨大的变化。现代仪表将嵌入式技术引入到仪器仪表的测试和控制中,使仪器仪表向着自动化智能化的方向发展,这已经成为当今仪器仪表系统的一种趋势。新型的仪器仪表设备将朝着操作简便、小型化、便携式、现场实时分析、高速运算等方向发展。由于中文显示界面友好,适合我国国情,特别是对于一些工业现场基层用户来说,中文显示已经成为普遍要求解决的问题。出于对成本等因素的考虑,嵌入式系统的存储器容量有限,这就迫使我们必须从编程上重视内存的使用效能,运用一些节约内存的技巧来设计汉字显示程序。
本文通过分析一般汉字显示方法,并结合嵌入式系统内存受限特点,提出了一种能在小容量内存系统中使用的汉字显示的方法。
1汉字显示的一般原理
要在点阵式LCD上显示汉字,首先需要获得汉字显示的点阵代码。一般方法是从计算机中文操作系统拥有的庞大的汉字库中提取所需的汉字显示点阵字库,存储在嵌入式应用系统中以备使用[1]。
在汉字库中,汉字字模大多以国标GN2313-80的区位码为索引存放。国标码与ASCⅡ码属同一制式,ASCⅡ码用一个字节编码,码值范围为00H-7FH,其中94个可见字符的码值范围为21H-7EH,国标码也是以94个ASCⅡ可见字符代码为基集(码值范围为21H-7EH),用两个字节组成国标码,其中高字节表征区,低字节表征位,共有94个区,每区又分94个位,区和位编号均为十进制的01-94,对应的国标码码值范围为21H-7EH,因此国标码与区位号之间存在下列关系:国标码高字节=区号+20H;国标码低字节=位号+20H。
汉字显示点阵字库是汉字显示点阵代码(也称字模)的集合,中文操作系统中最常用的是16*16点阵字库(通常文件名为HZK16),其点阵代码为横向排列。由于汉字显示点阵字库中的显示点阵代码一般按区位码顺序存放,所以提取字模时只要求出某汉字的偏移地址(显示点阵代码相对于汉字显示点阵字库首地址的字节数)即可,偏移地址值与汉字区位码有以下转换关系[2]:
偏移地址=((区号-1)*94+(位号-1))*32。
在嵌入式系统中,为了实现字符(半个汉字)、汉字的混合显示,通常对提取的横向字模加以转换形成纵向排列的字模。按照上述规则将字模从计算机中文操作系统提取出来加以转换存入到嵌入式系统中以供使用[3]。
2嵌入式系统中显示汉字存在的问题及解决方法
嵌入式系统由于受成本、体积等因素的影响,其配置的存储器容量一般都非常有限。这种存储器容量受到限制的系统又称为内存受限系统。在小型智能仪器仪表一类嵌入式设备中,内存有限,强固耐用的要求高,显示汉字首先要有包含所有会被显示的汉字和字符构成的字库,在前面所提到的汉字显示的一般原理中,嵌入式系统中存储的是从计算机中文操作系统拥有的庞大的汉字库中提取的汉字区位码信息,由于汉字数目繁多,导致区位码信息占用大量内存。为了节省内存空间,需要将字模依照一定的方法存储在嵌入式系统内存中,也就是建立精简的字库。在建立精简的字库时主要面临两个问题:
(1)相同的汉字或字符会反复被使用,在不同的句子中重复出现多次,如果以句子字符串为单位存储,虽然会加快句子输出速度,但也会大大增加程序对内存的需求。为了解决这个问题,使用如下方法:采用单字排列构成字库,一个汉字字模信息只存储一次,任何需要使用它的地方,共享同一个字模。应用此方法后,虽然会增加程序的复杂程度,但却极大地节省了内存,提高了内存的利用效率。
(2)字库在程序中占有很大的比例,需要大量内存,并且要显示的内容除汉字外还有一些字符,而字符字模只有16个字节,是汉字字模的一半。正如编译器或汇编器往往令数据对齐以使CPU指令集更便捷的访问对齐数据一样[4],如果存储字符字模时把其16个字节添零扩充为32个字节,计算偏移地址直接用字序号乘上32再加上字库首地址即可,但这种方法只适用于字符比较少的情况,当字符较多时将浪费大量内存。
解决上述问题采取如下方法:在符合系统要求的前提下,逐一考虑每个字和字符,考虑其中有多少信息是真正必须存储的,也就是说尽量精简字库,若有相同意义的字或词就只保留一种而舍弃其它的同义字词。此外,将字库建在程序末尾,先依次存储汉字字模,每个汉字字模占用32个字节,然后依次存储字符字模,每个字符字模占用16个字节,并给汉字和字符统一编上序号(见图1)。并为每一条输出的汉字信息建立一个索引,索引由每条汉字信息中各个汉字和字符的序号组成。显示一句话时,只需获得这句话中各个汉字和字符的序号,根据序号Q先判断需要显示的是汉字还是字符,如果为汉字,则根据公式:字模地址=字库首地址+32*Q,如果为字符,则根据公式:字模地址=字库首地址+32*X+(Q-X)*16,求得它们的字模地址,依次将它们的字模复制并存入一个缓冲区,再根据液晶显示原理将缓冲区字模送到显示模块端口[5]。程序流程见图2。
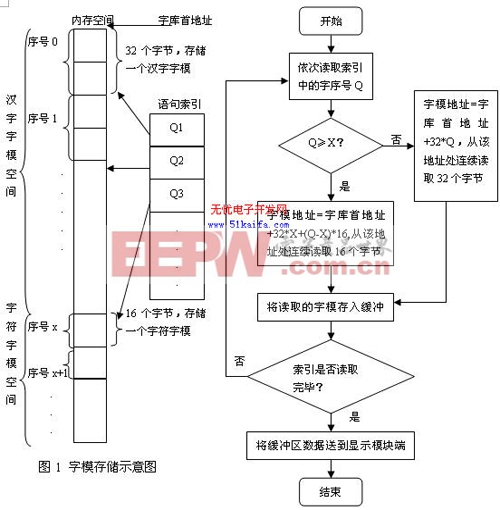
通过以上方法给程序员造成一种假象:即他可以拥有同一份数据的多份副本,而又不必浪费内存,使得系统内存的总需求量降低,而且相同数量的数据可以随机存储、更新、访问。但是,根据字序号找到一句话的各个字模再统一存入缓冲区势必降低系统的时间效率,同时也需要程序员花费心力来完成不那么直观的代码。而且系统需要扩充字库时,不能直接在字库末尾补充,而应在汉字字模末尾添加汉字字模,在字符字模末尾添加字符字模,再依次重新编写字序号。此外,显示句子的索引也需要修改,这就降低了系统的扩展性。不过在本文讨论的节省内存问题上,衡量利弊,这种方法还是有效的。
3结论
在内存受限系统中建立精简的字库是显示汉字的关键步骤。本文通过研究有关算法,在分析内存字库所需存储信息的特点的基础上,提出了一种节省内存的字库建立方法。依照此法在所设计的单片机电路上进行编程,能够实现汉字的显示,且明显减少了系统的内存,满足了实用的要求,所以,本文算法具有一定的实际意义。





评论