OCP 领导者和创新者齐聚一堂,共同探索 C2810Z5、C2820Z5、Whitestone 2 和现场固件演示。【爱尔兰都柏林电 - 2025 OCP EMEA 峰会,2025 年 4 月 29 日】 - 卓越的高性能和节能服务器解决方案提供商MiTAC神雲科技股份有限公司幸地宣布,参加 4 月 29 日至 30 日位于都柏林会议中心举行的 2025 OCP EMEA 峰会。在 B13 号展位,MiTAC 神雲科技将展示其在服务器设计、可持续冷却和开源固件开发方面的最新创
关键字:
服务器 OCP AI 高性能计算
3 月 11 日消息,据 ZDNet Korea 今日报道,三星电子 11 日的业务报告称,三星电子第四代 4 纳米工艺(SF4X)已于去年 11 月开始量产。由于该工艺专注于人工智能等高性能计算(HPC)领域,预计将在三星代工业务的复苏中发挥关键作用。三星第一代 4 纳米于 2021 年量产。图源:三星电子据了解,与前几代相比,三星的第四代 4 纳米芯片采用了先进的后端连线(BEOL)技术,能够显著提升芯片的整体性能,同时降低制造成本。此外,该芯片还配备了高速晶体管,还支持 2.5D 和 3D 等下一代
关键字:
三星 量产 第四代 4 纳米 芯片 台积电 SF4X 人工智能 高性能计算 HPC BEOL
Supermicro, Inc. 作为AI/ML、高性能计算、云端、存储和5G/边缘领域的全方位IT解决方案提供企业,预告将推出全新设计的X14服务器平台,并将通过新一代技术,使计算密集型工作负载与应用程序的性能进一步优化。继Supermicro于2024年6月推出的效率优化X14服务器获得了成功,新型系统以该系列服务器为基础进行全面重大升级,在单一节点中空前地支持256个性能核(P-Core),以及最高8800MT/s的MRDIMM内存,并与新一代SXM、OAM和PCIe GPU兼容。此项组合可显著加速
关键字:
Supermicro Intel X14服务器 AI 高性能计算 工作负载
2023年8月21日 – 提供超丰富半导体和电子元器件™的业界知名新品引入 (NPI) 代理商贸泽电子 (Mouser Electronics) 即日起供货TE Connectivity的有源光缆组件。与传统的无源铜缆和新兴的有源铜缆 (ACC/AEC) 解决方案相比,这些光缆组件拥有更出色的缆线灵活性和更长的延伸范围,支持高性能网络、存储和数据中心等应用。与铜缆替代品相比,这些光缆组件的传输距离更长、重量更轻、弯曲半径更小,非常适合用于交换机内部和交换机之间的高速互连、高性能计算、人工智能 (AI) 和
关键字:
贸泽 高性能计算 TE Connectivity 有源光缆组件
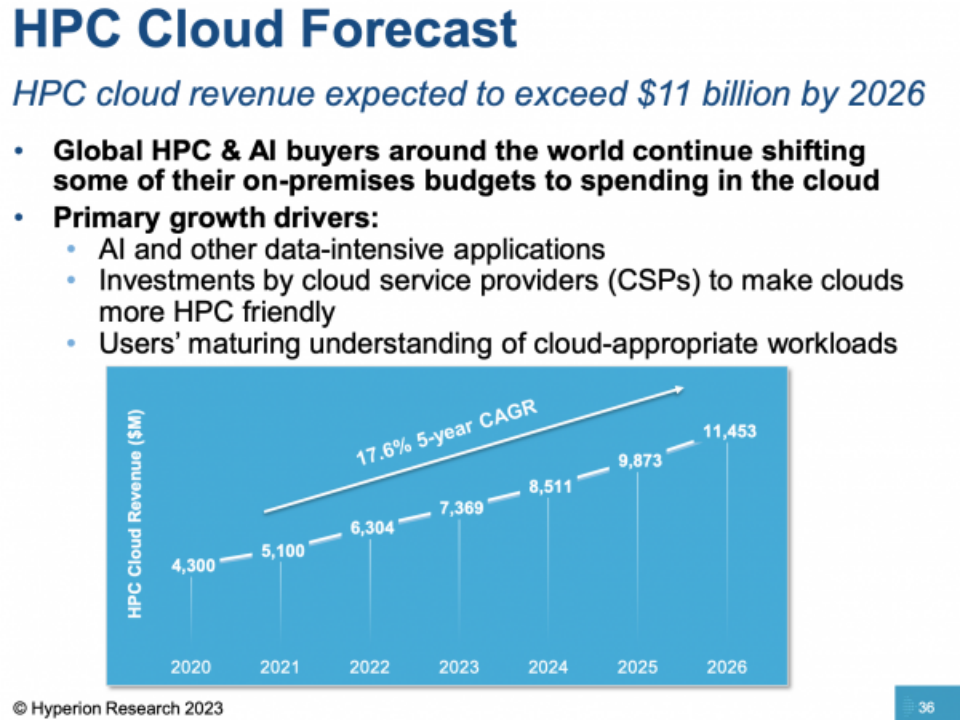
Hyperion 预测 2023 年本地服务器销售额将达到 170 亿美元左右。
关键字:
高性能计算
5月22日, 国际高性能计算和人工智能咨询委员(The HPC-AI Advisory Council)、新加坡国家超级计算中心(National Supercomputing Centre – NSCC Singapore)和澳大利亚国家超级计算中心(National Computational Infrastructure – NCI Australia)今天正式发布第六届APAC HPC-AI学生竞赛的参赛团队和任务。经过赛选,20支来自亚太区的队伍将在关键全球气候异常建模和大语言模型推理
关键字:
AI 高性能计算
5月11日消息,去年9月,当以太坊区块链不再使用工作量证明算法来验证交易时,加密货币市场对高性能专用处理器的需求几乎在一夜之间消失了。那些使用或托管图形图像处理单元(GPU)的加密货币矿企发现,加密货币领域日益困难,他们曾经蓬勃发展的业务关键组成部分一去不复返。现在,像Hive Blockchain和Hut 8等矿企正在寻找机会,将手头的GPU处理器重新用到正在繁荣起来的人工智能行业。比特币矿企Hut 8首席执行官杰米·莱弗顿(JaimeLeverton)在接受采访时表示:“如果你能将GPU挖矿设备基础设
关键字:
AI 高性能计算
双方拓展战略合作,提供全面的3D系统集成功能,支持在单一封装中集成数千亿个晶体管 新思科技3DIC Compiler是统一的多裸晶芯片设计实现平台,无缝集成了基于台积公司3DFabric技术的设计方法,提供完整的“探索到签核”的设计平台 此次合作将台积公司的技术进展与3DIC Compiler的融合架构、先进设计内分析架构和签核工具相结合,满足开发者对性能、功耗和晶体管数量密度的要求新思科技(Synopsys, Inc.,纳斯达克股票代码:SNPS)近日宣布扩大与台积公司的战略技术合作
关键字:
新思科技 台积电 高性能计算 3D系统集成
6月23日消息,美国当地时间周二,芯片巨头英特尔首席执行官帕特·盖尔辛格(Pat Gelsinger)宣布对公司进行重组,包括在其执行领导团队新增两名技术高管,以及创建两个新部门。英特尔现任高管桑德拉·里维拉(Sandra Rivera)和拉贾·科杜里(Raja Koduri)将分别担任新的高级领导职务,科技行业资深人士尼克·麦基翁(Nick McKeown)和格雷格·拉文德(Greg Lavender)则将加盟该公司。盖尔辛格说:“自从重新加入英特尔以来,整个公司的人才储备和令人难以置信的创新给我留下了
关键字:
英特尔 高性能计算 AI
要点:新思科技与三星基于Fusion Design Platform开展合作,充分释放三星在最先进节点工艺的优势经过认证的流程为开发者提供了一整套针对时序和提取的业界领先数字实现和签核解决方案新思科技Fusion Design Platform能够实现业界最佳结果质量和最短交付时间,加快高性能计算设计周期新思科技(Synopsys, Inc., 纳斯达克股票代码:SNPS)近期宣布与三星开展合作,基于新思科技Fusion Design Platform™提供经认证的数字实现、时序和物理签核参考流程,以加速
关键字:
新思科技 三星 高性能计算
国家重点研发计划“高性能计算”重点专项经过两年的战略研究及论证,于2016年正式启动。经形式审查、预评审、正式申报、视频答辩评审、项目预算 评估及 项目任务书签订等环节,高技术中心顺利完成了“高性能计算”重点专项首批19个项目的立项工作,对10个重点研究任务进行了部署。
该重点专项的总体目标是突破E级计算机核心技术,依托自主可控技术,研制满足应用需求的E级(百亿亿次级)高性能计算机系统,使我国高性能计算机的 性能在 “十三五&rdquo
关键字:
高性能计算
高性能计算 ( high performance compute , HPC)是一个计算机集群系统 , 它通过各种互联技术将 多个计算机系统连接在一起 , 利用所有被连接系 统的综合计算能力来处理大型计算问题。高性能 计算方法的基本原理就是
关键字:
高性能计算 集群系统
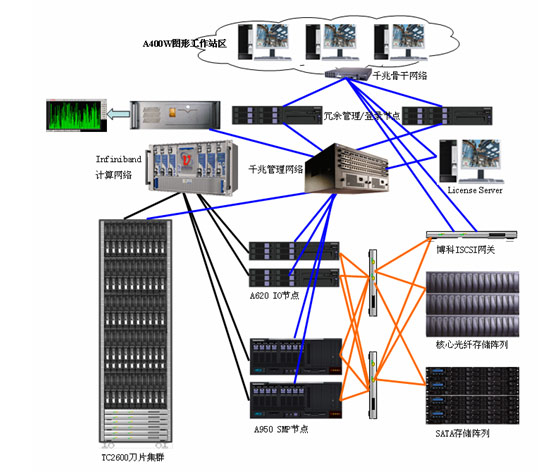
摘要 IBM高性能计算机系统承担着中国气象局主要气象气候业务科研模式运行,整个系统的数据交换网络是通过HPS(High Performance switch)来实现的。2006年9月21日,IBM高性能计算机系统的HPS网络发生故障,导致了科研分
关键字:
IBM 高性能计算 系统 故障分析
随着IBM高性能计算机“走鹃”于2008年6月诞生,高性能计算机(HPC)迈入千万亿次门槛。用户对高性能计算需求的持续增长,推动着HPC规模越做越大。在由CPU构成的高性能计算的世界中,由于CPU计算性能的提升速度远远落后于高性能计算需求增长的速度,增加CPU的个数便成为提高HPC性能的主要途径。如今全球高性能计算500强(Top500)中已经出现内核累计总数多达20多万个的HPC。
但是,在提升性能的同时,CPU个数的增加也给HPC增添了复杂性,并带来可用性降低、系统功
关键字:
高性能计算 HPC
刚刚更新的HPC TOP500榜单再次点燃了人们的激情。对专业人士来说,这份来自国际超级计算大会的权威成果预示着高性能计算的新风向。即便是普通读者,这份榜单也绝非无关紧要,计算能力跃升意味着我们能更快地找到石油、更准确地预测天气和自然灾害、更清楚地了解生命的奥秘……
从科研向商用普及
相较以往,此次公布的榜单似乎动静更大些。这半年来,计算能力再上了一个数量级,考量依据首次引入能效数据、四核快速成为绝对主流,集群、Infiniband等技术主题词的优势也进一步扩
关键字:
英特尔 高性能计算 服务器 IBM
高性能计算介绍
您好,目前还没有人创建词条高性能计算!
欢迎您创建该词条,阐述对高性能计算的理解,并与今后在此搜索高性能计算的朋友们分享。
创建词条
关于我们 -
广告服务 -
企业会员服务 -
网站地图 -
联系我们 -
征稿 -
友情链接 -
手机EEPW
Copyright ©2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《电子产品世界》杂志社 版权所有 北京东晓国际技术信息咨询有限公司
京ICP备12027778号-2 北京市公安局备案:1101082052 京公网安备11010802012473