首款嵌入式FPGA诞生 AI将迎来最好时代?

eFPGA如何做到带宽增加10倍延迟减小至1/10
本文引用地址:https://www.eepw.com.cn/article/201610/311373.htmRobert Blake为包括电子发烧友在内的媒体解密了Speedcore eFPGA为何能在互联带宽增加10倍、互联延迟减小至1/10的提升下还能将功耗降低50%,成本降低90%。
要嵌入到SoC中首先需要解决FPGA芯片的面积问题,标准的FPGA内核与可编程IO、控制器等面积比接近1:1。Achronix 的Speedcore eFPGA直接连接至SoC,不仅能够将FPGA芯片面积减少一半,使FPGA能够嵌入到SoC中,还能够减小CB的尺寸、减少PCB的层数以及提高信号完整性。
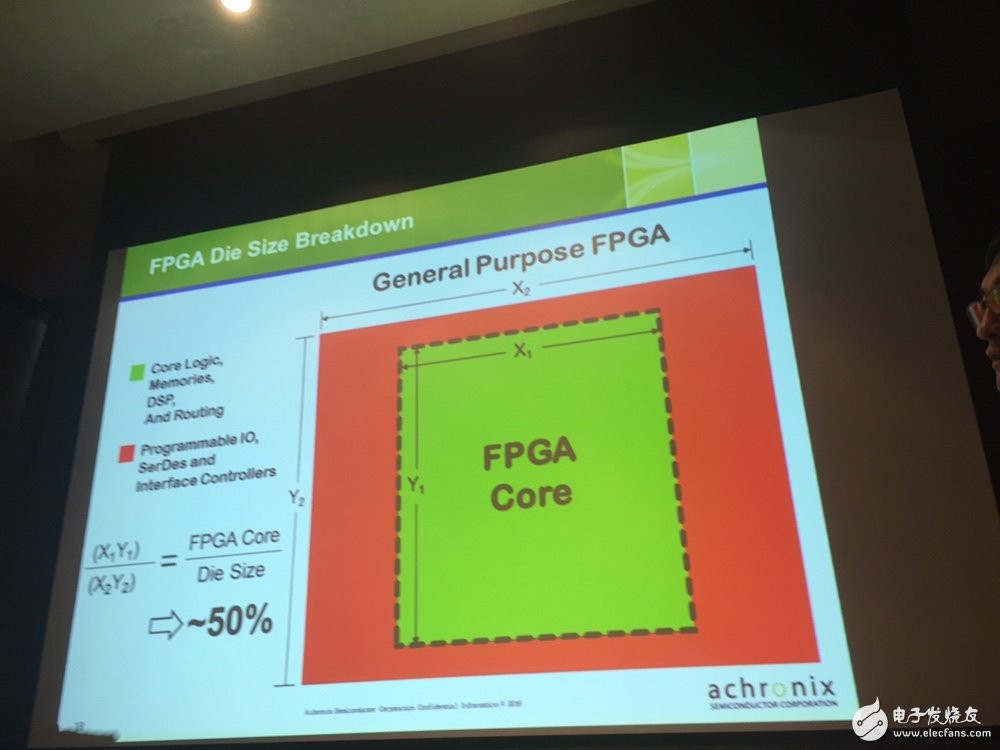
图:eFPGA面积减小一半
Speedcore以内部连线方式直接连接至SoC,省去了在外置独立FPGA中可见的大型可编程输入输出缓冲(IO buffer),能耗得到了降低。另外,Speedcore省去了对独立FPGA周边所有支持性元器件的需求,这些元器件包括电源调节器、时钟发生器、电平位移器、无源元件和FPGA冷却器件,成本也就相应的降低。

图:Speedcore eFPGA功耗及成本的降低

图:Speedcore与标准FPGA的带宽及延迟时间对比
至此,对于eFPGA能比标准FPGA增加10倍带宽以及延迟减小至1/10也就容易理解了。由于减小了FPGA芯片面积,大大节省了信号的传输时间,信号可以直接进入,可以将延迟时间降低到2ns,甚至0ns。而由于嵌入到SoC当中,带宽也能够增加十倍之多。
eFPGA工艺技术及工具
Achronix 的eFPGA目前主要瞄准计算中心、网络以及5G应用,而Speedcore以模块化方式构建,不仅可以在定义资源时提供灵活的支持,也能针对需求快速配置Speedcore IP 产品以实现交付。此外,模块化架构也支持Achronix方便地将这项技术移植到不同的工艺技术和金属叠层上。

图:Speedcore模块化架构
Robert Blake表示:“我们现在已经可以提供基于台积电(TSMC)的16纳米FinFET Plus(16FF+)工艺的Speedcore IP产品,并且正在开发基于台积电的7纳米工艺的IP。根据客户的需求,如果需要转换到新的工艺需要4到6个月的时间,之后针对不同核的支持则仅需要几周的时间。”
随着集成度的提升,对于FPGA而言软件工具也十分重要。Achronix提供的ACE设计工具可以在性能、资源使用和编译时间等方面评估Speedcore IP。此外,Achronix拥有关于Speedcore功能和ASIC集成流程方面的完整文档。

图:Achronix商业模式
除了开头提到的英特尔,谷歌也推出了TPU(Tensor Processing Unit)芯片用于机器学习,因此我们相信未来FPGA将迎来应用于人工智能(AI)的好时机,而eFPGA未来也将会在不断增长的高性能计算应用市场得到广泛应用。

图:Achronix Speedcore 嵌入式FPGA出货













评论