面向对称体系结构的FPGA仿真模型研究

2 仿真系统执行模式
2.1 多核/众核体系结构仿真系统执行模式
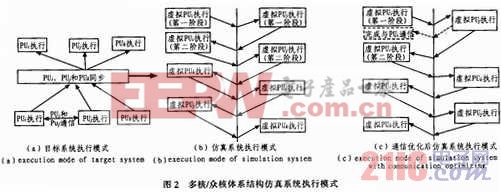
对称多核处理器中处理单元之间的耦合度不同,使得对应的仿真系统的执行模式也不一样。多核/众核体系结构通常采用粗粒度耦合执行的方式。如图2(a)所示.多个处理单元之间相互比较独立,其同步和通信通常处于任务级,即多个处理单元间的通信和同步的次数远小于它们执行的指令数。图中PUi和PUj之间有一次通信,PUi、PUj和PUk之间有一次同步。对应的仿真系统的执行模式如图2(b)所示,VAU先对PUi进行仿真,执行到与通信点时,将PUi的执行信息导入BS,然后VAU对PUi进行仿真,执行到与通信点时,将PUj的执行信息导入BS,将PUi的执行信息由BS导入VMU,对PUi的后续行为进行仿真,以此类推,如图2所示,箭头每穿过中线一次,表示计算页切换一次仿真对象,指向下的箭头表示VMU的信息导入BS,指向上的箭头表示BS中的信息导出至VMU。为了减少现场切换的次数,对两个PU通信时的执行过程进行优化,如图2(c)所示,VAU仿真PUi执行至通信点时,切换至PUj进行仿真,只有在PUj遇到其他同步或通信时,才进行现场切换,否则VAU一直对PUj进行仿真,直至PUj执行结束。PUj执行到与通信点时,PUj将通信数据发送至网络缓冲,并写入PUi对应的存储空间,如图2(c)中虚线所示。本文引用地址:https://www.eepw.com.cn/article/191432.htm
2.2 SIMD体系结构仿真系统执行模式
SIMD体系结构的处理单元之间是紧密耦合的,所有处理单元的执行过程都是严格同步的,即同一时钟周期内每个处理单元都对不同的数据进行完全同样的操作,如图3(a)所示。

在SIMD体系结构仿真系统中,必须在逻辑上保持这种完全同步的执行模式。本文采用的方式是,一条指令流出之后,让它在指令流水线中保持n个时钟周期(可以在连续的n个时钟内都发射同一条指令),VAU在这n个周期内分别对各处理单元对应的数据进行处理。若将n个时钟周期看作系统的工作周期,则n个数据是在同一工作周期内被处理,如图3(b)所示。这样则在逻辑上保持SIMD的执行模式。
3 仿真系统评估
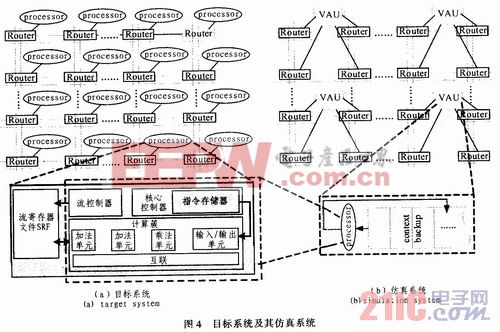
本文的目标系统如图4(a)所示。它由多个计算节点以Torus片上网络连接构成,其计算节点数目可以根据应用需求进行扩展。对应的仿真系统如图4(b)所示。在仿真系统中,采用一个虚拟计算节点(VAU)代替目标系统中的p个计算节点,图4(b)以p=4为例,展示了仿真系统的结构。目标系统中p个计算节点的计算操作都由VAU以图2的工作模式完成。VAU中包含一个现场保存存储器(context backup),用于保存目标系统中p个计算节点的中间结果。contextbackup的容量为每个计算节点中本地存储器容量的p倍,这样,context backup就有足够的能力存储p个计算节点的中间结果,从而减少与外部存储器的数据交换,减少VAU的停顿时间。







评论