短帧Turbo译码器的FPGA实现

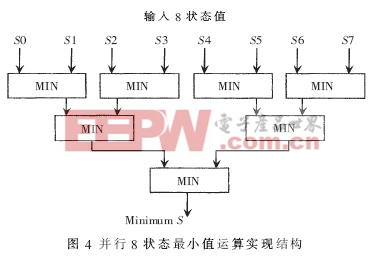
3.4 8状态值最小值运算单元
由MAX-LOG-MAP算法可知,在进行前后向递推归一化处理和计算译码软输出时,均需要计算每一时刻8个状态的最小值。为了减小计算延时,采用了8状态值并行比较的结构,与串行的8状态值比较结构相比较,要少4级延时。实现结构如图4所示。
4 仿真结果
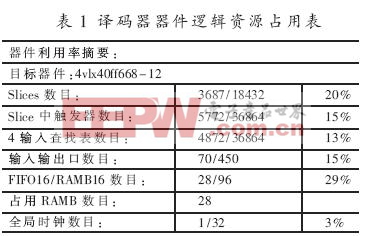
按照以上所分析的简化译码算法、FPGA实现的相关参数和结构,整个译码采用Verilog HDL语言编程,以Xilinx ISE 7.1i、Modelsim SE 6.0为开发环境,选定Virtex4芯片xc4vlx40-12ff668进行设计与实现。整个译码器占用逻辑资源如表1所示。
MAX-LOG-MAP译码算法,帧长为128,迭代4次的情况下,MATLAB浮点算法和FPGA定点实现的译码性能比较如图5所示。
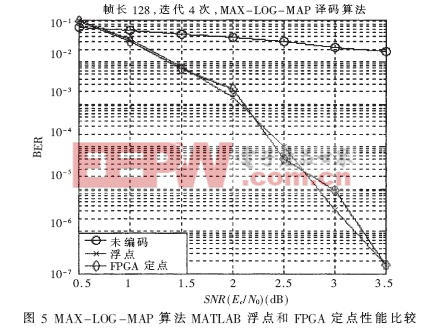
由MAX-LOG-MAP算法的MATLAB浮点与FPGA定点的性能比较仿真结果可知,采用F(9,3)的定点量化标准,FPGA定点实现译码性能和理论的浮点仿真性能基本相近,并具有较好的译码性能。
综上所述,在短帧情况下,MAX-LOG-MAP算法具有较好的译码性能,相对于MAP,LOG-MAP算法具有最低的硬件实现复杂度,并且Turbo码译码延时也较小。所以,在特定的短帧通信系统中,如果采用Turbo码作为信道编码方案,MAX-LOG-MAP译码算法是硬件实现的最佳选择。








评论