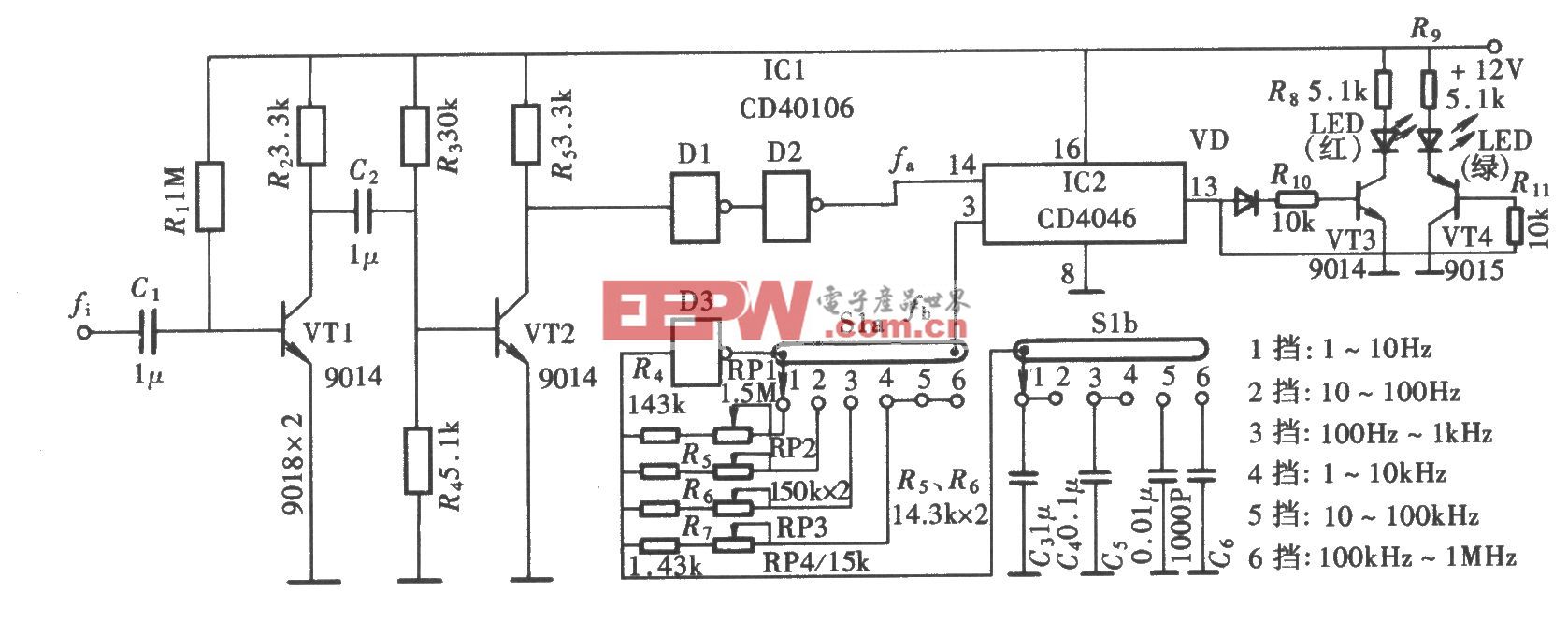
高新波:异质图像合成与识别(3)

首先利用贪婪学习算法生成初始的画像,然后利用照片和画像,分别使画像和画像匹配去寻找K近邻,基于照片和照片匹配去寻找K近邻,基于照片和画像匹配去寻找K近邻,由于画像和照片它的高频分量比较吻合,利用它做先验知识来选择一个最佳的K近邻然后进行合成,最终进行迭代以后仍然可以得到好的结果。

上图是我们生成的结果。

上图是我们利用给定风格的画像(一张),可以将给定的测试照片合成出对应风格的画像分。

同样地,对于非人脸图像的其他图像来说,也可以生成如给定的人脸图像风格一样的画像来。上图中分别展示了根据动漫风格、简单素描、复杂素描风格进行合成的画像。


当然我们还可以合成不同年龄的人脸。如果小孩走丢的时候是7、8岁,现在已经17、18岁,我们可以根据年龄的迁移合成不同年龄段的画像。以上主要讲的是由照片生成画像,当然也可以实现由画像生成照片,因为该过程是可逆的。

接下来是基于概率图模型的异质图像合成方法。

基于概率图模型的方法实际上可以用最大后验概率的方法寻找k近邻。当然,最大后验概率可以分解成最大似然函数和先验概率的情况。

上图是我们在2007年的时候提出的嵌入式模型合成方法。把画像和照片看成是观测序列,同时存在一个隐含状态和状态转移空间,利用状态转移矩阵得到合成模型,然后基于该模型实现画像或照片的合成。2014年在IJCV上我们对它做了新的解释,完全可以用最大后验概率或者概率图模型进行解释,这样我们就把它统一到概率图模型的框架上去。

09年在PAMI上有上图所示的王晓刚教授的一个工作,提出了利用马尔科夫随机场理论来进行画像的合成。过去我们生成画像块的时候只是利用照片和画像之间的关系,其实要生成画像的话,相邻画像块之间也有约束关系,为此提出了嵌入式的马尔科夫模型。这里面就有两个似然函数,一个表示画像和照片之间的关联性,一个表示画像块之间的兼容性。

上图是香港科技大学学者在CVPR2012提出马尔科夫加权随机场模型。在考虑块和块之间的关系时,把每一块又使用k近邻来表示,变成k近邻和k近邻之间的约束关系,同样分为画像和照片之间的关系和照片和照片之间的关系。

如上图所示,马尔科夫随机场实际上是找最近邻,而马尔科夫加权随机场实际上是利用k近邻来合成。

我们在此基础上又提出上图所示的新的基于直推式学习的方法。上图是一个非常简单的图模型,这个图上照片和画像都只有一个叶节点,由一个共同的根节点来控制,这个节点就是它们加权生成的加权矩阵W。现在如果来一个照片以后如何得到它的画像呢?过去是训练好以后再进行处理,现在要把训练和测试样本放在一起学习,就变成直推式的学习,这样我们来推导最大后验概率。实际上这个最大后验概率的计算可以基于概率图模型进行简化,当给定W的时候两个叶节点之间相互独立,可以把模型简化成上图中两个似然函数和一个先验概率的情况。

这种学习算法是我们2014年发表的,叫做基于直推式的学习,把训练样本和测试样本放在一起,原来归纳式的学习方法相当于在训练样本上做的误差很小,但是在测试样本不能保证误差也很小,直推式的方法可以保证在测试样本上误差也是非常小的。

这样一来求最大后验概率的问题就转变为如何构造先验概率和似然函数的问题。先验概率是构造式的,比如说我们要生成上图所示的这样一个块,利用k近邻加权线性组合形成的,邻近的块也是利用加权形成的,对于交叠的区域应该是非常兼容的,所以利用两个误差越小越好,相应的指数函数越大越好,这样构造出一个先验概率。

对于似然函数则是上图这样的,合成鼻子的时候事先找到了k个相近的鼻子,使得它合成的误差越小越好,画像上把对应的鼻子和权值W组合就可以生成出鼻子来,这样就可以构造出两个似然函数,合成误差越小越好。这两个权值在两者之间是共享的。

这样一来就可以构造出上图所示的一个目标函数,看上去非常复杂,实际上推导一下只不过是用矩阵来表示最大后验概率的计算公式。


优化目标函数以后就可以得到生成结果,上面分别是由照片生成画像和由画像生成照片的结果,显然比原来的两种方法合成出的图像更清晰。

同样还可以用合成出来的照片和画像进行模式识别。如上图所示,在香港中文大学的数据库上可以达到97%左右的正确率。

在合成过程中,如上图所示,如果测试图像里面光照是单侧不是正面光的,生成出来效果就不好;如果不同背景,原来照片训练里面都是蓝色背景,实际合成有黄色、白色背景,那合成出来效果也不好;另外不同种族,当训练库中的照片都是华人的照片,要合成一个欧洲人,那么合成出来的结果一定会像一个亚洲人。

为了解决这个问题,我们做了一个上图所示的基于多视的表示方法,进行特征描述的时候,不仅仅用灰度,还利用不同的滤波器滤波以后的图像,在图像上分别提取灰度信息、SURF特征、多尺度LBP特征,构造非常复杂的特征表示形式。

利用这个精细的表示形式,可以利用刚才讲的概率图模型进行上图所示的合成。

但是,由于生成不同的图像,不同特征的贡献率不一样。所以又引入一个加权系数,同时要学习一个合成的加权系数W,它们之间通过上图所示的迭代来进行优化。

同样基于概率图模型构造似然项和先验概率项,最后得到了上图所示的联合概率密度的形式。为了避免平凡解,我们还加入了一项正则项。

上图就给出不同特征的贡献程度,越亮的话就表示这个特征起的作用越大,越暗表示起的作用越小。

上图是我们由照片生成的画像,其他方法由于背景不一样可能会生成一些伪的背景。

同样我们可以由画像生成照片,上图是我们的实验结果。

可能对其他的照片我们的视觉不一定敏感,对于名人的照片一般都比较敏感。上图是对于一些明星的照片合成的画像结果,其他方法可能都有一些伪的阴影出现。

上图表示在用其他描述方法上我们的识别率都达到97%左右。



*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

c++相关文章:c++教程