如何用FPGA实现算法的硬件加速

当设计者试图从算法中获得最佳性能但软件方法已无计可施时,可以尝试通过硬件/软件重新划分来进行加速。FPGA易于实现软件模块和硬件模块的相互交换,且不必改变处理器或进行板级变动。本文阐述如何用FPGA来实现算法的硬件加速。
如果想从代码中获得最佳性能,方法包括优化算法、使用查找表而不是算法、将一切都转换为本地字长尺寸、使用注册变量、解开循环甚至可能采用汇编代码。如果所有这些都不奏效,可以转向更快的处理器、采用一个不同的处理器架构,或将代码一分为二通过两个处理器并行处理。不过,如果有一种方法可将那些对时间有严格要求的代码段转换为能够以5-100倍速度运行的函数调用,而且如果这一方法是一种可供软件开发之用的标准工具,这可信吗?现在,利用可编程逻辑作为硬件加速的基础可使这一切都变成现实。
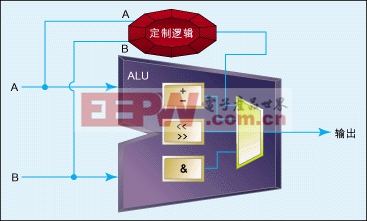
图1:带定制指令的可配置处理器架构。
低成本可编程逻辑在嵌入式系统中应用得越来越普遍,这为系统设计者提供了一个无需对处理器或架构进行大的改动即可获得更高性能的可选方案。可编程逻辑可将计算密集型功能转换为硬件加速功能。从软件的角度看,这只是简单地将一个函数调用做进一个定制的硬件模块中,但运行速度要比通过汇编语言优化的相同代码或将算法转换为查找表要快得多。
硬件加速
首先探讨一下什么是硬件加速,以及将算法作为定制指令来实现与采用硬件外围电路的区别。硬件加速是指利用硬件模块来替代软件算法以充分利用硬件所固有的快速特性。从软件的角度看,与硬件加速模块接口就跟调用一个函数一样。唯一的区别在于此函数驻留在硬件中,对调用函数是透明的。
取决于算法的不同,执行时间最高可加快100倍。硬件在执行各种操作时要快得多,如执行复杂的数学功能、将数据从一个地方转移到另一个地方,以及多次执行同样的操纵。本文后面将讨论一些通常用软件完成的操作,经过硬件加速后这些操作可获得极大的性能提高。
如果在系统设计中采用FPGA,那么在设计周期的任何时候都可以添加定制的硬件。设计者可以立刻编写软件代码,并可在最终定稿之前在硬件部分上运行。此外,还可以采取增量法来决定哪部分代码用硬件而不是软件来实现。FPGA供应商所提供的开发工具可实现硬件和软件之间的无缝切换。这些工具可以为总线逻辑和中断逻辑生成HDL代码,并可根据系统配置定制软件库及include文件。
带一些CISC的RISC
精简指令集计算(RISC)架构的目标之一即是保持指令简单化,以便让指令运行得足够快。这与复杂指令集计算(CISC)架构正好相反,后者一般不会同样快地执行指令,但每个指令可完成更多处理任务。这两种架构应用得都很普遍,而且各有所长。
如果能根据特定的应用将RISC的简单和快速特性与CISC强大的处理能力结合起来,岂不两全其美?其实这正是硬件加速所要做的。加入为某种应用而定制的硬件加速模块可以提高处理能力,并减少代码复杂性和密度,因为硬件模块取代了软件模块。可以这么说,是用硬件来换取速度和简单性。
定制指令和硬件外围电路方式
有两种硬件加速模块实现方式。其一是定制指令,它几乎可在每一个可配置处理器中实现,这是采用可配置处理器的主要优点。如图1所示,定制指令是作为算术逻辑单元(ALU)的扩展而添加的。处理器只知道定制指令就像其它指令一样,包括拥有自己的操作代码。至于C代码,宏可自动生成,从而使得使用该定制指令跟调用函数一样。
如果定制指令需要几个时钟周期才能完成,而且要连续调用它,则可以流水线式定制指令来实现。这样可在每个时钟周期产生一个结果,不过开始时有些延迟。
硬件加速模块的另一种实现方式是硬件外围电路。在这一方式下,数据不是传递给软件函数,而是写入存储器映射的硬件外围电路中。计算是在CPU之外完成的,因此在外围电路工作的同时CPU可以继续运行代码。其实代替软件算法的只是一个普通的硬件外围电路。与定制指令的另一个不同之处是硬件外围电路可以访问系统中的其它外围电路或存储器,而无须CPU介入。
根据硬件需要做什么、怎么工作以及需要多长时间可以决定采用是定制指令还是硬件外围电路更合适。对于那些在几个周期内就可完成的操作,定制指令一般更好些,因为它产生的开销要更少。对于外围电路,一般需要执行几个指令来写入控制寄存器、状态寄存器和数据寄存器,而且需要一个指令来读取结果。如果计算需要几个周期,实施外围电路比较好,因为它不会影响CPU流水线。或者,也可以实施前面所述的流水线式定制指令。
另一个区别是定制指令需要有限数目的操作数,并返回一个结果。根据处理器指令集架构的不同,操作数也各异。对某些操纵,这样可能显得很麻烦。此外,如果需要硬件从存储器或存储器中的其它外围电路读出和写入,则必须采用硬件外围电路,因为定制指令无法访问总线。
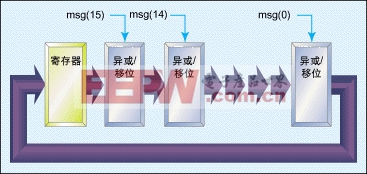
图2:16位CRC算法的硬件实现。(Optional)
选择代码
当需要优化C语言代码以满足某些速度要求时,可能要运行一个代码仿制工具,或亲自检查该代码以便了解代码的哪个部分导致系统停滞。当然,这需要熟悉代码以便知道瓶颈在哪儿。
即便找出瓶颈所在,如何优化也是个挑战。有些方案采用本地字大小的变量、带预先计算值的查找表,以及通用软件算法优化。这些技巧可产生快几倍的执行速度效果。另一种优化C算法的方法是用汇编语言编写。过去这种方法可获得很好的提高,但现今的编译器在优化C算法上已做得很好,因此这种性能的提高是有限的。如果需要显著的性能提高,传统的软件算法优化技巧恐怕是不够的。
然而,利用硬件实施的算法比软件实施要强100倍,这不足为奇。那么,如何确定将哪些代码转为硬件实施呢?大可不必将整个软件模块转换为硬件,而应选择那些在硬件中运行得特别快的操作,比如将数据从一处复制到另一处、大量的数学运算以及任何运行多次的循环。如果一个任务由几个数学运算组成,还可以考虑在硬件中加速整个任务。有些时候,仅加速任务中的一个操作就可满足性能要求。
实例:CRC算法的硬件加速
由于大量且重复的计算,循环冗余校验(CRC)算法或任何“校验和”算法都是硬件加速的不错选择。下面通过一个CRC算法的优化过程来探讨如何实现硬件加速。
首先,利用传统的软件技巧来优化算法,然后将其转向定制指令以加速算法。我们将讨论不同实现方法的性能比较和折衷。
CRC算法可用来校验数据在传输过程中是否被破坏。这些算法很流行,因为它们具有很高的检错率,而且不会对数据吞吐量造成太大影响,因为CRC校验位被添加进数据信息中。但是,CRC算法比一些简单的校验和算法有更大的计算量要求。尽管如此,检错率的提高使得这种算法值得去实施。
一般说来,发送端对要被发送的消息执行CRC算法,并将CRC结果添加进该消息中。消息的接收端对包括CRC结果在内的消息执行同样的CRC操作。如果接收端的结果与发送端的不同,这说明数据被破坏了。
CRC算法是一种密集的数学运算,涉及到二元模数除法(modulo-2 division),即数据消息被16或32位多项式(取决于所用CRC标准)除所得的余数。这种操作一般通过异或和移位的迭代过程来实现,当采用16位多项式时,这相当于每数据字节要执行数百条指令。如果发送数百个字节,计算量就会高达数万条指令。因此,任何优化都会大幅提高吞吐量。
代码列表1中的CRC函数有两个自变量(消息指针和消息中的字

fpga相关文章:fpga是什么











评论