基于ARM的非特定人语音识别系统的设计方案

0 引言
语音交互是人类交流和交换信息中最便捷的手段和最重要的媒体,长久以来,人们都希望找寻一种新的途径解决人类与机器的交互方式,希望机器设备能够“听”懂人类的语音信息进行交互,识别其含义并响应、从而做出相应动作,这样的交互方式更能被使用者接受,取代原有的键盘、按钮、开关等传统交互方式,基于非特定人的语音识别技术已然成为人机交互新方式的一个重要发展方向和研究热点。
语音信号的识别涉及众多学科知识体系,与计算机、语言学、通信、数理统计、信号处理和人工智能等学科都有着密切的关系,由于语音信号具有信息量大、不确定性、动态性和连续性的特点,在语音信号的预处理、特征提取等阶段处理数据量非常大,对软件的处理算法和硬件的处理能力都有较高的要求,传统使用PC机或者工控机等高处理性能的平台实现语音信号识别,但硬软件开发造价无疑是阻碍普及的重要因素,本系统采用ARM Cortex M3 内核ST 公司的32 位高性能单片机STM32F103C8T6结合LD3320语音识别芯片,通过构建SD卡文件系统实现非特定人语音识别关键词动态编辑功能,适用于嵌入式语音识别场合。系统电路简单,性价比高,识别距离和识别精度都可以满足嵌入式应用。
1 非特定人语音识别技术原理
非特定人语音识别技术研究的最终目的是让计算机等设备能够“听懂”人类语音,提取出语音中所包含的特定信息,成为人机通信和交互最便捷的手段。由于语音信号本身具有不确定性、动态性和连续性,这就为准确量化和处理该信号带来非常大的困难,每个人的语音要建立不同的语音样本也为识别的普及带来瓶颈约束。目前的语音识别是先建立特征库然后将待识别的信号经处理与特征库比对得到相似结果判定输出。从本质上属于基于统计模式的基本理论,分语言模型训练、识别分析两个大阶段构成和实现,如图1所示。
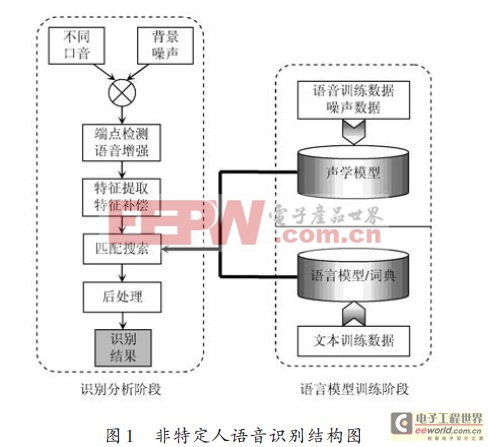
声学训练阶段通常是离线完成的,由语言学家对预先收集好的海量语音样本、语言数据库、噪声数据进行信号处理和知识挖掘,通过语音信号处理理论及相应数学算法模型建立语音识别系统所需要的“声学模型”和“语言模型”.
识别分析阶段通常是在线完成的,对用户实时的语音进行自动识别。识别过程通常又可以分为“前端”和“后端”两大模块:“前端”模块主要的作用是进行端点检测、降噪、特征提取等;“后端”模块的作用是利用训练好的“声学模型”和“语言模型”对用户说话的特征向量进行统计模式识别,得到其包含的文字信息,此外,后端模块还存在一个“自适应”的反馈模块,可以对用户的语音进行自学习,从而对“声学模型”和“语音模型”进行必要的“校正”,进一步提高识别的准确率。
2 系统设计的整体结构
本系统以STM32F103C8T6 微控制器为控制核心,搭配微控制器最小核心电路、LD3320语音识别电路、SD卡电路、电源电路、用户按键输入电路、串口数据输出电路、状态指示电路等综合组成。该系统体积小巧,可以作为嵌入式组件单元融入用户电路或者板卡中,上电后STM32F108C8T6内部程序进行程序初始化、SD 卡文件系统初始化、LD3320初始化、随后等待识别音频接收,识别完成后输出响应信息或者解码音频,系统整体结构如图2所示,最终实现积木式功能组件的全部功能。

3 系统硬件电路设计
3.1 微控制核心方案选型及电路
系统采用ARM Cortex M3内核ST公司的32位高性能单片机STM32F103C8T6 为控制核心,该芯片可以达到72 MHz的工作频率,内置高速存储器(64 KB的闪存和20 KB的SRAM),拥有丰富的I/O口资源和链接到两条APB 总线的外设。包括了12 b 的ADC、通用16 b 的定时器、还包括I2C、SPI、USART、USB、CAN等总线或串行通信接口,片内资源和扩展接口都十分丰富,该微控制核心是专门设计于满足高稳定性、低功耗、实时性、高性价比的嵌入式产品应用。该内核芯片可以满足非特定人语音识别的功能要求,利用相关电路构成STM32F103C8T6 的最小系统,在硬件PCB 中还集成了功能引针输出接口、SD卡接口、USB下载调试电路,用户按键、电源电路等,核心系统电路图如图3所示,配合其他外围扩展达到功能要求。







评论