深度学习干货|基于Tensorflow深度神经网络(DNN)详解

深度神经网络(Deep Neural Networks,简称DNN)是深度学习的基础,想要学好深度学习,首先我们要理解DNN模型。
本文引用地址:https://www.eepw.com.cn/article/202207/435861.htmDNN的基本结构
神经网络是基于感知机的扩展,而DNN可以理解为有很多隐藏层的神经网络。多层神经网络和深度神经网络DNN其实也基本一样,DNN也叫做多层感知机(MLP)。
DNN按不同层的位置划分,神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层。
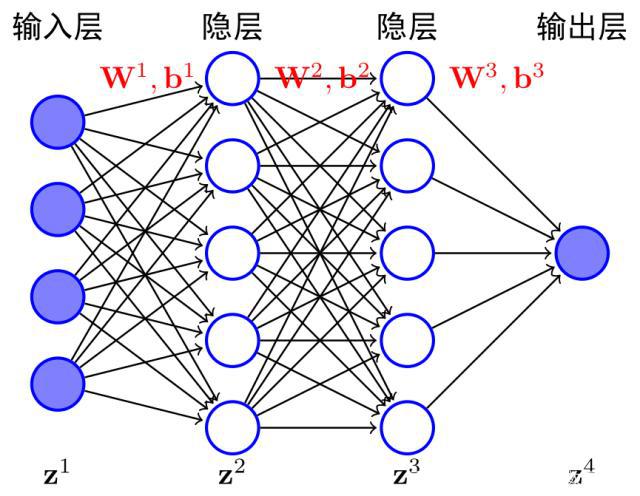
层与层之间是全连接的,也就是说,第i层的任意一个神经元一定与第i+1层的任意一个神经元相连。虽然DNN看起来很复杂,但是从小的局部模型来说,它还是和感知机一样,即一个线性关系加上一个激活函数。
训练过程中包含前向传播算法和后向传播算法
DNN前向传播算法
就是利用若干个权重系数矩阵W,偏倚向量b来和输入值向量X进行一系列线性运算和激活运算,从输入层开始,一层层地向后计算,一直到运算到输出层,得到输出结果为值。
DNN反向传播算法
如果我们采用DNN的模型,即我们使输入层n_in个神经元,而输出层有n_out个神经元。再加上一些含有若干神经元的隐藏层,此时需要找到合适的所有隐藏层和输出层对应的线性系数矩阵W,偏倚向量b,让所有的训练样本输入计算出的输出尽可能的等于或很接近样本输出,怎么找到合适的参数呢?
在进行DNN反向传播算法前,我们需要选择一个损失函数,来度量训练样本计算出的输出和真实的训练样本输出之间的损失。接着对这个损失函数进行优化求最小化的极值过程中,反向不断对一系列线性系数矩阵W,偏倚向量b进行更新,直到达到我们的预期效果。
在DNN中,损失函数优化极值求解的过程最常见的一般是通过梯度下降法来一步步迭代完成的,也可以是其他的迭代方法比如牛顿法与拟牛顿法。
深度学习过拟合问题
解决方法如下:
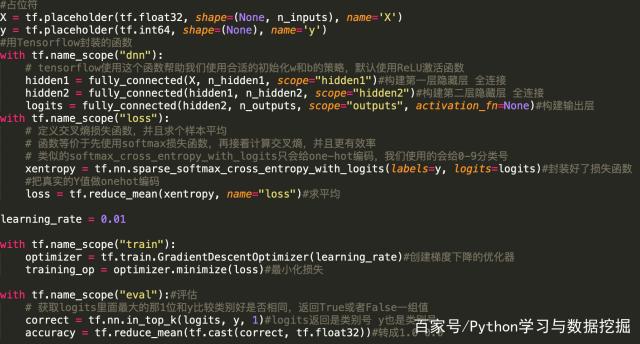
获取更多数据:从数据源获得更多数据,或数据增强;数据预处理:清洗数据、减少特征维度、类别平衡;增加噪声:输入时+权重上(高斯初始化);正则化:限制权重过大、网络层数过多,避免模型过于复杂;多种模型结合:集成学习的思想;Dropout:随机从网络中去掉一部分隐神经元;限制训练时间、次数,及早停止。核心代码



评论