FPGA 解决方案和标准控制器内核比较

MicroBlaze处理器是赛灵思(Xilinx)在嵌入式开发套件 (EDK) 中提供的两款32位内核之一,是实现硬件加速的灵活工具。图1是MicroBlaze的典型设计。该内核含有一个32位乘法器,但不含浮点单元(FPU)、桶式移位器或专用硬件加速器。对Xilinx公司Spartan FPGA 器件而言,默认系统含有区域优化的MicroBlaze(采用三级流水线),但大多数客户通常在开始时使用速度优化版(采用五级流水线)进行性能评估,其优点是小巧简洁,易于扩展。
本文引用地址:https://www.eepw.com.cn/article/201809/388779.htm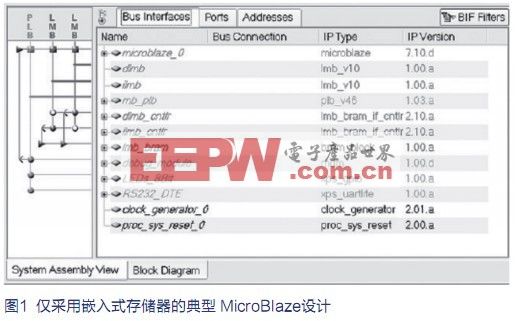
Xilinx客户针对这种处理器设计所要求的两个实际应用案例可说明MicroBlaze在硬件加速方面的作用。本文以 Spartan 器件为重点,比较 FPGA 解决方案和标准控制器内核,展现我们能够达到的性价比。这一方法同样适用于Virtex FPGA。
案例1:实施位反转算法
在第一个应用示例中,假定MicroBlaze处理器的运行速度仅为50MHz。采用 Spartan-3或Spartan-6器件可轻松实现这一速度。诸如本地存储器总线(指令和数据,LMB)以及处理器本机总线(PLB)等所有内部总线的运行速度均达到50MHz。为简单起见,假定没有连接外部DDR存储器。
现在假设客户想要在这个CPU上实施位反转算法。MicroBlaze自身没有通过硬件直接提供这个功能。再假定每秒需要完成2万次位反转操作。
要解决这个问题,大多数客户首先会采用纯软件方案,因为这样可轻松地实现想要的功能。而且如果性能足够高,无需进行任何修改。
为此,让我们先从简单的软件算法出发,实施简短精悍的解决方案。结果确实简单、精巧而且容易理解,不过效率很低。
unsigned int v=value;
unsigned int r = v;
int s = sizeof(v) * CHAR_BIT - 1;
for (v >>= 1; v; v >>= 1)
{
r = 1;
r |= v 1;
s--;
}
r = s;
return r;
这段程序运行相当顺利,不过就算在专门针对速度优化的MicroBlaze(使用五级流水线)上运行处理一个32 位字的算法,也用了220个周期。要执行2万次位反转操作,在速度为50MHz的MicroBlaze上约需88ms。
客户试图采用略有不同的方法来优化算法,但仍作为纯软件解决方案来实施。
要进一步提升性能,就要采用纯硬件解决方案,通过一种新的方式来让硬件加速器充分发挥性能。
为了加速这种基础操作,只需要在MicroBlaze快速单工链路(FSL)上连接一个非常简单的内核。标准FSL实施方案使用FSL总线(包括同步或异步FIFO)将数据从 MicroBlaze内核传输到FSL 硬件加速器IP核。带FIFO 的FSL总线与FIFO可对上述两者间的数据存取进行去耦。
如果采用带FIFO的标准FSL总线,则一般情况下执行时间为4个周期:一个周期用来将MicroBlaze上的数据通过FSL写入FIFO;一个周期用来将数据从FIFO 传输到FSL IP;一个周期用来把结果从FSL IP传送回 FSL总线的FIFO中;最后一个周期则负责从FSL总线读出结果并传输至 MicroBlaze。
MicroBlaze到FSL总线的连接以及FSL总线到FSL IP的连接可在EDK的图形视图中轻松创建。
这样代码要长得多,效率也有大幅度提升,但时间还是太长了,执行2万次操作现在仍然大概需要52ms。
随后客户在互联网上进行了一些调查,找到一种更好的算法,把代码改编为:
unsigned x = value;
unsigned r;
x = (((x 0xaaaaaaaa) >> 1) | ((x
0x55555555) 1));
x = (((x 0xcccccccc) >> 2) | ((x
0x33333333) 2));
x = (((x 0xf0f0f0f0) >> 4) | ((x
0x0f0f0f0f) 4));
x = (((x 0xff00ff00) >> 8) | ((x
0x00ff00ff) 8));
r = ((x >> 16) | (x 16));
return r;
这个代码看起来效率高,短小精悍。而且它不需要会造成流水线中断的分支。它在这个核心系统上运行只需29 个周期。
不过这个算法需要在1 、2、4、8和16位之间进行移位操作。我们在MicroBlaze的属性窗口中激活桶式移位器。不管移位操作的长度如何,采用桶式移位器可允许我们在一个周期内完成移位指令。这样可以让纯软件算法在 MicroBlaze上运行得稍快一些。
激活MicroBlaze硬件上的桶式移位器可将处理算法所需时间缩短到22个周期。与第一个版本的软件算法相比,此算法得到了显著改善。目前采用此算法,执行所有 2万次操作只需8.8ms,效率提升了10倍,不过仍未达到客户要求。
不过效率还有提升的空间。算法中的时延非常关键,应尽可能地缩短。但在我们的实施方案中,采用两根FSL总线仍需要四个时钟周期。不过我们可以通过将 MicroBlaze与硬件加速器之间的现有连接方式改为直接连接,便可将时延减半,缩短至两个时钟周期。这样一个周期用于将数据写入 FSL硬件加速器IP,而另一个周期则负责读回结果。
在采用直接连接方式时,需注意几个问题。首先,协处理器IP应存储输入,并以寄存方式提供结果。请注意在执行此操作时没有使用带FIFO的FSL总线。
此外,以不同时钟速率运行 MicroBlaze和FSL硬件加速器IP 容易发生问题。为避免发生冲突,设计人员最好将MicroBlaze和 FSL硬件加速器IP的运行速率设为一致。
不过,如何在不使用FSL总线的情况下将MicroBlaze和FSL硬件加速器IP直接连接起来呢?这很简单,只需将MicroBlaze和硬件加速器的数据线连接起来即可。如果需要,可再添加握手信号。
例如,使用位反转IP,只需一个写入信号即可。IP会一直很快运行,足以对MicroBlaze的任何请求做出及时响应。
IP本身非常简单。以下是摘录 VHDL 代码中的一段:
architecture behavioral of
fsl_bitrev is
-- data value sent by microblaze:
signal data_value :
std_logic_vector(0 to 31) := (others=>'0');
begin
-- bitreversed value to write back:
FSL_M_Data = data_value;
process(FSL_Clk)
begin
if rising_edge(FSL_CLK) then
if (FSL_S_Exists = '1') then
-- create the bitreversed data:
data_value(0) = FSL_S_Data(31);
data_value(1) = FSL_S_Data(30);
data_value(2) = FSL_S_Data(29);
...
data_value(30) = FSL_S_Data(1);
data_value(31) = FSL_S_Data(0);
end if;
end if;
end process;
end architecture behavioral;







评论