机器学习算法实践-决策树(Decision Tree)

前言
本文引用地址:https://www.eepw.com.cn/article/201807/383875.htm最近打算系统学习下机器学习的基础算法,避免眼高手低,决定把常用的机器学习基础算法都实现一遍以便加深印象。本文为这系列博客的第一篇,关于决策树(Decision Tree)的算法实现,文中我将对决策树种涉及到的算法进行总结并附上自己相关的实现代码。所有算法代码以及用于相应模型的训练的数据都会放到GitHub上(https://github.com/PytLab/MLBox).
本文中我将一步步通过MLiA的隐形眼镜处方数集构建决策树并使用Graphviz将决策树可视化。
正文
决策树学习
决策树学习是根据数据的属性采用树状结构建立的一种决策模型,可以用此模型解决分类和回归问题。常见的算法包括 CART(Classification And Regression Tree), ID3, C4.5等。我们往往根据数据集来构建一棵决策树,他的一个重要任务就是为了数据中所蕴含的知识信息,并提取出一系列的规则,这些规则也就是树结构的创建过程就是机器学习的过程。
决策树的结构
以下面一个简单的用于是否买电脑预测的决策树为例子,树中的内部节点表示某个属性,节点引出的分支表示此属性的所有可能的值,叶子节点表示最终的判断结果也就是类型。
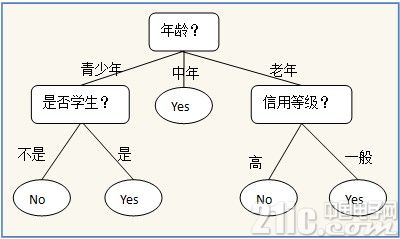
借助可视化工具例如Graphviz,matplotlib的注解等等都可以讲我们创建的决策树模型可视化并直接被人理解,这是贝叶斯神经网络等算法没有的特性。
决策树算法
决策树算法主要是指决策树进行创建中进行树分裂(划分数据集)的时候选取最优特征的算法,他的主要目的就是要选取一个特征能够将分开的数据集尽量的规整,也就是尽可能的纯. 最大的原则就是: 将无序的数据变得更加有序。
这里总结下三个常用的方法:
1.信息增益(information gain)
2.增益比率(gain ratio)
3.基尼不纯度(Gini impurity)
信息增益 (Information gain)
这里涉及到了信息论中的一些概念:某个事件的信息量,信息熵,信息增益等, 关于事件信息的通俗解释可以看知乎上的一个回答
某个事件 i 的信息量: 这个事件发生的概率的负对数
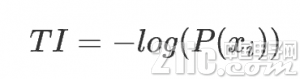
信息熵就是平均而言一个事件发生得到的信息量大小,也就是信息量的期望值
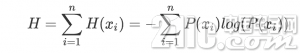
任何一个序列都可以获取这个序列的信息熵,也就是将此序列分类后统计每个类型的概率,再用上述公式计算,使用Python实现如下:
def get_shanno_entropy(self, values):
''' 根据给定列表中的值计算其Shanno Entropy
'''
uniq_vals = set(values)
val_nums = {key: values.count(key) for key in uniq_vals}
probs = [v/len(values) for k, v in val_nums.items()]
entropy = sum([-prob*log2(prob) for prob in probs])
return entropy
信息增益
我们将一组数据集进行划分后,数据的信息熵会发生改变,我们可以通过使用信息熵的计算公式分别计算被划分的子数据集的信息熵并计算他们的平均值(期望值)来作为分割后的数据集的信息熵。新的信息熵的相比未划分数据的信息熵的减小值便是信息增益了. 这里我在最初就理解错了,于是写出的代码并不能创建正确的决策树。
假设我们将数据集D划分成kk 份D1,D2,…,Dk,则划分后的信息熵为:
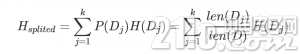
信息增益便是两个信息熵的差值
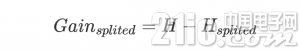
在这里我主要使用信息增益来进行属性选择,具体的实现代码如下:
def choose_best_split_feature(self, dataset, classes):
''' 根据信息增益确定最好的划分数据的特征
:param dataset: 待划分的数据集
:param classes: 数据集对应的类型
:return: 划分数据的增益最大的属性索引
'''
base_entropy = self.get_shanno_entropy(classes)
feat_num = len(dataset[0])
entropy_gains = []
for i in range(feat_num):
splited_dict = self.split_dataset(dataset, classes, i)
new_entropy = sum([
len(sub_classes)/len(classes)*self.get_shanno_entropy(sub_classes)
for _, (_, sub_classes) in splited_dict.items()
])
entropy_gains.append(base_entropy - new_entropy)
return entropy_gains.index(max(entropy_gains))
增益比率
增益比率是信息增益方法的一种扩展,是为了克服信息增益带来的弱泛化的缺陷。因为按照信息增益选择,总是会倾向于选择分支多的属性,这样会是的每个子集的信息熵最小。例如给每个数据添加一个第一无二的id值特征,则按照这个id值进行分类是获得信息增益最大的,这样每个子集中的信息熵都为0,但是这样的分类便没有任何意义,没有任何泛化能力,类似过拟合。
因此我们可以通过引入一个分裂信息来找到一个更合适的衡量数据划分的标准,即增益比率。
分裂信息的公式表示为:
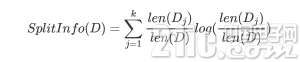
可见如果数据分的越多,分裂信息的值就会越大
这时候把分裂信息的值放到分母上便会中和信息增益带来的弊端。
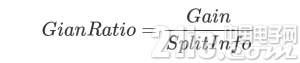
当然SplitInfo有可能趋近于0,这个时候增益比率就会变得非常大而不可信,因此有时还需在分母上添加一个平滑函数,具体的可以参考参考部分列出的文章
基尼不纯度(Gini impurity)
基尼不纯度的定义:
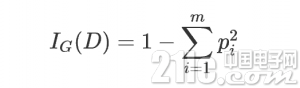
其中m 表示数据集D 中类别的个数, pi 表示某种类型出现的概率。可见当只有一种类型的时候基尼不纯度的值为0,此时不纯度最低。
针对划分成k个子数据集的数据集的基尼不纯度可以通过如下式子计算:
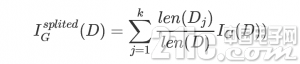
由此我们可以根据不纯度的变化来选取最有的树分裂属性
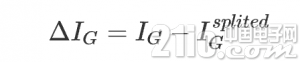
树分裂
有了选取最佳分裂属性的算法,下面我们就需要根据选择的属性来将树进一步的分裂。所谓树分裂只不过是根据选择的属性将数据集划分,然后在总划分出来的数据集中再次调用选取属性的方法选取子数据集的中属性。实现的最好方式就是递归了.
关于用什么数据结构来表示决策树,在Python中可以使用字典很方便的表示决策树的嵌套,一个树的根节点便是属性,属性对应的值又是一个新的字典,其中key为属性的可能值,value为新的子树。
下面是我使用Python实现的根据数据集创建决策树:
def create_tree(self, dataset, classes, feat_names):
''' 根据当前数据集递归创建决策树
:param dataset: 数据集
:param feat_names: 数据集中数据相应的特征名称
:param classes: 数据集中数据相应的类型
:param tree: 以字典形式返回决策树
'''
# 如果数据集中只有一种类型停止树分裂
if len(set(classes)) == 1:
return classes[0]
# 如果遍历完所有特征,返回比例最多的类型
if len(feat_names) == 0:
return get_majority(classes)
# 分裂创建新的子树
tree = {}
best_feat_idx = self.choose_best_split_feature(dataset, classes)
feature = feat_names[best_feat_idx]
tree[feature] = {}
# 创建用于递归创建子树的子数据集
sub_feat_names = feat_names[:]
sub_feat_names.pop(best_feat_idx)
splited_dict = self.split_dataset(dataset, classes, best_feat_idx)
for feat_val, (sub_dataset, sub_classes) in splited_dict.items():
tree[feature][feat_val] = self.create_tree(sub_dataset,
sub_classes,
sub_feat_names)
self.tree = tree
self.feat_names = feat_names
return tree
树分裂的终止条件有两个
一个是遍历完所有的属性
可以看到,在进行树分裂的时候,我们的数据集中的数据向量的长度是不断缩短的,当缩短到0时,说明数据集已经将所有的属性用尽,便也分裂不下去了, 这时我们选取最终子数据集中的众数作为最终的分类结果放到叶子节点上.
另一个是新划分的数据集中只有一个类型。
若某个节点所指向的数据集都是同一种类型,那自然没有必要在分裂下去了即使属性还没有遍历完.
构建一棵决策树
这我用了一下MLiA书上附带的隐形眼镜的数据来生成一棵决策树,数据中包含了患者眼部状况以及医生推荐的隐形眼镜类型.
首先先导入数据并将数据特征同类型分开作为训练数据用于生成决策树
from trees import DecisionTreeClassifier
lense_labels = ['age', 'prescript', 'astigmatic', 'tearRate']
X = []
Y = []
with open('lenses.txt', 'r') as f:
for line in f:
comps = line.strip().split('t')
X.append(comps[: -1])
Y.append(comps[-1])
生成决策树:
clf = DecisionTreeClassifier()
clf.create_tree(X, Y, lense_labels)
查看生成的决策树:
In [2]: clf.tree
Out[2]:
{'tearRate': {'normal': {'astigmatic': {'no': {'age': {'pre': 'soft',
'presbyopic': {'prescript': {'hyper': 'soft', 'myope': 'no lenses'}},
'young': 'soft'}},
'yes': {'prescript': {'hyper': {'age': {'pre': 'no lenses',
'presbyopic': 'no lenses',
'young': 'hard'}},
'myope': 'hard'}}}},
'reduced': 'no lenses'}}
可视化决策树
直接通过嵌套字典表示决策树对人来说不好理解,我们需要借助可视化工具可视化树结构,这里我将使用Graphviz来可视化树结构。为此实现了讲字典表示的树生成Graphviz Dot文件内容的函数,大致思想就是递归获取整棵树的所有节点和连接节点的边然后将这些节点和边生成Dot格式的字符串写入文件中并绘图。
递归获取树的节点和边,其中使用了uuid给每个节点添加了id属性以便将相同属性的节点区分开.
def get_nodes_edges(self, tree=None, root_node=None):
''' 返回树中所有节点和边
'''
Node = namedtuple('Node', ['id', 'label'])
Edge = namedtuple('Edge', ['start', 'end', 'label'])
if tree is None:
tree = self.tree
if type(tree) is not dict:
return [], []
nodes, edges = [], []
if root_node is None:
label = list(tree.keys())[0]
root_node = Node._make([uuid.uuid4(), label])
nodes.append(root_node)
for edge_label, sub_tree in tree[root_node.label].items():
node_label = list(sub_tree.keys())[0] if type(sub_tree) is dict else sub_tree
sub_node = Node._make([uuid.uuid4(), node_label])
nodes.append(sub_node)
edge = Edge._make([root_node, sub_node, edge_label])
edges.append(edge)
sub_nodes, sub_edges = self.get_nodes_edges(sub_tree, root_node=sub_node)
nodes.extend(sub_nodes)
edges.extend(sub_edges)
return nodes, edges
生成dot文件内容
def dotify(self, tree=None):
''' 获取树的Graphviz Dot文件的内容
'''
if tree is None:
tree = self.tree
content = 'digraph decision_tree {n'
nodes, edges = self.get_nodes_edges(tree)
for node in nodes:
content += ' {} [label={}];n'.format(node.id, node.label)
for edge in edges:
start, label, end = edge.start, edge.label, edge.end
content += ' {} -> {} [label={}];n'.format(start.id, end.id, label)
content += '}'
return content
隐形眼镜数据生成Dot文件内容如下:
digraph decision_tree {
959b4c0c-1821-446d-94a1-c619c2decfcd [label=call];
18665160-b058-437f-9b2e-05df2eb55661 [label=to];
2eb9860d-d241-45ca-85e6-cbd80fe2ebf7 [label=your];
bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd [label=areyouunique];
ca091fc7-8a4e-4970-9ec3-485a4628ad29 [label=02073162414];
aac20872-1aac-499d-b2b5-caf0ef56eff3 [label=ham];
18aa8685-a6e8-4d76-bad5-ccea922bb14d [label=spam];
3f7f30b1-4dbb-4459-9f25-358ad3c6d50b [label=spam];
44d1f972-cd97-4636-b6e6-a389bf560656 [label=spam];
7f3c8562-69b5-47a9-8ee4-898bd4b6b506 [label=i];
a6f22325-8841-4a81-bc04-4e7485117aa1 [label=spam];
c181fe42-fd3c-48db-968a-502f8dd462a4 [label=ldn];
51b9477a-0326-4774-8622-24d1d869a283 [label=ham];
16f6aecd-c675-4291-867c-6c64d27eb3fc [label=spam];
adb05303-813a-4fe0-bf98-c319eb70be48 [label=spam];
959b4c0c-1821-446d-94a1-c619c2decfcd -> 18665160-b058-437f-9b2e-05df2eb55661 [label=0];
18665160-b058-437f-9b2e-05df2eb55661 -> 2eb9860d-d241-45ca-85e6-cbd80fe2ebf7 [label=0];
2eb9860d-d241-45ca-85e6-cbd80fe2ebf7 -> bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd [label=0];
bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd -> ca091fc7-8a4e-4970-9ec3-485a4628ad29 [label=0];
ca091fc7-8a4e-4970-9ec3-485a4628ad29 -> aac20872-1aac-499d-b2b5-caf0ef56eff3 [label=0];
ca091fc7-8a4e-4970-9ec3-485a4628ad29 -> 18aa8685-a6e8-4d76-bad5-ccea922bb14d [label=1];
bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd -> 3f7f30b1-4dbb-4459-9f25-358ad3c6d50b [label=1];
2eb9860d-d241-45ca-85e6-cbd80fe2ebf7 -> 44d1f972-cd97-4636-b6e6-a389bf560656 [label=1];
18665160-b058-437f-9b2e-05df2eb55661 -> 7f3c8562-69b5-47a9-8ee4-898bd4b6b506 [label=1];
7f3c8562-69b5-47a9-8ee4-898bd4b6b506 -> a6f22325-8841-4a81-bc04-4e7485117aa1 [label=0];
7f3c8562-69b5-47a9-8ee4-898bd4b6b506 -> c181fe42-fd3c-48db-968a-502f8dd462a4 [label=1];
c181fe42-fd3c-48db-968a-502f8dd462a4 -> 51b9477a-0326-4774-8622-24d1d869a283 [label=0];
c181fe42-fd3c-48db-968a-502f8dd462a4 -> 16f6aecd-c675-4291-867c-6c64d27eb3fc [label=1];
959b4c0c-1821-446d-94a1-c619c2decfcd -> adb05303-813a-4fe0-bf98-c319eb70be48 [label=1];
}
这样我们便可以使用Graphviz将决策树绘制出来
with open('lenses.dot', 'w') as f:
dot = clf.tree.dotify()
f.write(dot)
dot -Tgif lenses.dot -o lenses.gif
效果如下:
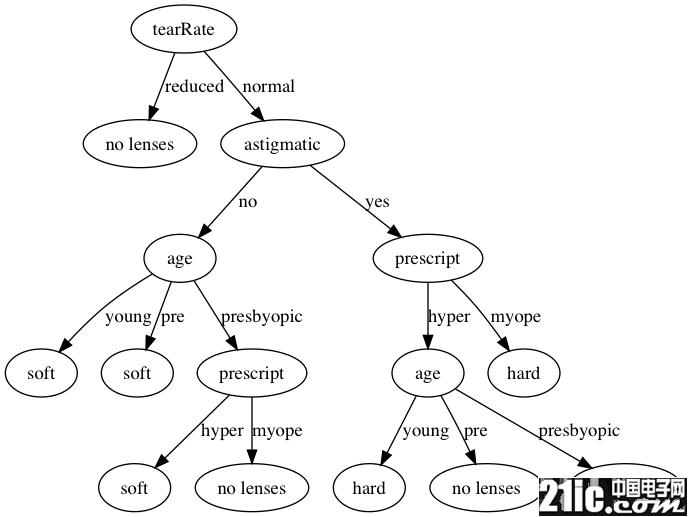
使用生成的决策树进行分类
对未知数据进行预测,主要是根据树中的节点递归的找到叶子节点即可。z这里可以通过为递归进行优化,代码实现如下:
def classify(self, data_vect, feat_names=None, tree=None):
''' 根据构建的决策树对数据进行分类
'''
if tree is None:
tree = self.tree
if feat_names is None:
feat_names = self.feat_names
# Recursive base case.
if type(tree) is not dict:
return tree
feature = list(tree.keys())[0]
value = data_vect[feat_names.index(feature)]
sub_tree = tree[feature][value]
return self.classify(feat_names, data_vect, sub_tree)
决策树的存储
通过字典表示决策树,这样我们可以通过内置的pickle或者json模块将其存储到硬盘上,同时也可以从硬盘中读取树结构,这样在数据集很大的时候可以节省构建决策树的时间.
def dump_tree(self, filename, tree=None):
''' 存储决策树
'''
if tree is None:
tree = self.tree
with open(filename, 'w') as f:
pickle.dump(tree, f)
def load_tree(self, filename):
''' 加载树结构
'''
with open(filename, 'r') as f:
tree = pickle.load(f)
self.tree = tree
return tree
总结
本文一步步实现了决策树的实现, 其中使用了ID3算法确定最佳划分属性,并通过Graphviz可视化了构建的决策树。






评论