一个进位保留加法阵列的HDL代码生成器

在现代数字通信系统中,FPGA的应用相当广泛。尤其在对基带信号的处理和整个系统的控制中,FPGA不但能大大缩减电路的体积,提高电路的稳定性,而且先进的开发工具使整个系统的设计调试周期大大缩短。其中对于一些基带信号处理任务,既可以用硬件实现,也可以用软件实现。用硬件实现的突出特点是可处理的数据速率大大提高,但相应的硬件实现也有一些弊端。对于目前流行的一些CPU包括DSP和单片机,都拥有丰富的指令集,可以很方便地处理各种数学运算。而用FPGA或ASIC这样的纯硬件来实现数学运算则有一定的困难,且不同的实现结构所能达到的性能也大不相同。加法器是在FPGA中实现各种数学运算的基础。一个单纯的两个加数的加法器可以用简单的组合逻辑来实现。但对于求多个加数和的运算,则可以有多种实现方案。下面首先比较几种实现方案的性能和所消耗资源,然后针对最优方案给出一种HDL(Hardware Description Language)代码生成器。
本文引用地址:https://www.eepw.com.cn/article/201706/349270.htm1 多加数加法器不同实现方案的分析和比较
本文所讨论的加法器的加数都是无符号的正数,对于带符号的加法运算可以通过一些附加处理后送入无符号加法器。以计算8个1位二进制加数的和为例进行分析,它可以有以下几种方案来实现:方案一最普通,是直接用加法器的级联将所有8个位逐次相加,这种实现方案最简单。因为8个1Bit数据的和最大可以是8,为4Bit数据,为了处理方便,所有的加数都事先扩展到4Bit再进行相加。设累加器的总延时为Tadd,一个全加器的延时为Ta,则用普通加法器进行一个4Bit加法。由于进位的逐级传递,所以在最坏情况下,需要大约4Ta的时间,8个加数全部加完需要7×4Ta=28Ta的时间。方案二是对方案一的改进,即将4Bit全加器全部换成超前进位加法器。设超前进位加法器的延时为Tc(Ta≤Tc4Ta),这样全部加法需要7Tc的时间。虽然方案二的时延已经缩短很多,可以处理的数据速率得到提高,但这种级联式的加法器的延时会随着加数的增多而呈线性增长,在要求速度较高的场合无法达到要求。于是本文提出方案三,即采用适合硬件实现高速并行的进位保留加法阵列。典型的8个1Bit数据进位保留加法阵列如图1所示。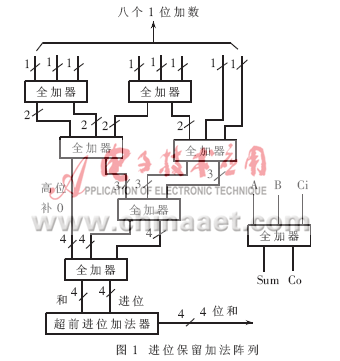
一个1位全加器有三个输入 A、B、Ci和两个输出Sum、Co,其中A和B是加数与被加数,Ci是输入进位,Sum是和,Co是输出进位。三个输入对两个输出而言是对称的,即使它们互相交换位置结果也不会受到影响。如果把一串全加器简单排成一行,它们之间的进位线不连接,则这一串全加器称为进位保留全加器。它具有如下特性:三个输入数之和等于两个输出数之和,即三个相加数每通过一次进位保留加法器,其个数就变为原来的2/3。利用该特点,对于所有相加数,在第一级将这些相加数分成三个一组,每组进入一个进位保留加法器,产生的和与进位数为原来的2/3,但是产生的和数位数有所扩展。在第二级再将上一级的输出分为3个一组,分别相加。依此类推,直到最后形成两个操作数,即累加和与累加进位。再用超前进位加法器将它们相加就得到最终的结果。由图1可知这种进位保留加法阵列的延时为:4Ta+Tc。
以Altera公司的FPGA芯片EPF10K30为实现芯片,对采用上面三种方案的8个1Bit加数的加法器进行了仿真,仿真波形如图2所示。
由图2可以看出,对于8Bit的Codeword中的“1”进行统计,三种加法器方案中进位保留加法阵列方案(AdderArray)的延时最短;方案二,超前进位加法器级联方案(FastAdder)的延时次之;方案一,采用普通全加器级联方案(FullAdder)的延时最长。上面的仿真由于位数较少,并不能很明显地体现出几种方案的差别。图3是对32Bit汉明距离发生器所用的累加器的仿真波形图。
由图3可以很明显地看出,方案三,进位保留加法阵列的延时大大低于另两种方案;而方案二的延时小于方案一,但相差不是很大,这主要因为虽然超前进位加法器本身的计算时间小于普通全加器。但累加结果在级间是逐级串行传递的,所以随着级数的增多,其延时也会迅速增大。而每一级的超前进位的加法优势受输入数据影响较大,对于比较小的数据,不涉及到向高位的进位传递问题,超前进位逻辑的作用就不能被完全发挥出来。
一般说来,系统可实现的性能与它所消耗的资源或处理复杂度之间总是矛盾的,性能的提高总是要以多消耗资源为代价的,而资源节省也总要相应降低一些性能。但是对于三种加法器方案所消耗资源进行统计表明,进位保留加法阵列消耗的资源大大小于其他两种方案。对于32个1Bit加法器方案,若采用Altera公司的EPF10K30芯片分别实现,级联型全加器方案和级联型超前进位加法器方案均需要消耗182个LC(Logical Cells),而进位保留加法阵列方案仅需65个LC。由此可知,进位保留加法阵列方案无论从性能表现还是资源消耗上都比前两种方案优异。这是因为它是一种并行处理的资源利用率更高的方案,是一种本质上不同于前两者的更好的实现方案。
2 进位保留加法阵列的HDL代码生成器
虽然进位保留加法器具有如此明显的优势,但它的实现是比较复杂的,不如级联型加法器直观、易实现。首先需要计算加法阵列的结构参数,参见图1,包括加法阵列的层数,每层所需要的全加器的个数和每层操作数的位数,然后按照阵列的规则画出阵列的结构图,最后对照结构图写HDL代码。其中每层操作数的位数都不同,而且全加器的输出Sum和Co有不同的权值,在加到下一层运算中时处理方式是不同的,Co需要移位相加。对于一个稍微大一点的阵列,编写HDL代码是一件既耗时又容易出错的工作。针对这种情况,本文给出了一个进位保留加法阵列的HDL代码生成器。它可以根据设计的需要自动计算加法阵列的结构参数,然后生成对应的HDL代码,大大方便了加法阵列的设计工作。
如图4所示,程序所需要的输入参数是加法阵列输入加数的个数和位数,单击“计算”按钮后程序将生成整个进位保留加法阵列的结构参数和消耗资源统计。由图4可知,32个1Bit加数的加法阵列共有8层,第一层需要10组全加器,每组1Bit;第二层需要7组全加器,每组2Bit(即两个1Bit全加器),以此类推。窗口左下角的资源统计栏里计算了整个加法阵列所需的全加器个数。而所需的LC数目是一个大概的统计值,它是在Maxplus II Version 10里编译本HDL代码生成器所生成的AHDL(Altera HDL)代码,然后让编译器自选FLEX 10K器件进行适配的结果。需要特别指出的是,加法阵列各层之间的连接结构将极大地影响FPGA的适配结果。所以本生成器根据Altera公司FPGA的结构特点,对阵列的连接结构进行了优化设计,使加法阵列适配后消耗的资源接近最小。
点击“生成代码”按钮后将出现图5所示的HDL代码窗口。图5中显示的是32个1Bit加法阵列的AHDL代码。单击“拷贝”按钮,然后在Maxplus II软件中粘贴到一个tdf文件中就可以直接进行编译和适配了。本程序还可以提供加法阵列的VHDL和Verilog代码,使进位保留加法阵列可以很方便地嵌入任何一种形式的系统设计中。
一些很典型的FPGA应用如FIR滤波器、高速乘法器和汉明距离发生器等都需要计算多个加数的和。针对此需求,本文首先比较了多加数加法器的三种实现方案,得出进位保留加法阵列是一种性能优异的实现方案。然后给出了一个能够自动生成加法阵列HDL代码的程序,它方便易用,并且能够提供AHDL、VHDL和Verilog三种HDL语言的代码,可以极大地提高开发效率。








评论