Nature重磅:Hinton、LeCun、Bengio三巨头权威科普深度学习

借助深度学习,多处理层组成的计算模型可通过多层抽象来学习数据表征( representations)。这些方法显著推动了语音识别、视觉识别、目标检测以及许多其他领域(比如,药物发现以及基因组学)的技术发展。利用反向传播算法(backpropagation algorithm)来显示机器将会如何根据前一层的表征改变用以计算每层表征的内部参数,深度学习发现了大数据集的复杂结构。深层卷积网络(deep convolutional nets)为图像、视频和音频等数据处理上带来突破性进展,而递归网络(recurrent nets )也给序列数据(诸如文本、语言)的处理带来曙光。
本文引用地址:https://www.eepw.com.cn/article/201612/342188.htm机器学习为现代生活诸多方面带来巨大动力:从网页搜索到社交网络内容过滤再到电商网商推荐,在相机、智能手机等消费品中也越来越多见。机器学习系统被用来识别图像中的物体、将语音转为文本,根据用户兴趣自动匹配新闻、消息或产品,挑选相关搜索结果。这类被应用程序越来越多地采用的技术,叫做深度学习。
传统机器学习技术在处理原始输入的自然数据方面能力有限。几十年来,建构模式识别或机器学习系统需要利用严谨的工程学和相当丰富的专业知识设计出一个特征提取器,它能将原始数据(例如图像像素值)转化成适于内部描述或表征的向量( vector ),在提取器中,学习子系统(通常是一个分类器)可以检测或分类输入模式。
表征学习(representation learning)是这样一套学习方法:输入原始数据后,机器能够自动发现检测或分类所需的表征信息。深度学习是一种多层描述的表征学习,通过组合简单、非线性模块来实现,每个模块都会将最简单的描述(从原始输入开始)转变成较高层、较为抽象的描述。通过积累足够多的上述表征转化,机器能学习非常复杂的函数。就分类任务来说,更高层的表征会放大输入信号的特征,而这对区分和控制不相关变量非常关键。比如,图片最初以像素值的方式出现,第一特征层级中,机器习得的特征主要是图像中特定方位、位置边沿之有无。第二特征层级中,主要是通过发现特定安排的边缘来检测图案,此时机器并不考虑边沿位置的微小变化。第三层中会将局部图像与物体相应部分匹配,后续的层级将会通过把这些局部组合起来从而识别出整个物体。深度学习的关键之处在于:这些特征层级并非出自人类工程师之手;而是机器通过一个通用(general-purpose)学习程序,从大量数据中自学得出。
某些根深蒂固的问题困扰了人工智能从业者许多年,以至于人们最出色的尝试都无功而返。而深度学习的出现,让这些问题的解决迈出了至关重要的步伐。深度学习善于在高维度的数据中摸索出错综复杂的结构,因此能应用在许多不同的领域,比如科学、商业和政府。此外,除了图像识别和语音识别,它还在许多方面击败了其他机器学习技术,比如预测潜在药物分子的活性、分析粒子加速器的数据、重构大脑回路、预测非编码DNA的突变对基因表达和疾病有何影响等。也许,最让人惊讶的是,在自然语言理解方面,特别是话题分类、情感分析、问答系统和语言翻译等不同的任务上,深度学习都展现出了无限光明的前景。
在不久的将来,我们认为深度学习将取得更多成就,因为它只需要极少的人工参与,所以它能轻而易举地从计算能力提升和数据量增长中获得裨益。目前正在开发的用于深层神经网络的新型学习算法和体系结构必将加速这一进程。
监督式学习
不管深度与否,机器学习最普遍的形式都是监督式学习(supervised learning)。比如说,我们想构造一个系统,它能根据特定元素对图片进行分类,例如包含一栋房子、一辆车、一个人或一只宠物。首先,我们要收集大量包含有房子、车、人或宠物的图片,组成一个数据集(data set),每张图片都标记有它的类别。在训练时,每当我们向机器展示一张图片,机器就会输出一个相应类别的向量。我们希望的结果是:指定类别的分数最高,高于其他所有类别。然而,如果不经过训练,这将是不可能完成的任务。为此,我们通过一个目标函数来计算实际输出与期望输出之间的误差或距离。接下来,为了减小误差,机器会对其内部可调参数进行调整。这些可调参数常被称为「权重」(weight),是实数,可看做定义机器输入-输出功能的「门把手」。在一个典型的深度学习系统中,可能存在着成千上亿的可调权重及用以训练机器的标记样本。
为了正确地调整权重矢量( weight vector),学习算法会计算出一个梯度矢量( gradient vector)。对每一个权重,这个梯度矢量都能指示出,当权重略微增减一点点时,误差会随之增减多少量。接着,权重矢量就会往梯度矢量的反方向进行调整。
从所有训练范例之上,平均看来,目标函数( objective function)可被视为一片崎岖的山地,坐落于由权重组成的高维空间。梯度矢量为负值的地方,意味着山地中最陡峭的下坡方向,一路接近最小值。这个最小值,也就是平均输出误差最小之处。
在实践中,大多数业内人士都是用一种被称为「随机梯度下降」(SGD - Stochastic Gradient Descent)的算法(梯度下降Grident Descent 是「最小化风险函数」以及「损失函数」的一种常用方法,「随机梯度下降」是此类下的一种通过迭代求解的思路——译者注)。每一次迭代包括以下几个步骤:获取一些样本的输入矢量( input vector),计算输出结果和误差,计算这些样本的平均梯度,根据平均梯度调整相应权重。这个过程在各个从整个训练集中抽取的小子集之上重复,直到目标函数的平均值停止下降。它被称做随机(Stochastic)是因为每个样本组都会给出一个对于整个训练集( training set)的平均梯度(average gradient)的噪音估值(noisy estimate)。较于更加精确的组合优化技术,这个简单的方法通常可以神奇地快速地找出一个权重适当的样本子集。训练过后,系统的性能将在另外一组不同样本(即测试集)上进行验证,以期测试机器的泛化能力( generalization ability) ——面对训练中从未遇过的新输入,机器能够给出合理答案。
很多当今机器学习的实际应用都在人工设定的特征上使用「线性分类」(linear classifiers)。一个「二元线性分类器」(two-class linear classifier)可以计算出特征向量的「加权和」(weighted sum)。如果「加权和」高于阈值,该输入样本就被归类于某个特定的类别。
二十世纪六十年代以来,我们就知道线性分类只能将输入样本划分到非常简单的区域中,即被超平面切分的半空间。但是,对于类似图像及语音识别等问题,要求「输入-输出函数」(input–output function)必须对输入样本的无关变化不敏感,比如,图片中物体的位置,方向或者物体上的装饰图案,又比如,声音的音调或者口音;与此同时「输入-输出函数」又需要对某些细微差异特别敏感(比如,一匹白色的狼和一种长得很像狼的被称作萨摩耶的狗)。两只萨摩耶在不同的环境里摆着不同姿势的照片从像素级别来说很可能会非常地不一样,然而在类似背景下摆着同样姿势的一只萨摩耶和一只狼的照片在像素级别来说很可能会非常相像。一个「线性分类器」(linear classifier),或者其他基于原始像素操作的「浅层(shallow)」分类操作是无论如何也无法将后者中的两只区分开,也无法将前者中的两只分到同样的类别里的。这也就是为什么「浅层」「分类器(classifiers)」需要一个可以出色地解决「选择性-恒常性困境」( selectivity–invariance dilemma)的「特征提取器」(feature extractor)—— 提取出对于辨别图片内容有意义的信息,同时忽略不相关的信息,比如,动物的姿势。我们可以用一些常规的非线性特征来增强「分类器」(classifiers)的效果,比如「核方法」(kernel methods),但是,这些常规特征,比如「高斯核」(Gaussian Kernel)所找出来的那些,很难泛化( generalize )到与训练集差别别较大的输入上。传统的方法是人工设计好的「特征提取器」,这需要相当的工程技巧和问题领域的专业知识。但是,如果好的「特征提取器」可以通过「通用学习程序(General-Purpose learning procedure)」完成自学习,那么这些麻烦事儿就可以被避免了。这就是深度学习的重要优势。
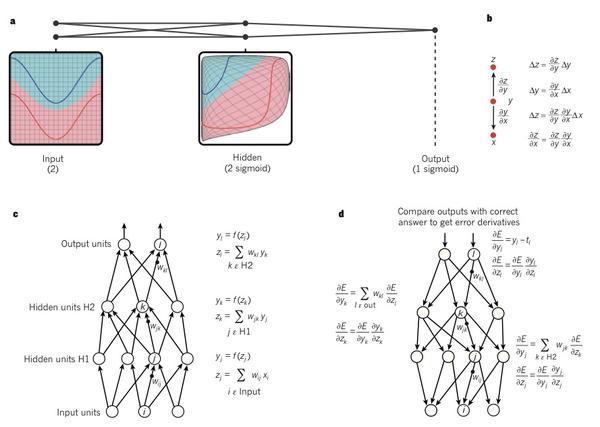
图1| 多层神经网路和反向传播
a. 一个多层神经网络(如图所示相互连接的点)能够整合(distort)输入空间(图中以红线与蓝线为例)让数据变得线性可分。注意输入空间的规则网格(左侧)如何转被隐藏单元(中间)转换的。例子只有两个输入单元、两个隐藏单元和一个输出单元,但事实上,用于对象识别和自然语言处理的网络通常包含了数十或成千上万个单元。(本节引用改写自 C. Olah (http://colah.github.io/).)
b. 导数的链式法则告诉我们,两个微小增量(即x关于y的增量,以及y关于z的增量)是如何构成的。x的增量Δx导致了y的增量Δy,这是通过乘以∂y/∂x来实现的(即偏导数的定义)。同样,Δy的变化也会引起Δz的变化。用一个方程代替另一个方程引出了导数的链式法则( the chain rule of derivatives),即增量Δx如何通过与∂y/∂x及 ∂z/∂x相乘使得z也发生增量Δz。当x,y 和 z都是向量时这一规律也同样适用(使用雅克比矩阵)。
c. 这个公式用于计算在包含着两个隐层和一个输出层的神经网络中的前向传输,每个层面的逆向传递梯度都构成了一个模组。在每一层,我们首先计算面向每个单元的总输入值z,即上一层的输出单元的加权和;然后,通过将一个非线性函数f(.)应用于z来得出这个单元的输出。为了简化流程,我们忽略掉一些阈值项(bias terms)。在神经网络中使用的非线性函数包含了近些年较为常用的校正线性单元(ReLU) f(z) = max(0,z),以及更传统的 sigmoid函数,比如,双曲线正切函数, f(z) = (exp(z) − exp(−z))/(exp(z) + exp(−z)) 和 逻辑函数f(z) = 1/(1 + exp(−z)).
d. 该公式用于计算反向传递。在每一个隐藏层中,我们都会计算每个单元输出的导数误差,即上述层中上一层所有单元输入的导数误差的加权总和。 然后,将关于输出的导数误差乘以函数f(z)的梯度(gradient),得到关于输入的导数误差。 在输出层中,通过对成本函数进行微分计算,求得关于输出单元的误差导数。因此我们得出结论 yl - tl 如果对应于单元l的成本函数是 0.5(yl - tl) 2 (注意tl是目标值)。一旦∂E/∂zk已知,那么,就能通过yj ∂E/∂zk调整单元j的内星权向量wjk。
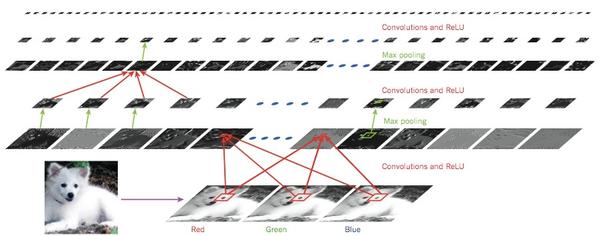
图2 | 卷积网络的内部



评论