Qt 集团宣布推出 Axivion for CUDA,该工具已加入英伟达 Halos AI 系统检测实验室,用于机器人与自动驾驶车辆的自动化安全检测。适用于英伟达 CUDA 的 Qt 集团安全软件工具该工具依据英伟达规范与行业标准,对 GPU/CPU 代码提供持续分析,并生成 Halos 审核验收所需的文档。Qt 集团表示,该工具还能提前发现问题,从而减少重新设计、加快产品上市速度,并降低召回风险 —— 召回事件会对企业造成经济与声誉双重损失。这家芬兰企业是英伟达检测实验室的最新合作伙伴。该实验室获得美国
关键字:
AI
检测工具
机器人
安全认证
Qt
CUDA
(图片来源:英特尔)来自 ATI Technologies、AMD、苹果和英特尔等公司的传奇 GPU 架构师 Raja Koduri 于周二表示,他成立了一家新的 GPU 初创公司,该公司今天从隐身模式中浮出水面。Oxmiq Labs 专注于开发 GPU 硬件和软件 IP,并将其授权给感兴趣的各方。事实上,软件可能是 Oxmiq 业务的核心,因为它设计为与第三方硬件兼容。另一款基于 RISC-V 的“GPU”用于人工智能Oxmiq 开发了一个垂直整合的平台,该平台结合了 GPU 硬件 IP 和面
关键字:
RISC-V
AI
GPU
CUDA
英伟达在前几天的RISC-V中国峰会上宣布了一项足以改写计算产业格局的决定:CUDA将全面支持RISC-V指令集架构。这一消息通过RISC-V国际组织的官方推文瞬间引爆全球技术社区。打破x86/ARM的二十年垄断CUDA作为英伟达统治AI计算领域的核心武器,自2006年问世以来始终被x86和ARM架构牢牢锁定。其生态壁垒如此坚固,以至于挑战者如AMD的ROCm平台虽经多年追赶,仍难撼动其地位(ROCm 7虽新近发布,但市场接受度仍远落后)。如今这一壁垒向RISC-V开放,意味着:技术主权转移:RISC-V
关键字:
英伟达
CUDA
RISC-V
指令集架构
(图片来源:英伟达)在中国举办的 2025 年 RISC-V 峰会上,Nvidia 宣布其 CUDA 软件平台将在 CPU 方面与 RISC-V 指令集架构(ISA)兼容。这一消息在 RISC-V 活动期间的一个演示中得到了证实 。这是在性能要求高的应用中启用基于 RISC-V ISA 的 CPU 的重要一步。这项宣布表明,RISC-V 现在可以作为基于 CUDA 系统的主处理器,这一角色传统上由 x86 或 Arm 核心担任。虽然没有人甚至几乎没有期望 RISC-V 在不久的将来出现在超大规模
关键字:
RISC-V
AI
英伟达
CUDA
第五届RISC-V中国峰会于2025年7月16至19日在上海张江科学会堂隆重举办,在峰会的圆桌讨论中,主持人曾经提出这样一个问题:你认为RISC-V未来会取代GPU吗?在现场观众投票中,支持会取代的现场观众占据将近半数。不过在随后的主题演讲中,英伟达副总裁 Frans Sijstermanns特别提到了英伟达在自家的计算平台实现了RISC-V应用处理器部署。 在做这次演讲准备的时候,Frans Sijstermanns会议自己参加过的由上海交通大学和英伟达联合举办的“2017年RISC-V工作坊
关键字:
英伟达
CUDA
RISC-V
中国峰会
4月20日消息,在发布重量级的MUSA SDK 4.0.1开发包之后,摩尔线程又同步带来了配套性能分析工具Moore Perf System的最新版本v1.3.0。Moore Perf System是摩尔线程SDK中的基础组件,用于辅助开发者进行开发调试,可以方便、快速、准确地定位到系统级别的性能瓶颈,进而进行针对性分析和优化,使程序性能满足需求。如果需要进一步分析计算类应用程序,请使用Moore Perf Compute。如果需要进一步分析图形类应用程序,请使用Moore Perf Graphics。主
关键字:
摩尔线程
cuda
AI
NVIDIA于近日宣布将通过开源的NVIDIA CUDA-Q™量子计算平台,助力全球各地的国家级超算中心加快量子计算的研究发展。德国、日本和波兰的超算中心将使用该平台来赋能他们由 NVIDIA 加速的高性能计算系统中的量子处理器(QPU)。QPU 是量子计算机的大脑,通过利用电子或光子等粒子行为进行计算,计算方式与传统处理器不同,有可能使某些类型的计算速度更快。德国于利希研究中心的于利希超算中心(JSC)正在安装一颗由IQM Quantum Computers公司制造的QPU
关键字:
NVIDIA
CUDA-Q
量子计算
3月26日,由高通、谷歌、英特尔等科技巨头联合参与的UXL基金会宣布,将启动一项开源软件开发计划,为多种AI加速器芯片提供跨平台支持,推动AI技术的普及和应用,有望为整个行业带来更加开放和灵活的发展环境。该项目旨在实现计算机代码在不同芯片和硬件平台上的无缝运行,消除特定编码语言、代码库和其他工具等要求,使开发人员不再受使用特定架构(如英伟达的CUDA平台)的束缚。高通AI与机器学习主管Vinesh Sukumar表示,“我们实际上是在向开发者展示如何从英伟达平台迁移出来”。据悉,UXL的技术指导委员会准备
关键字:
高通
谷歌
英特尔
UXL
开源
英伟达
CUDA
对于 x86、Arm、MISC 和 RISC-V 等处理器架构都有深入研究的传奇处理器架构师Jim Keller批评了被外界认为是英伟达(NVIDIA)“护城河”的 CUDA架构和软件堆栈,并将其比作x86,称之为“沼泽”。他指出,就连英伟达本身也有多个专用软件包,出于性能原因,这些软件包依赖于开源框架。 “CUDA 是沼泽,而不是护城河,”凯勒在 X 帖子中写道。“x86 也是一片沼泽。[…] CUDA 并不漂亮。它是通过一次堆积一件东西来构建的。” 确实,就像x86一样,
关键字:
英伟达
NVIDIA
CUDA
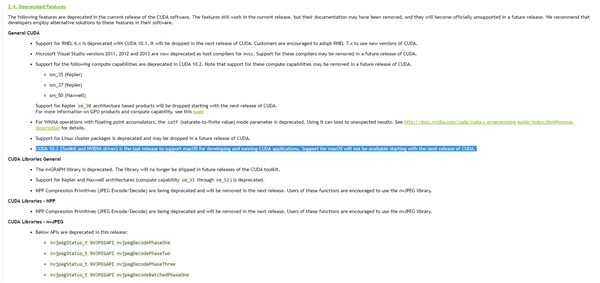
NVIDIA和苹果的关系一直很糟糕,十几年没有过合作,现在双方的最后一丝关系也破裂了。NVIDIA今天公布了CUDA并行计算开发平台的更新规划说明,其中特别提到,CUDA 10.2(包括工具包和驱动)将是最后一个支持苹果macOS系统开发、运行CUDA程序的版本,未来CUDA将与苹果平台无关。十多年前,一批采用NVIDIA GPU显卡的苹果MacBook Pro笔记本出现瑕疵,双方为此向客户赔偿了一大笔钱,并且闹得非常不愉快,从此苹果无论笔记本还是台式机,一律只用AMD显卡。即便是NVIDIA显卡更流行,
关键字:
英伟达
苹果
macOS
CUDA
0 引言在航空航天、医疗服务、地质勘探等复杂应用领域,需要处理的数据量急剧增大,需要高性能的实时计算能力提供支撑。与多核处理器相比,众核处理器
关键字:
众核处理器
CUDA
NVIDIA今天官方宣布,已经收购在高性能计算领域领先的编辑器和工具供应商The Portland Group (PGI)。
PGI是意法半导体旗下全资子公司,创立于1989年,在高性能计算编译器技术上拥有悠久的历史,客户包括Intel、IBM、Linux、OpenMP、GPGPU、ARM。
PGI与NVIDIA的合作也非常密切,已经携手五年,特别是在两年前推出了面向32/64位x86架构的CUDA C编译器,开启了CUDA x86之路。
NVIDIA表示,被收购后,PGI将保留原有
关键字:
NVIDIA
编译器
CUDA
电子产品世界,为电子工程师提供全面的电子产品信息和行业解决方案,是电子工程师的技术中心和交流中心,是电子产品的市场中心,EEPW 20年的品牌历史,是电子工程师的网络家园
关键字:
OpenGL
CUDA
像素缓冲
意法半导体全资子公司、全球领先的高性能计算(HPC)编译器供应商Portland Group宣布,性能优化的支持多核x86平台的PGI CUDA C/C++编译器(CUDA-x86)将于2012年1月与PGI 2012版共同上市发售。
关键字:
ST
编译器
CUDA-x86
当年一场场CPU革命把人类推上了IT列车,如今GPU正把火车换成飞机。而一直在IT方面不断追赶的中国,此次也搭上了头等舱。
近日,中国科学院和清华大学分别被授予CUDA卓越中心的称号,以表彰他们在利用GPU进行高性能计算的突出贡献,而亲自授予他们这个荣誉的正是GPU计算革命的发起者和主导者-----NVIDIA(英伟达)公司。
在双方眼中,GPU计算不仅是世界IT业的下一场革命,也是中国赢得IT奶酪的绝佳机会。
GPU取长CPU补短
在人们都习惯了“Intel In
关键字:
Nvidia
GPU
CUDA
意法半导体全资子公司、世界领先的高性能计算机(HPC)编译器提供商Portland Group®宣布与英伟达公司(NVIDIA)达成合作开发协议,两家公司计划为CUDA图形处理器(GPU)开发新的Fortran语言编译器。
NVIDIA® CUDA™架构让开发人员能够卸载计算机内核承担的繁重计算任务,把图形处理任务转交给并行性能出色的图形处理器。通过函数调用和语言扩展,CUDA架构能够让开发人员绝对控制通用计算内核到图形处理器的映射,以及数据在x64位处理器与图形处理
关键字:
ST
编译器
Fortran
CUDA
PGI
【赛迪网讯】7月3日消息,据国外媒体报道,英特尔高级副总裁帕特·基辛格(Pat Gelsinger)日前再度炮轰Nvidia,称Nvidia的CUDA技术无足轻重。
Nvidia CUDA技术是当今世界上唯一针对Nvidia GPU(图形处理器)的C语言环境,该技术充分挖掘出Nvidia GPU巨大的计算能力。凭借CUDA技术,开发人员能够利用Nvidia GPU攻克极其复杂的密集型计算难题。
英特尔高级副总裁帕特·基辛格日前却表示:“CUDA只是计
关键字:
英特尔
Nvidia
CUDA
GPU
cuda介绍
CUDA(Compute Unified Device Architecture),显卡厂商NVidia推出的运算平台。
CUDA?是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员现在可以使用C语言来为CUDA?架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序于是 [
查看详细 ]
关于我们 -
广告服务 -
企业会员服务 -
网站地图 -
联系我们 -
征稿 -
友情链接 -
手机EEPW
Copyright ©2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《电子产品世界》杂志社 版权所有 北京东晓国际技术信息咨询有限公司
京ICP备12027778号-2 北京市公安局备案:1101082052 京公网安备11010802012473