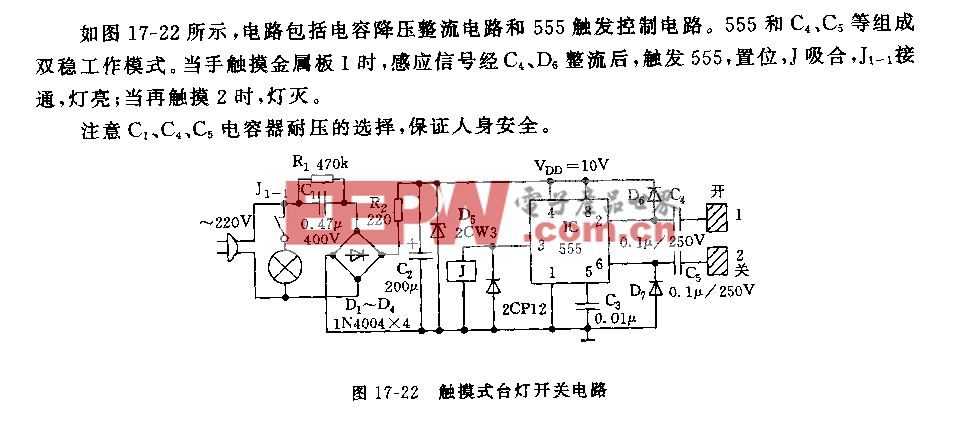
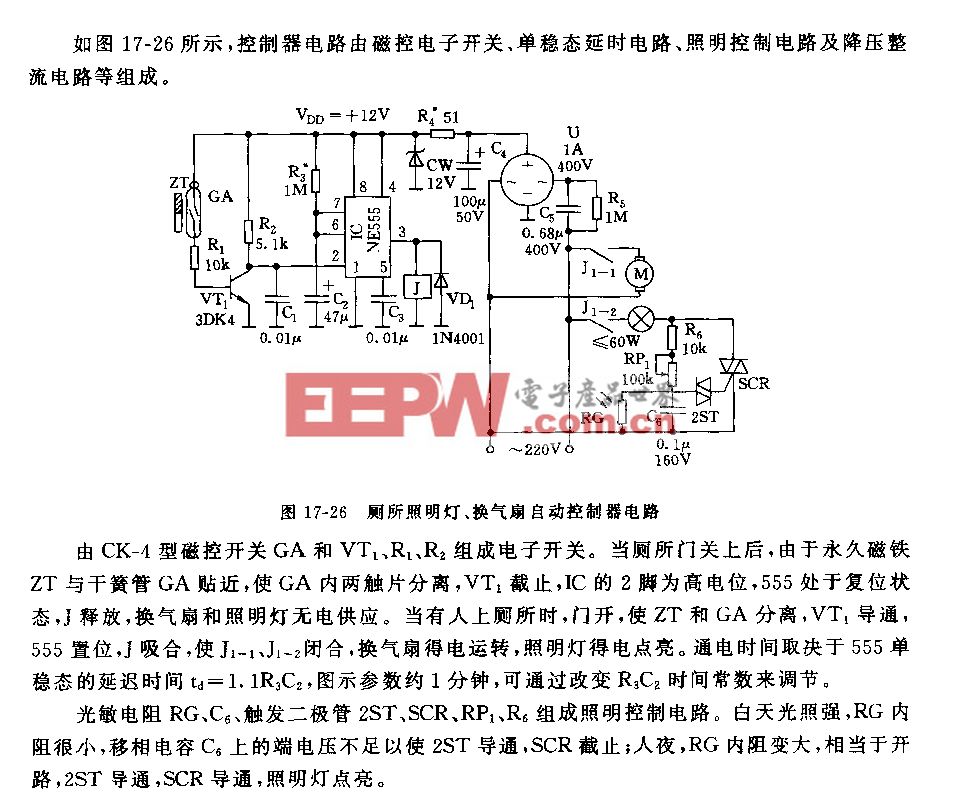
网络处理器Intel IXP1200应用

随着网络规模和接口速度的增加,基于通用RISC技术的网络设备无法在性能上满足线速处理要求;另一方面新的网络通信协议、标准不断出现或变化,用户的需求也在不断变化之中,使得数据通信产品的更新换代周期迅速缩短。在这种背景下,网络处理器(Network Processor,NP)为下一代通信产品的设计提供了一种灵活的解决方案。
网络处理器是一种专用于网络通信设备的通用芯片,是一种开放式的、多样化、可编程的开发环境,允许不同的设备供应商采用同样的芯片制造出各自不同功能和特色的网络设备。网络处理器芯片专门针对通信功能进行了优化,综合了RISC芯片和ASIC的优点——既像RISC可以软件编程、提供足够的灵活性来适应数据通信市场高速的发展,又具有ASIC那样的高性能,但又不象ASIC那样需要长达12个月的开发周期。通过下载不同的程序,同样的硬件平台可以支持Vlan交换机、路由器、宽带接入服务器、NAT、防火墙、WEB交换机等,支持各种速率的以太网、ATM、POS等接口,升级非常方便。
目前提供NP的主要厂商有Agere、Intel、IBM、Maker/Conexant、MMC、Motorola等。IXP1200网络处理器是Level-One公司(现属Intel)的拳头产品。
IXP1200由7个RISC处理器、外部存储器接口、IX总线接口以及PCI总线接口等封装于1个芯片上构成。7个RISC处理器当中有6个为包作业处理引擎以及1个管理/控制包作业处理引擎的“StrongARM”核。图1为IXP1200结构图。
IXP1200主要包括以下组件:
1.6个集成的32位可编程微引擎,工作频率可达200MHz,每个引擎可支持四个线程,每个线程有独立的程序计数器;
2.集成有Intel StrongARM 32位处理器(RISC)核,16K指令缓冲,8K数据缓冲,512字节的一次性临时数据缓冲,写缓冲,内存管理单元;
3.高带宽4.2Gb/s 的I/O总线;
4.集成的32位,66MHz PCI总线接口。
网络处理器的最大特点是可编程性,因此开发重点由硬件转向软件。IXP1200平台上的软件按运行位置可分为两部分:StrongARM核上运行BSP、驱动程序、实时操作系统、路由表维护及上层应用程序,使用标准C语言开发;微引擎进行数据流输入/输出、打包/拆包、分类、快速查表、转发等实时要求非常苛刻的处理。每个微引擎包含一段可编程的控制存储器区(1024×32bit,1K条指令),用以存储微码程序。微引擎中的四个线程共享该控制存储器。微引擎编程使用一套专为网络数据流处理应用定制的指令集,去掉了通用RISC芯片中对协议及包处理用处不大的部分,同时保留了RISC指令长度一致、单周期执行时间、易于并行和流水线处理等优点。
微引擎目前可以使用33条基本指令,大部分指令可以有不同执行选项,合理组合使用可以达到最高性能。指令集合按功能可以分为如下五类:算术逻辑运算、移位类;分支及跳转类;访问类指令;本地寄存器操作;杂类指令。
Intel鼓励使用宏风格的编程方式,提供了一套宏库,大大提高了编程效率及软件可维护性。
IXP1200是通过硬件和软件的并行开发来缩短开发周期的。Intel免费提供了一个完全集成的开发环境Developer Workbench用于微码编程、符号汇编、链接、仿真、调试、性能分析等,使用界面类似微软的Visual C++。一个完整的工程包括:工程文件、微码源程序文件、宏库、调试脚本、生成映象文件的汇编及链接设置、仿真外围器件或ARM应用程序的外部DLL等。相比常见的集成开发环境,其仿真模拟器和扩展外部模块比较有特色。
IXP1200编程最大的挑战在于利用其微引擎硬件多线程处理特性,充分利用现有存储器带宽,从而满足高速处理要求。设计者需要折衷考虑硬件高速处理和软件灵活性,主要围绕优化数据处理性能,包括数据包分类、指令效率、数据管理、控制通道和数据通道隔离、查表加速,还有存储器容量和可扩展性等方面。下面总结一些提高处理性能的经验。
1、程序结构组织及线程资源的合理分配使用;根据具体应用处理要求,在设计中可以将线程分为接收调度、接收、发送调度、发送、包处理等线程。各个微引擎进行相应的分工,使其协同工作,性能最优,同时使各个阶段的处理相对独立,功能模块化,程序结构清晰。
2、不同内存资源的灵活使用:SRAM读写速度快,但价格高配置容量小,一般用于使用频繁的索引表、队列等;SDRAM容量大,主要作为包缓冲区、大的复杂数据区;SCRATCH暂存区作为片内小容量的存储区。
3、灵活运用指令选项进行优化:微码指令通常按五级流水线方式执行,当执行管道被指令填满时,则每个指令周期都将有一条指令完成,但分支指令、跳转指令、上下文切换指令等会引起执行管道中的指令异常退出,从而导致微引擎效率降低。解决方法是巧妙安排指令执行顺序,使用优化选项。
后延分支(Defer)的目的在于减少或消除执行管道中的异常退出指令。在后延分支中,紧跟在分支决定后的指令可以在分支生效前执行。如果在分支指令后可找到有用的工作来填充浪费的指令周期,则分支引起的等待时间就可隐藏起来。
猜测分支(Guess Branch)可选标识允许在实际的分支决定作出之前,从分支路径上预取指令。因此为使程序管道指令运行效率更高,在编程中应注意分支指令周围的指令安排:适当使用deferred branch,在分支指令后面安排一些指令以填充指令执行管道;用于分支决定的条件代码应尽早确定;根据处理器的猜测分支逻辑安排分支语句,并适当地加上分支可选标识。
在读写SRAM、SDRAM类指令后可用ctx_swap选项,使得访问存储器的延时可以被其它线程利用。同样在一段较长的处理过程中加入ctx_arb[voluntary]让其它线程有机会运行。
4、尽可能使用高效率的算法:
微引擎包处理很大一部分工作(如路由查找、过滤匹配)需要进行各种查表处理,采用高效的查找算法可以提高处理性能。如使用IXP1200硬件HASH功能一次可以计算出三个键值,多项式HASH算法中用到的乘子多项式值可以根据分布特点选取以得到最佳的HASH结果,减少冲突概率。■
参考文献
1 IXP1200 Network Processor Datasheet
2 IXP1200 Network Processor Hardware Reference Manual
3 IXP1200 Network Processor Programmer's Reference
4 IXP1200 Network Processor Software Reference Manual

c++相关文章:c++教程








评论