深度剖析英伟达 Blackwell 架构:张量核心、PTX 指令、SASS、晶圆良率与 GPC 布局

英伟达数据中心级Blackwell GPU(SM100)迎来了数代以来幅度最大的 GPU 微架构革新之一,然而官方至今并未发布详细的技术白皮书。截至目前,面向 AI 负载、针对 UMMA、TMA 等 PTX 与 SASS 指令开展的公开布莱克威尔架构微基准测试研究仍属空白。
继《英伟达张量核心演进:从伏特到布莱克威尔》深度文章之后,半导体分析机构SemiAnalysis 投入了数月工程时间,深入剖析布莱克威尔架构并实测原始 PTX 指令性能,以此确立严谨的实际性能上限,并与理论峰值进行对比。我们旨在揭示计算单元与指令级的硬件吞吐和延迟极限,从机器学习系统与内核开发的角度提供一份实用的性能刻画。测试重点围绕深度学习负载配置展开,例如对主流深度学习库 FlashInfer 中采用的异步内存拷贝方案进行基准测试。
布莱克威尔架构特性
从霍珀(Hopper)到布莱克威尔(Blackwell),英伟达对架构进行了多项增量改进,并针对与 MMA 相关的指令调整了 PTX 抽象层。我们在《英伟达张量核心演进》一文中已介绍过其中大部分内容。以下是主要的显著变更:
- 1 引入张量内存(TMEM) 用于存储 MMA 累加器。线程不再隐式持有 MMA 运算结果,转而由软件在 MMA 作用域内对 TMEM 进行显式管理。
2 tcgen05操作现在由单个线程代表整个 CTA(线程块)发起,而非前代架构中以线程束(warp)或线程束组(warpgroup)为单位。这一点在 CuTe 的 MMA 原子操作中体现明显:布莱克威尔使用 ThrID = Layout<_1>,而霍珀基于线程束组的 MMA 则使用 ThrID = Layout<_128>。
- 3 支持TPC 级别的 TMA以及成对协作 CTA 之间的 MMA,在 PTX 中以 cta_group::2、在 SASS 中以 2CTA 形式暴露。组成一个 TPC 的两个 SM 可基于共享操作数执行 tcgen05.mma,通过降低单个 CTA 对共享内存(SMEM)的带宽需求,实现更高运算强度的 MMA 指令。后文将证明,这种操作数共享是充分释放 MMA 吞吐能力的必要条件。
- 4 原生支持带微缩放(micro-scaling)的子字节精度数据类型。
- 5 集群启动控制(CLC):为持久 CTA 内核中的动态任务调度提供硬件支持(将在后续文章中详解)。
- 6 程序化依赖启动(PDL) 在霍珀架构中已引入,用于消除连续内核间的启动与初始化延迟(将在后续文章中详解)。
集群、GPC 与晶圆良率布局
自 Hopper 架构开始,英伟达数据中心 GPU 就支持一项可选特性,它有多个名称:线程块集群、CTA 集群、协作网格阵列(CGA),这些名称均指向同一功能。集群是 CTA(线程块)的逻辑分组,其形状与大小可按每个内核静态或动态指定。编程模型能感知到集群的存在并实现一些实用功能,例如支持向同一集群内的多个 CTA 执行组播加载—— 我们会在本文后续的 TMA 组播章节详细讲解。
至关重要的一点:同一个集群内的所有 CTA,保证会在同一个 GPC(图形处理集群)上协同调度。这一点对 Blackwell 采用 “单 SM 绑定单个 CTA” 的持久 CTA 内核模式至关重要:如果集群大小无法整除 GPC 内的 SM 数量,就会导致部分 SM 闲置。
这一机制很容易让内核开发者困惑:如果不了解文档记载较少的 GPC 机制,开发者往往会简单地按 GPU 总 SM 数量启动持久 CTA 并开启集群功能,最终导致部分 CTA 只能串行执行。
每个 GPC 最终可用的 SM 数量并非固定值;同一块芯片上不同 GPC 之间可用 SM 数量不同;甚至同一封装内的不同裸片之间,可用 SM 布局也可能不对称。
原因是半导体制造过程中会产生缺陷,这些缺陷可能随机出现在芯片的任何位置。因此,英伟达必须通过架构设计,让这些存在缺陷但仍可工作的单元,以相对统一的方式暴露给软件使用。
我们通过启动不同大小的集群,并利用 PTX 指令中的%%smid记录哪些 SM 被分配到同一个 GPC,以此逆向推导出 SM 到 GPC 的映射关系。
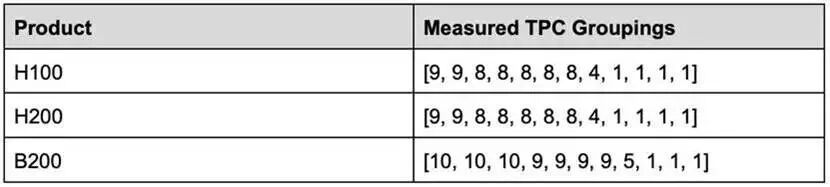
最终得到了 TPC 到 GPC 的逻辑分组列表。这个列表的长度超过了 Hopper/Blackwell 标配的 8 个 GPC,原因是部分 TPC 会独占一个逻辑 GPC,永远不会与其他 TPC 协同调度。
从 SM100 架构开始,英伟达针对这种量化分配问题提供了解决方案,使内核既能享受大集群带来的性能优势,又能充分利用所有可用的 SM 计算单元。启动内核时可指定两种集群尺寸:优选集群尺寸与降级集群尺寸。通常情况下,为了完全利用整个 GPU 资源,降级集群尺寸应设置为 2 或 1。
参考资料:
- 集群 API
- 协作组 API
CU_LAUNCH_ATTRIBUTE_PREFERRED_CLUSTER_DIMENSION
CUTLASS
示例 73
逻辑 GPC 与物理 GPC
我们上文展示的 TPC 到 GPC 的分组属于逻辑分组。它们仅代表软件视角下的 GPC 结构,不包含每个 GPC 内部20 个实际物理 SM 中哪些处于启用状态的信息,也不体现每个物理 GPC 在双裸片上的具体位置。
事实上,即便逻辑配置完全相同的 B200 芯片,每个 GPC 中最终可用的物理 SM 数量也不一定完全一致。这可能导致在软件视角看起来完全相同的 GPU 之间,出现性能不确定性的问题。此外,SM 到 GPC 的逻辑分组信息,也无法区分 B200 封装内的两个裸片分别搭载了哪些 GPC。
为了探明 SM 物理布局的更多细节,我们让每个 SM 遍历一个指针追踪数组以填充 L2 缓存,并测量每次加载操作的延迟。针对每个内存地址,我们对比不同 SM 观测到的加载延迟,最终生成SM 与 SM 之间的距离矩阵(X 轴和Y 轴均为 SM ID)。
关键术语注释
quantization issue
(量化分配问题)
集群大小无法整除 GPC 内 SM 数量,导致 SM 闲置的问题
preferred cluster size / fallback cluster size
优选集群尺寸(高性能优先)/ 降级集群尺寸(兼容性 / 满资源利用优先)
logical GPC / physical GPC
逻辑 GPC(软件看到的分组)/ 物理 GPC(芯片实际硬件布局)
pointer-chase array
指针追踪数组,用于精准测量缓存访问延迟的经典测试方法
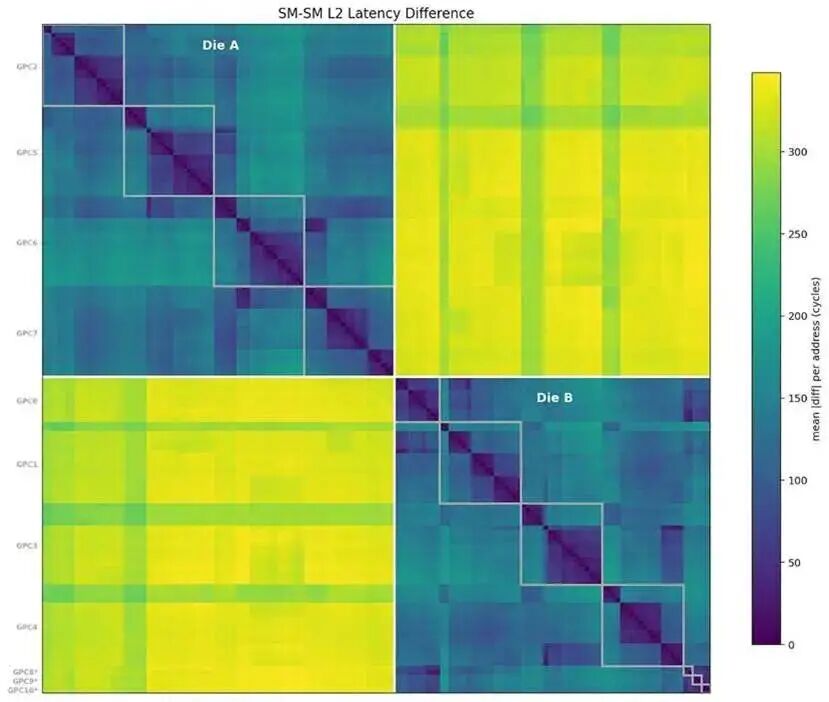
我们可以清晰地看到两组独立的 SM 集群,它们之间的 L2 平均访问延迟相差超过 300 个时钟周期—— 这显然就是裸片间(die-to-die)通信的分界。
我们同时用上一节得出的逻辑 GPC 分组对 SM 进行了标注;有趣的是,独立独占的 TPC在延迟上彼此非常接近,且在本次测试中与 GPC0 高度关联,因此可以推测这些 TPC 在物理上就位于 GPC0 内部。
基于这些数据,我们可以进一步修正每个 GPC 实际可用的 TPC 数量列表,不过其中 5+3 的划分仍属于推测。
- 裸片 A:[10, 10, 10, 9]
- 裸片 B:[9, 9, 9, 5+3]
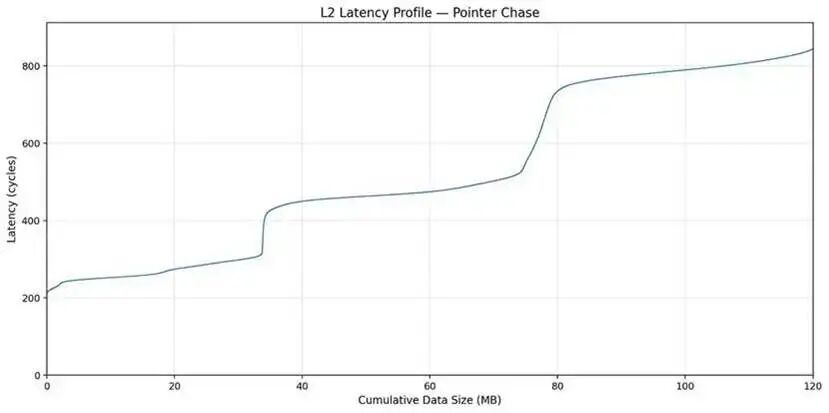
此外,尽管测试方式较为间接,我们仍可得出结论:裸片间访问的延迟开销大约为 300个时钟周期。
这一点在单个 SM 的延迟曲线中也同样明显(曲线中同时包含了大量 L2 拥塞带来的影响)。
在此特别感谢 Decart AI 的Orian 为本次基准测试提供思路启发。
存储子系统
本节我们介绍存储子系统,也就是在各个计算单元之间搬运数据的硬件单元。内存拷贝指令是使用存储子系统的核心操作,而新一代架构中引入了异步拷贝指令(关于异步机制的演进可参阅前文)。我们重点关注两类异步拷贝指令:LDGSTS和 TMA(张量内存加速器)。
异步拷贝
异步拷贝(PTX:cp.async,SASS:LDGSTS)从安培(Ampere)架构开始引入,该指令可将数据从全局内存异步搬运到共享内存。
异步拷贝是非阻塞的,允许内存加载与计算操作并行执行。它还能直接写入共享内存,无需经过寄存器,从而降低寄存器占用压力。
参考 FlashInfer 的多头注意力(MHA)内核,我们采用以下配置对异步拷贝进行基准测试:
- 每个 SM 的 CTA 数量:1、2、3、4
- 流水线级数:1、2、4
- 每个 CTA 的线程数:64、128、256
- 加载粒度:4B、8B、16B
我们绘制了吞吐率与每个 SM 的飞行字节数(即并发内存加载指令正在传输的总字节数)的关系曲线。
尽管不同加载粒度在相同飞行字节数下最终能达到相近的吞吐率,但我们更推荐使用 16字节加载。
在相同飞行字节数下,16 字节加载能实现略高的吞吐,同时占用更少执行资源。例如,在 32 KiB 飞行字节时,8B 加载需要 4 级流水线,而 16B 加载仅需 2级。这可以节省两个内存屏障对象所需的存储空间,并降低指令发射压力。
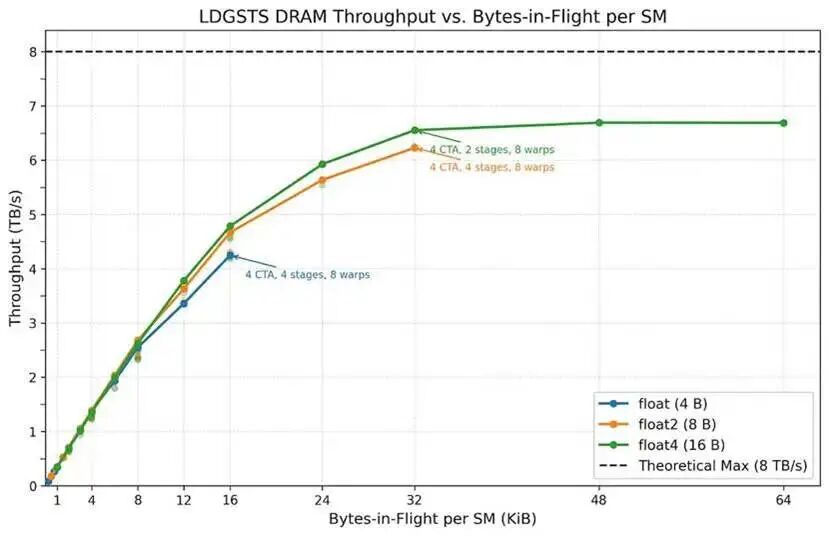
整体来看,LDGSTS在 32 KiB 飞行字节数下即可达到饱和,内存吞吐约 6.6 TB/s。
我们还针对实际 MLA(多层潜在注意力)内核常用的配置做了基准测试:
- 每个 SM 1 个 CTA
16
字节加载- 每个 CTA 线程数:64、128、256
- 流水线级数:4、8、12、16
实验表明:增加流水线级数能在更高飞行字节数下获得更高吞吐;而提高单个 CTA 的线程数,在所有配置下都能稳定提升性能。
有意思的是,MLA 内核采用 2 个线程束(warp)+ 12 级流水线,实测吞吐约 2.2 TB/s。我们认为原因在于:执行 softmax 的线程束需要占用大量寄存器,增加线程束数量会导致单个线程可分配的寄存器减少,从而限制性能。

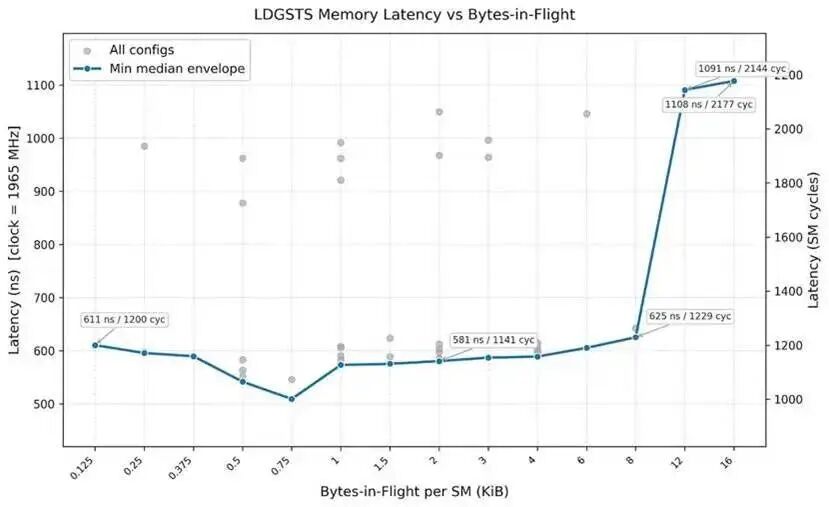
我们对同一组配置进行了延迟测试。结果显示:
LDGSTS的基线延迟约为600 纳秒,并且在飞行字节数超过 8 KiB 后,延迟几乎翻倍。
原因在于,为了让 LDGSTS 达到高飞行字节数,需要启用大量线程,这会导致大量线程束(warp)因 MIO(内存输入输出)节流 而阻塞。

张量内存加速器(TMA)
TMA(PTX 指令:cp.async.bulk.tensor,SASS 指令:UTMALDG)是在 Hopper 架构中引入的异步数据拷贝引擎,专门用于将大量数据从全局内存搬运到共享内存。只需单个线程即可发起 TMA 操作,完成地址生成、内存交织(swizzling)与越界处理,从而让其他线程可以执行独立任务。
本节我们以 2D 张量版本(cp.async.bulk.tensor.2d)为代表,测试 TMA 的典型使用场景性能。
参照 FlashInfer 注意力内核的设置,我们对 TMA 进行基准测试:每个 SM 只分配一个 CTA,每个 CTA 使用 1~4 个线程束(warp)中的各一个线程,来发起不同块大小的 TMA 指令。下图展示了每种飞行字节数下的最佳吞吐表现。
本次 TMA 测试配置如下:
- 每个 SM 的 CTA 数量:1
- 每个 CTA 的线程数:128(4 个线程束)
TMA
块维度:2D 尺寸从 32×8 逐步增大到 128×128
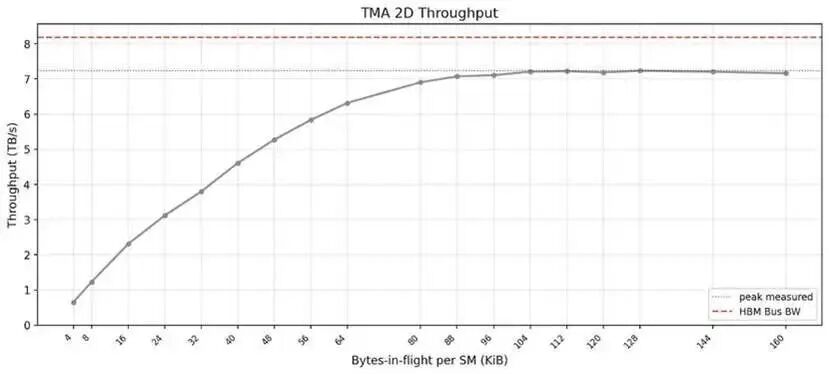
TMA达到峰值吞吐的时机,要比 LDGSTS晚得多。
异步拷贝与 TMA 对比
像 FlashInfer 这样的深度学习内核库会同时使用 TMA 和异步拷贝来加载数据。
TMA与异步拷贝具有不同的性能特点:
TMA
适合规则访问模式下的大块数据加载,但延迟更高;- 异步拷贝则能处理不规则内存访问模式,但存在大小限制。
我们会说明在不同场景下该如何选择。本节针对 FlashInfer 在 MHA 和 MLA 内核中实际使用的配置进行了基准测试。
可以看到:
- 吞吐方面:飞行字节数小于 32 KiB 时,异步拷贝略优于 TMA;超过之后 TMA 迎头赶上,并且能一直扩展到 128 KiB。
- 延迟方面:飞行字节数小于 12 KiB 时,异步拷贝延迟略低于 TMA;超过之后 TMA 延迟会大幅上升。


在实际应用中,Blackwell 的MLA 内核使用异步拷贝来动态加载页数据,而 MHA 内核则仅使用 TMA。
FlashInfer中大部分Blackwell MHA 内核均由 TRT-LLM 贡献,因此我们只能通过反汇编二进制文件来推测内核逻辑。我们发现,与 Hopper 类似,所有 Blackwell TRT-LLM 内核都使用 TMA。我们推测,在动态页加载场景下,这些内核沿用了 Hopper 的设计思路:使用4D TMA,将页索引作为最后一维,并在需要时通过 TensorMap 进行索引寻址。
为了弄清这些内核的确切实现机制,我们呼吁英伟达开源 FlashInfer 中的 TRT-LLM 内核,以惠及整个社区。
TMA组播(Multicast)
TMA支持组播模式:单次加载操作可将数据拷贝到多个 SM 的共享内存中,目标范围由 CTA 掩码指定。
组播常用于 GEMM 类计算模式 ——多个 SM 处理不同输出分块时,输入分块可在 SM 间共享。例如在 SwiGLU 激活函数中,两个 GEMM 操作共用同一个输入矩阵,组播就非常适用。
其核心优势在于:
- 减少 HBM 读取,降低有效带宽占用;
- 显著减少 L2 流量,因为多个 CTA 对共享数据的请求会被合并为一次请求。
根据 NCU 分析,负责处理 TMA 组播请求的硬件单元称为L2 请求合并器(LRC):
L2请求合并器(LRC)处理到达 L2 的请求,并在转发至 L2 缓存前尝试合并读请求。
该单元同时处理来自 SM 的可编程组播请求,并支持写入压缩。
这意味着即便不显式启用组播,硬件也可能自动表现出类似组播的行为,类似于缺失状态保持寄存器(MSHR)的机制。
为验证这一点,我们运行了同一套 TMA 组播基准测试,但改为所有 CTA 对同一块数据发起独立 TMA 加载,而非由单个 CTA 执行组播加载。
我们对比了三种场景:
- 每个 SM 加载不同数据(基准场景)
TMA
显式组播 —— 每个集群中一个 CTA 向集群内所有 CTA 执行组播加载TMA
隐式组播 —— 每个集群内所有 CTA 对同一块数据执行普通 TMA 加载
TMA组播能够提供极高的加载带宽以填充 SMEM 缓冲区,即便数据尚未缓存到 L2 中也是如此。
对于已知的流量模式,显式 TMA 组播指令可以完全消除冗余 L2 流量,实现理想的 “每字节 SMEM 数据对应 1 / 集群大小 的 L2 数据流量”。
我们还观察到,在这一简单测试中,显式与隐式模式下 SMEM 填充带宽几乎一致。但 LRC 并非完美:隐式模式下 L2 仍会产生略多的流量,尤其在总数据量增大时更为明显。
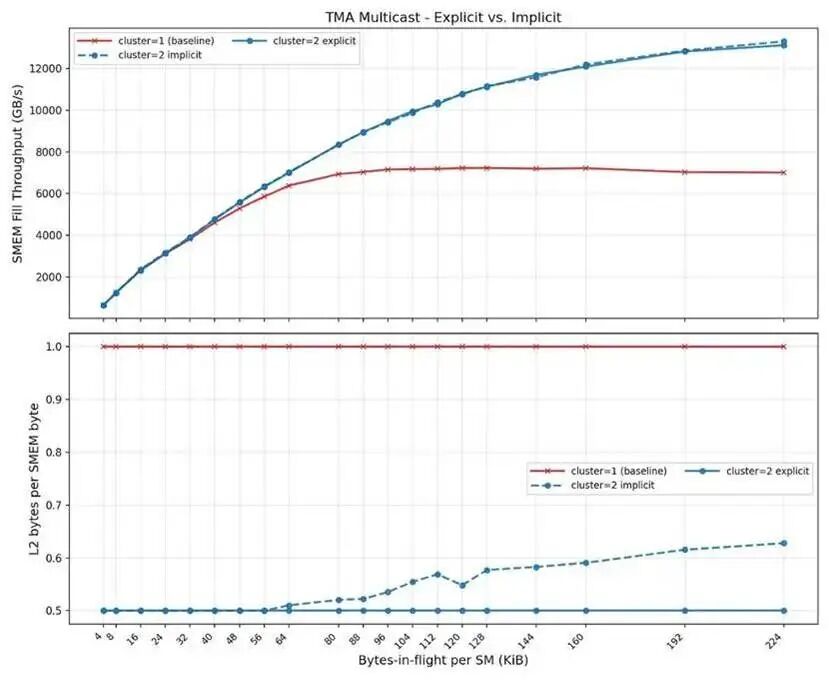
在有效内存吞吐方面,隐式组播与显式组播表现相当。但在降低 L2 缓存流量上,当飞行字节数超过 64 字节后,隐式组播的效果就会明显下降。
分布式共享内存(DSMEM)与本地共享内存(SMEM)对比
英伟达在 Hopper 架构中引入了分布式共享内存(DSMEM)。DSMEM 允许同一个集群内的线程块(CTA)互相访问彼此的共享内存,这对CTA 间归约等计算模式非常实用。但通过 DSMEM 读取对等 CTA 内存的吞吐率,远低于本地 SMEM 每时钟周期 128 字节的峰值。
我们测试了多种访问 DSMEM 的PTX 指令模式。在编写代码时,DSMEM 与 SMEM 存在一个关键区别:
DSMEM的加载操作是以数据包形式传输的,与全局内存加载类似。因此,DSMEM 的最优访问模式并非本地 SMEM 中避免存储体冲突的交错访问,而是更像全局内存(GMEM)中典型的连续合并访问。
此外我们发现,若要让本地 SMEM 达到 128 字节 / 时钟的峰值吞吐,必须使用不带 ::cluster 修饰符的 ld.shared 指令。
我们在编写基准测试时就踩过这个坑:直接用 ld.shared::cluster 访问本地和远程共享内存,结果无法达到峰值。
- 使用 ld.shared 时,编译器会生成专用的 LDS 指令;
- 而使用 ld.shared::cluster 时,编译器只会生成通用的 LD 指令,无法让本地 SMEM 跑出峰值性能。
我们还发现,ld.shared::cluster 很难进一步提升吞吐;只有切换为cp.async.bulk(PTX)/ UBLKCP(SASS) 后,才能通过单指令搬运更大数据量,让 DSMEM 吞吐获得小幅提升。
以下是我们使用不同 PTX 模式测得的峰值吞吐,单位为字节 / 时钟周期(B/clk),便于与本地 SMEM 的理论最大值对比。

第五代张量核心 MMA
MMA指令是执行矩阵乘法的核心操作。从 Hopper 到 Blackwell,MMA性能对矩阵形状的依赖性变得越来越强。
本节我们将深入研究这一现象,通过遍历不同形状与数据类型,量化分析性能差异。
Blackwell新增了 2SM MMA这一全新类型的 MMA 指令(cta_group::2):一对 CTA 会跨两个 SM 协同执行一次 MMA 运算。
具体来说,输入矩阵 A 会被复制,矩阵B 和矩阵 D 则在两个 SM 间分片,并且这对 CTA 可以互相访问彼此的共享内存。这使得更大规模的 MMA 形状成为可能。
我们将测试 2SM MMA 是呈现弱扩展、强扩展,还是两者兼具。
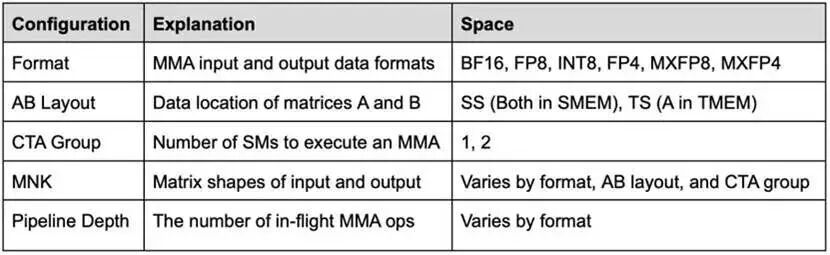
我们使用以下配置空间对 MMA 性能进行基准测试:
吞吐性能
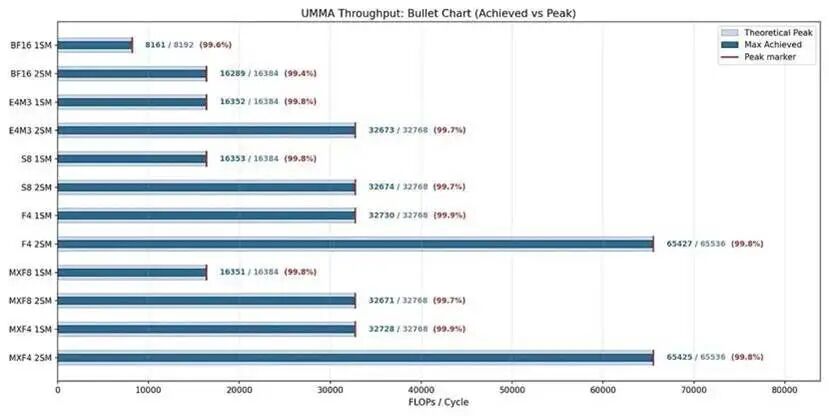
英伟达针对不同输入数据类型给出了官方标称吞吐指标,本节我们将展示各类(数据格式 + CTA 组)的官方指标,并与实际可达到的最大吞吐进行对比。
结果表明,UMMA 在所有格式与CTA 组配置下均能实现接近理论峰值的吞吐,即便在需要协同开销的 2SM 版本上也是如此。
吞吐性能
在所有 N 尺寸下的 1SM MMA 配置中可以看到:较小的 M=64 仅能达到理论峰值吞吐的 50%,而更大的 M=128 则能接近 100%。这证实 M=64 只利用了一半的数据通路。
在 2SM MMA 上,M=128 在 N=64 时吞吐约为峰值的 90%,在其余所有 N 尺寸下均接近 100%。M128N64的吞吐瓶颈应来自 TMEM、L2、SMEM 等其他硬件单元。
与此同时,M=256 在所有配置下都能稳定保持接近 100% 的峰值吞吐,原因是 M=256 对应每个 SM 分摊 M=128,可完整利用数据通路。
我们还发现:相同位宽的数据格式,吞吐表现完全一致;采用微缩放的数据类型几乎没有额外开销。

MMA的两种 AB 布局
MMA支持两种不同的 AB 矩阵存储布局:
SS
布局:两个输入矩阵都存放在共享内存(SMEM)中TS
布局:矩阵 A 存放在张量内存(TMEM)中,矩阵 B 存放在共享内存(SMEM)中
我们观察到,当 M=128时:
TS
布局在所有 N 尺寸下都能达到接近峰值的吞吐;SS
布局在 N 较小时性能偏低,直到 N=128时才追平峰值性能。
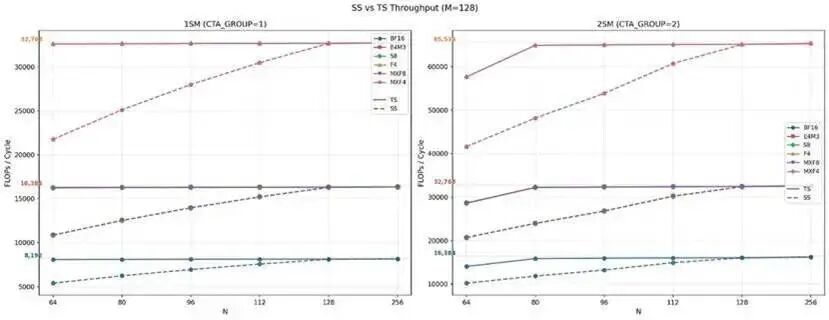
我们可以证实,SS 模式下当 N< 128 时,指令本身会受到 SMEM 带宽的限制。
举个例子,对于 FP16 精度:
我们知道每个 SM 每周期硬件可执行 8192 MMA FLOPs,而 SMEM 带宽为 128 字节 / 周期(每 SM)。
以 M=128、N=64、K=16为例:
A
矩阵字节数 = 2 × M × K = 4096 字节B
矩阵字节数 = 2 × N × K = 2048 字节- 浮点运算量 FLOPs = 2 × M × N × K = 262144
SMEM访问周期 = (A_bytes + B_bytes) / 128 = 48 周期
计算周期 = FLOPs / 16384 = 32 周期
我们逐步增大 N 并计算后发现:
只有当 N ≥ 128 时,指令才真正进入计算瓶颈阶段。
简单总结
N < 128
:受限于共享内存(SMEM)带宽,算力跑不满N ≥ 128
:受限于计算单元算力,达到理论峰值
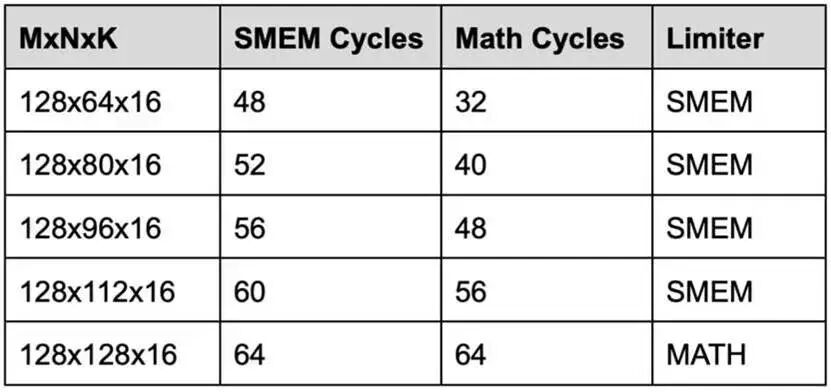
其他数据类型也是同理 ——两个操作数都放在 SMEM 中的 MMA 指令,在 N 小于 128 时均受 SMEM 带宽瓶颈限制。
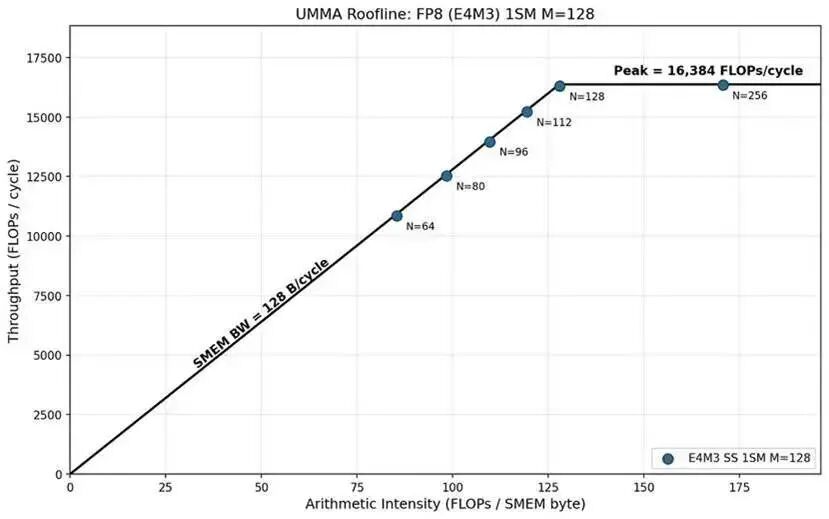
为进一步说明这一点,我们绘制了 FP8 精度下 1SM MMA 所有形状的屋顶线曲线。
可以清晰看到:N < 262 时处于内存受限区域,曲线斜率约为128 字节 / 周期,正是 SMEM 的带宽上限。
2SM MMA在所有数据格式与矩阵形状下均实现了完美的弱扩展:相比 1SM MMA,在计算资源翻倍的情况下,加速比也恰好达到 2 倍。
而在 SS 布局的小形状矩阵中,我们甚至观察到超过 2 倍的加速比。原因依然是:SS 模式下 N<128 时指令受 SMEM 带宽瓶颈限制,而 2SM 版本会将操作数 B 分摊到两个SM 上,从而缓解了带宽压力。

SS模式:当 N < 128 时,由于受 SMEM 带宽瓶颈限制,加速比超过 2 倍。
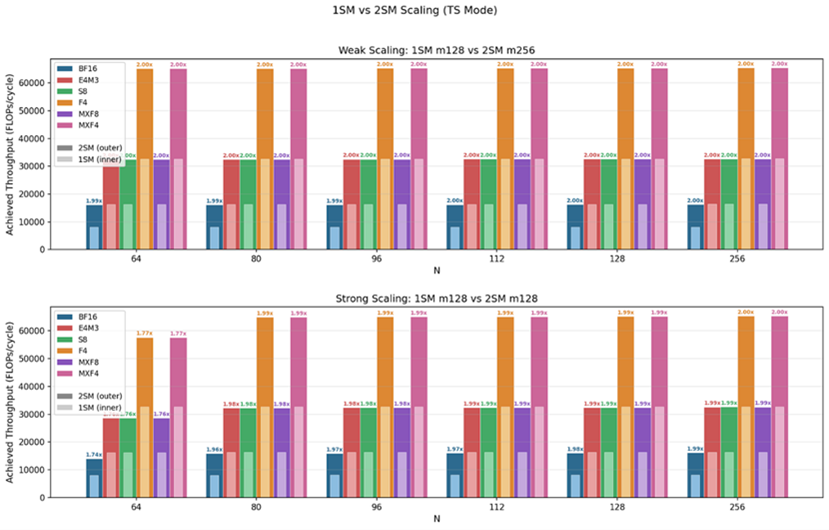
TS模式:接近完美的2 倍加速。
这些实验表明:在给定的 SMEM 分块大小下,想要获得最大吞吐,应始终使用尽可能大的指令形状。
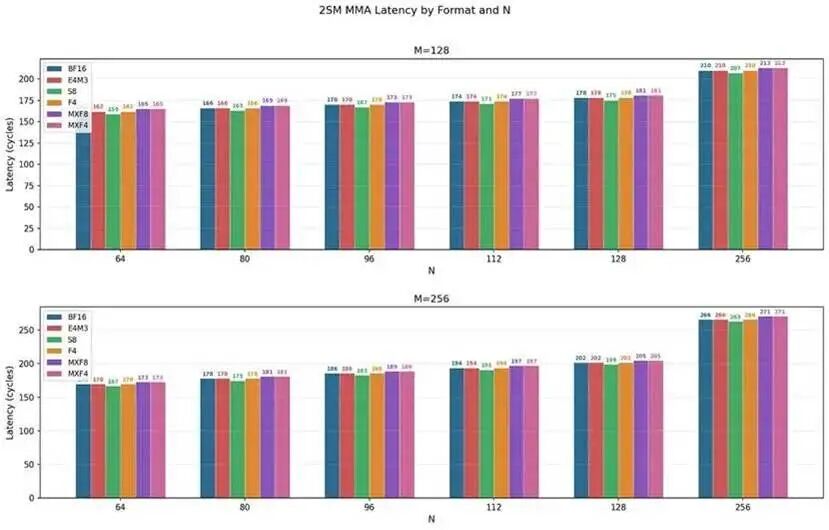
延迟
我们对单条 MMA 指令的延迟进行了基准测试,并在下图中对比展示。
在所有配置下可以看到:延迟从 N=64 到 N=128 呈线性上升,而在 N=256 处出现明显陡增,这很可能是因为矩阵维度从 128 跃升到 256 所致。
在单个 CTA 组的 MMA 中:
1SM MMA
的 M=64 和 M=128 在各 N 尺寸下延迟相近;2SM MMA
中,M=256 的延迟增长略快于 M=128,这与我们的理论估算一致。
对比不同数据类型可见:
1SM MMA
下差异很小;2SM MMA
下则出现明显的延迟分化。

我们观察到一个细微但稳定的延迟排序规律:
S8 < BF16 = E4M3 = F4 < MXF8 = MXF4
我们认为,整数运算能效更高,使得 S8 速度最快;而 MXF8 和 MXF4 因为需要额外计算缩放系数,引入了少量开销。
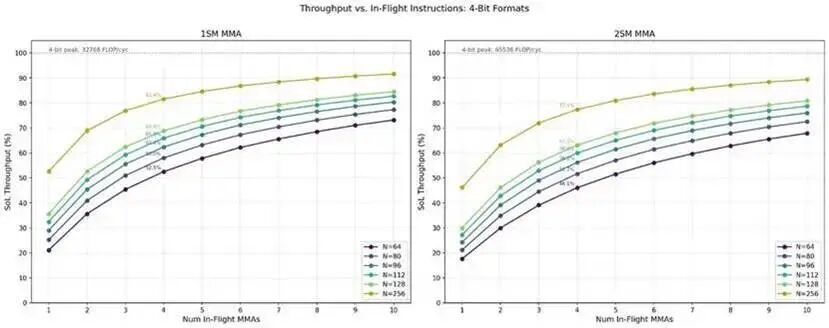
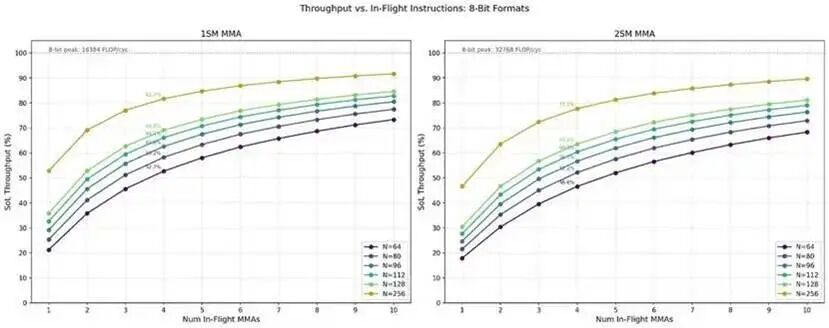
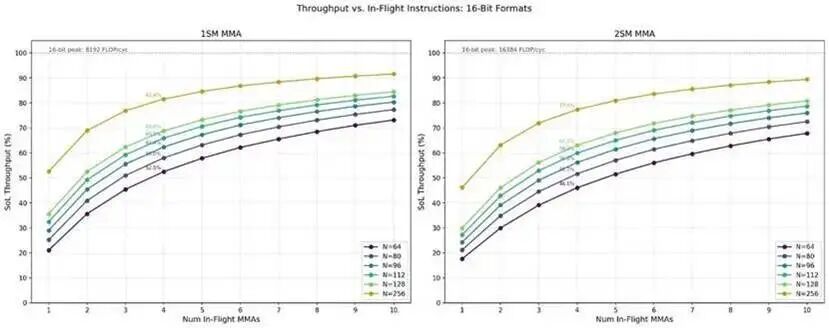
不同飞行指令数下的吞吐性能
在吞吐基准测试中,我们设置了大量的飞行指令(256~1024 条)以摊薄指令发射与提交等待的开销。
但实际内核通常只使用 1~4 条飞行中的 MMA 指令。因此我们专门测试了飞行指令数为 1~10 时的吞吐,并分析其变化规律。
在所有配置下,相同 N 值与相同MMA 飞行数所达到的理论算力利用率(SoL, Speed-of-Light) 比例相近。
值得注意的是:
- 只有最大的 N 尺寸能达到 90% 左右的算力利用率;
- 最小的 N 尺寸仅能达到约 70%。
对比 1SM 与 2SM MMA:
1SM
的算力利用率比 2SM 高出约 5%。
在相同数据格式与相同 CTA 组配置下:
- 更大的 N 尺寸,吞吐始终高于更小的 N。
最后我们观察到:
- 当飞行 MMA 指令数为 4 时,算力利用率基本封顶在 78%~80%。






评论