云中的机器学习:FPGA 上的深度神经网络

因此,很有必要采用并行计算。有很多方法可将实现过程并行化。图 6 给出了其中一种。在这里,将 11x11 的权值矩阵与一个 11x11 的输入特征图并行求卷积,以产生一个输出值。这个过程涉及 121 个并行的乘法-累加运算。根据 FPGA 的可用资源,我们可以并行对 512 抑或 768 个值求卷积。
为了进一步提升吞吐量,我们可以将实现过程进行流水线化。流水线能为需要一个周期以上才能完成的运算实现更高的吞吐量,例如浮点数乘法和加法。通过流水线处理,第一个输出的时延略有增加,但每个周期我们都可获得一个输出。
使用 AuvizDNN 在 FPGA 上实现的完整 CNN 就像从 C/C++ 程序中调用一连串函数。在建立对象和数据容器后,首先通过函数调用来创建每个卷积层,然后创建致密层,最后是创建 softmax 层,如图 4 所示。

图 4 - 实现 CNN 时的函数调用顺序。
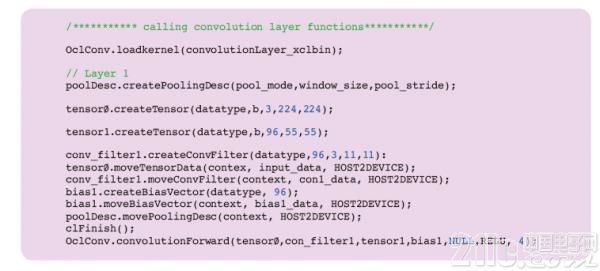
图 5 – 使用 AuvizDNN 创建 AlexNet 的 L1 的代码片段。
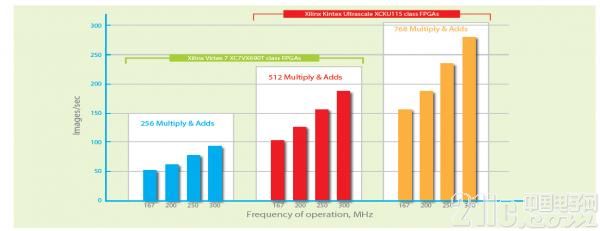
图 6 – AlexNets 的性能因 FPGA 类型不同而不同。
AuvizDNN 是 Auviz Systems 公司提供的一种函数库,用于在 FPGA 上实现 CNN。该函数库提供轻松实现 CNN 所需的所有对象、类和函数。用户只需要提供所需的参数来创建不同的层。例如,图 5 中的代码片段显示了如何创建 AlexNet 中的第一层。
AuvizDNN 提供配置函数,用以创建 CNN 的任何类型和配置参数。AlexNet 仅用于演示说明。CNN 实现内容作为完整比特流载入 FPGA 并从 C/C++ 程序中调用,这使开发人员无需运行实现软件即可使用 AuvizDNN。
FPGA 具有大量的查找表 (LUT)、DSP 模块和片上存储器,因此是实现深度 CNN 的最佳选择。在数据中心,单位功耗性能比原始性能更为重要。数据中心需要高性能,但功耗要在数据中心服务器要求限值之内。
像赛灵思 Kintex® UltraScale™ 这样的 FPGA 器件可提供高于 14 张图像/秒/瓦特的性能,使其成为数据中心应用的理想选择。图 6 介绍了使用不同类型的 FPGA 所能实现的性能。
一切始于 c/c++
卷积神经网络备受青睐,并大规模部署用于处理图像识别、自然语言处理等众多任务。随着 CNN 从高性能计算应用 (HPC) 向数据中心迁移,需要采用高效方法来实现它们。
FPGA 可高效实现 CNN。FPGA 的具有出色的单位功耗性能,因此非常适用于数据中心。
AuvizDNN 函数库可用来在 FPGA 上实现 CNN。AuvizDNN 能降低 FPGA 的使用复杂性,并提供用户可从其 C/C++ 程序中调用的简单函数,用以在 FPGA 上实现加速。使用 AuvizDNN 时,可在 AuvizDNN 库中调用函数,因此实现 FPGA 加速与编写 C/C++ 程序没有太大区别。












评论