收购Nervana后 Intel在AI芯片上进展如何?


本文引用地址:https://www.eepw.com.cn/article/201612/341370.htm
Xeon(至强)是目前Intel产品中最经典、也是使用最广泛的平台,是一个能够针对不同种类的工作进行计算支持的平台。全球90%以上的数据分析在Intel Xeon 处理器平台上实现;其中人工智能、深度学习相关方案及部署中,也有超过90%的案例使用Xeon CPU。
Xeon Phi是Xeon的进阶版,加入了众核的概念。在Xeon的基础上加入多个64核、74核的加速器,使其可以在软件的配合下大幅提高计算性能。对于例如Caffe、Alexnet这样的网络,在经过针对Xeon Phi进行软硬件结合的优化之后,性能提升了400倍。可见软硬件结合能够大幅提升深度神经网络的训练效率。
同时,若可以确定系统的应用领域是某种工作负载,则可以采用FPGA或Nervana这类定制化的硬件架构作为支持。FPGA可以用来做网络计算、视频处理、语音等方面。
与FPGA不同的,也是人工智能从业者最为关心的,Lake Crest硬件架构,是专为深度学习这种大规模运算及需要实时缓存的系统设计的。

Lake Crest是主要基于张量运算的架构,矩阵运算属于张量运算。图中绿色部分是专门针对矩阵运算的处理单元。同时运用Flexpoint技术,一个基于定点与双精度浮点之间可以变化的技术,来提供较高的并行化计算能力,计算密度是目前最好的硬件加速水平的十倍。同时,由于计算单元专门针对张量运算所设计,所以功耗较低。
上图周围的四个黄色块为高带宽内存,通过专用的内存访问接口连接到主芯片,中间灰色大区域可以看作一个芯片。这些内存是直接由软件管理的,因此整个计算中不存在Cache,也就不存在不可预测的Cache miss,何时、去哪里读取数据完全由程序控制。
单靠一个这样的芯片可能处理不了所有的深度学习训练任务,针对特殊的需求,可以采取多个芯片协同工作的方式。多个芯片之间的互联靠RCL,RCL是Intel专门定制的Interchip Link,它的速度比传统的PCIE快20倍,而且是双向的数据带宽通道,能够达到8TB/s。借由RCL,一个芯片最多可以与12个芯片互联,以组成训练所需的规模较大的超网格。
记忆是AI产生认知的必要条件
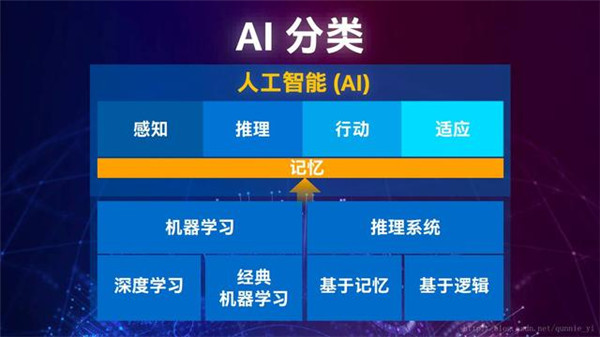
对于AI今后发展的展望,宋继强不止一次强调,记忆是AI产生认知的必要条件。
“智能体现哪些方面?首先是感知外界环境的能力;二是根据感知进行推理;三是推理形成决策触动机器做反馈(如说视觉、声音);最后且更重要的是能适应环境,不然就会变成死程序。这里有条横线很重要——记忆。Numenta创始人Jeff Hawkins写过一本书《人工智能的未来》,就是专门讲怎样去看待人工智能。智能就表现在能利用记忆进行预测,若能做到这一点,机器就真有智能了。记忆能力非常重要,很多人工智能厂商正在将它加入系统。”









评论