改良的kmeans与K近邻算法特性分析

摘要:kmeans算法作为无监督算法的一种,对初始点的选择比较敏感;而k近邻作为一种惰性且有监督的算法,对k值和样本间距离度量方式的选择也会影响结果。改良的kmeans算法通过遍历样本,筛选初始点,其准确率超过了k近邻算法,同时稳定性也优于传统的kmeans算法。无监督算法在一些情况下优于有监督算法。
本文引用地址:https://www.eepw.com.cn/article/285001.htm引言
上个世纪60年代,MacQueen首次提出kmeans算法 [1] ,而后的数十年中,kmeans算法被广泛应用于各种领域,比如马勇等人将kmeans算法应用在医疗系统中 [2] ,杨明峰等人将kmeans聚类算法应用于对烤烟外观的区域分类 [3] 。同时很多的学者投入到对kmeans算法本身特性的研究中 [4-5],目前kmeans算法已经成为机器学习,数据挖掘等领域比较重要的方法之一。而k近邻算法是图像以及文本分类领域应用比较广泛的算法之一 [6-7],对k近邻算法而言,k值的选择以及样本间距离的度量方式都会影响到分类的精确度。但是同样有许多学者对该算法进行了一些改善,比如孙秋月等 [8] 通过对度量的样本数据的每个维度赋不同权值的方式,降低了样本数据分布不均匀导致的分类误差。严晓明等通过类别平均距离进行加权对大于某一个阈值的数据样本点进行剔除的方式来提高k近邻算法的精度[9] 。k近邻算法本身是一种惰性的监督算法,相较于其他监督算法比如支持向量机、逻辑回归、随机树等,具有算法简单、易于理解、易于实现、无需估计参数的特性。kmeans算法由于对初始点选择较敏感,不同的初始点将会导致不同的聚类结果。因此本文对kmeans算法进行改进,改良的kmeans算法对二分类的结果可以接近k近邻算法的正确率,甚至在k近邻算法选择不同的k值时,分类效果会优于采用k近邻算法的分类结果正确率,同时分类的结果也远高于随机指定初始点的kmeans算法。
1 传统的分类算法与改进算法
1.1 传统的kmeans算法与k近邻算法
对于传统的kmeans算法而言,对于给定的数据集n个样本,在不知道数据集的标记时,通过指定该数据集中的k(k≤n)数据样本作为初始中心,通过如下的方式进行聚类:
(1)对该数据集中任意一个数据样本求其到k个中心的距离,将该数据样本归属到数据样本距离中心最短的类;
(2)对于得到的类中的数据样本,以求类的均值等方法更新每类中心;
(3)重复上述过程1和2更新类中心,如果类中心不变或者类中心变化小于某一个阈值,则更新结束,形成类簇,否则继续。
但是对于传统的kmeans聚类算法而言,由于随机指定初始点,对kmeans算法通过迭代这样一种启发式的贪心算法而言不能形成一个全局最优解,迭代最终收敛的结果可能都是局部最优解。这样分类的精度就会难以预料,对最终的样本分类就难以消除随机指定初始点造成的聚类结果不一致的影响。
对于传统的k近邻算法而言,对于给定的数据集,有n个数据样本是已标记的,另一部分数据样本是未标记的,对未标记的数据样本,通过如下的方式进行分类:
(1)度量每个未标记数据样本与所有已标记数据样本的距离;
(2)对所有求出的距离选择与未标记数据样本距离最近的k(k≤n)个已标记数据样本;
(3)统计这k个已标记的数据样本,哪一类的数据样本个数最多,则未标记的数据样本标记为该类样本K近邻算法没有一个数据样本训练的过程,本身是一种惰性的监督算法,该算法对k值的选择以及距离的度量方式都会影响最终的分类精度。因为该算法只是选择。
k个近邻而没有判断近邻中样本是否分布得均匀。因此,该算法如果样本分布不均匀,也会大大影响分类的结果。
1.2 改进的kmeans算法
由于传统kmeans算法初始点的影响较大,因此可以做如下改进。
对于给定的数据集样本,kmeans可以通过两两比较数据集中数据样本点间的距离,选择距离最远的两个点A,B作为初始标记。同时为了去除噪声对初始点的影响,对于选定的初始标记点,可以选择以初始标记点为中心,与初始标记点距离小于阈值的若干个点的几何均值作为最终的初始点。对于A初始标记点的若干点的选择原则是离初始标记A距离与离B距离的比值大于一定阈值的若干点,而对于B初始标记点的若干点的选择原则是离初始标记B距离与A距离的比值大于一定阈值的若干点。选定了初始点后,其后的步骤如下:
(1)对该数据集中任意一个数据样本求其到两个中心的距离,将该数据样本归属到数据样本距离短的类;
(2)对于得到的类中的数据样本,求类的均值更新两类中心;
(3)重复上述过程1和2更新类中心,如果类中心不变或者类中心变化小于某一个阈值,则更新结束,形成类簇,否则继续。
2 实验结果与分析
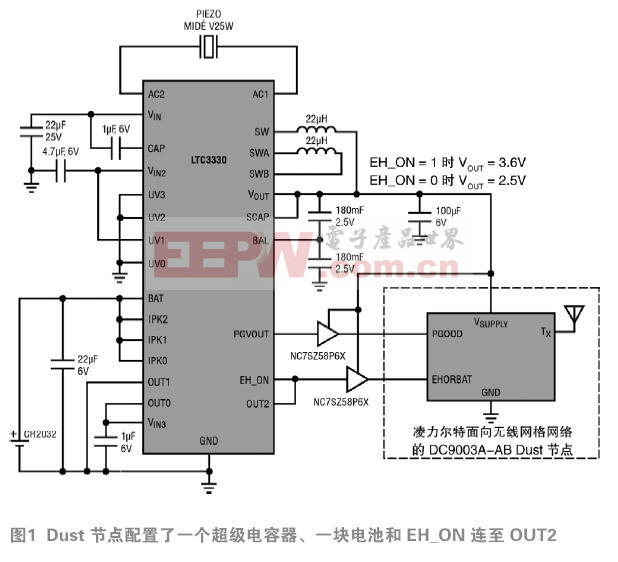
采用手写数字集MNIST Handwritten Digits [10]进行实验,该数字集库含有0-9的10类手写训练数据集和0-9的10类手写测试数据集。每个数据集样本的大小是28*28的图片,转化成向量是1*784维大小。从手写数据集中抽取标记为1和2的两类数据集样本,从这类数据集中随机抽取标记为1和2的数据样本各1000个,共计2000个数据样本进行实验分析。从这2000个数据样本中随机选择1600个数据样本(标记为1和2的两类数据各800个数据样本)进行k近邻分析,400个数据样本(标记为1和2的两类数据样本各200个)进行测试。对于改进的kmeans算法,将小于阈值的5个点取几何均值作为最终的初始点和传统的kmeans算法采用400个数据样本进行测试。改进的kmeans算法测试的正确率为84.25%,传统的kmeans算法初始值不确定,可能的正确率为15.75%,51%以及83.75%等。很明显,改进的kmeans算法不管从精度还是稳定性方面都优于传统的kmeans算法。k近邻算法选择曼哈顿距离和欧式距离作为距离度量的方式,同时改变k值对k近邻算法的结果进行测量,结果如图1所示, 横轴表示k值选择的样本数,纵轴表示对应的测试正确率。

从图1中可以看出,随着近邻数的增多,在一定的范围内,k近邻的精度是下降趋势。对于选择曼哈顿距离度量样本间距离的k近邻算法,当k值大于200的时候,k近邻算法对样本的分类正确率明显低于改良的kmeans算法对样本分类的正确率。而采用欧式距离度量样本间距离的k近邻算法,当k值大于380的时候,k近邻算法对样本的分类正确率才明显低于改良的kmeans算法对样本分类的正确率。因此对于k近邻算法而言,k近邻数目的选择以及样本间距离度量的方式对分类的结果都是至关重要的。同时从中可以发现,在某些情况下,无监督的学习方式可能比有监督的学习方式更有利,也更方便。
参考文献:
[1]Macqueen J. Some methods for classification and analysis of multivariate observations[C]. Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, 1967: 281-297
[2]马勇. 一种改进的K-means聚类分析算法在医院信息系统中的应用研究[J]. 信息资源管理学报, 2012, (03): 93-96
[3]杨明峰, 詹良, 魏春阳, 等. 基于K-means聚类分析的不同种植区烤烟外观质量区域分类[J]. 中国烟草科学, 2012, (02): 12-16
[4]张文明, 吴江, 袁小蛟. 基于密度和最近邻的K-means文本聚类算法[J]. 计算机应用, 2010, (07): 1933-1935
[5]袁方, 周志勇, 宋鑫. 初始聚类中心优化的k-means算法[J]. 计算机工程, 2007, (03): 65-66
[6]陈帅均, 蒋平, 吴钦章. 改进的KNN算法在光测图像关键事件评估中的应用[J]. 光电工程, 2014, (08): 66-72
[7]王渊, 刘业政, 姜元春. 基于粗糙KNN算法的文本分类方法[J]. 合肥工业大学学报(自然科学版), 2014, (12): 1513-1517
[8]孙秋月. 基于SNN相似度的KNN分类算法研究[D]. 云南大学, 2008
[9]严晓明. 基于类别平均距离的加权KNN分类算法[J]. 计算机系统应用, 2014, (02): 128-132
[10]The MNIST database of handwritten digits[EB/OL]. http://yann.lecun.com/exdb/mnist/
本文来源于中国科技期刊《电子产品世界》2016年第1期第79页,欢迎您写论文时引用,并注明出处。





评论