高性能DSP核心抢攻嵌入式视觉市场

为了满足行动手机、汽车和视讯产品的高性能和高功效成像需求,嵌入式视觉演算法正持续快速发展,并在数位讯号处理(DSP)核心IP公司之间开启了全新的战场。
继Ceva公司在一年前发布可程式的低功耗成像与视觉平台MM3101之后,今年2月,Tensilica公司也推出了名为IVP的成像与视讯资料层处理器单元(DPU)。
Tensilica公司的IVP DPU是一种可授权的半导体IP核心,专门设计用于从主处理器卸载复杂的成像功能。据Tensilica公司创办人兼CTO Chris Rowen透露,虽然目前IVP IP核心主要用于大众市场,但已有两家客户将它运用于其系统晶片中。
IVP DPU具有每秒每瓦执行5,000亿画素作业的能力,采用台积电(TSMC)的28nm制程技术制造。据Tensilica公司介绍,IVP DPU中每颗核心占用面积不到0.5平方毫米,因此非常适合低成本应用。
推动对于成像/视讯处理器核心的需求来自于各种新功能,例如行动手机和数位相机中使用的高动态范围影像撷取、脸部辨识与追踪;数位电视(DTV)中使用的手势控制与视讯后处理;先进驾驶辅助系统(ADAS)中的正面碰撞警示、车道偏离警告等。
这些复杂的成像/视觉演算法发展非常迅速,以致于行动手机和汽车公司希望「在数周内而不是几个月内」,就能将这些新功能整合于其产品系统中,Tensilica公司成像/视讯总监Gary Brown表示。
多种方案选择
对于系统供应商来说,成像/视讯处理解决方案有多种方案备选,从在CPU中完成所有功能到卸载成像功能至GPU,或是增加专用于成像功能的硬线逻辑等各种选择。
「举例来说,光是在1.5GHz频率的A8 四核心上进行视讯处理,而不包括其它功能,也很容易就达到3瓦功耗。」Rowen表示。
对于行动手机或数位相机而言,想要单独在CPU上做到这一点尤其困难,特别是当这种消费系统需要在拍照的同时连续执行高动态范围等演算法时。
IVP处理器核心架构
透过使用硬线逻辑,可实现一些专用功能,如脸部检测、视讯稳定或物件追踪等。但是,随着越来越多的高阶人机界面功能向下转移到消费设备上,从现在开始的两个月内就必须提供更多新的硬线模组。
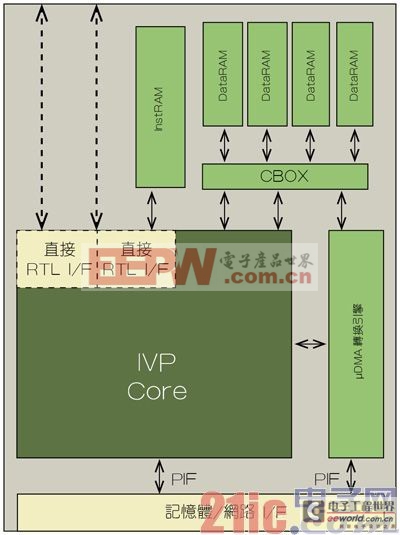
Tensilica的IVP DPU平台架构
将成像功能卸载到GPU是另外一种选择。值得注意的是,GPU的侧重点在于浮点运算和3D绘图处理,Rowen认为,这种修改可能会降低成像效率,并增加晶片占用面积。此外,GPU较难以进行编程处理,他补充道。
Berkeley Design Technology公司总裁Jeff Bier解释,处理即时影像或视讯资料一般需要「每秒数百亿次作业,」这是因为「我们将复杂的演算法运用于即时资料,并从画素中撷取含义——这是嵌入式视觉的本质——也是个困难的问题。」
另外,这个难题「从一般意义来看,事实上还未能解决,」Bier补充道。这意味着「演算法开发方法可能极具试验性和反覆性。」因此,从另一方面来看,所需要的成像/嵌入式视觉解决方案是可加以编程的,也较易于开发,他指出。
基于高效处理器的架构
Linley Group公司资深分析师J.Scott Gardner赞同Jeff Bier的看法。「相较于视讯编解码具有详细定义的演算法,让设计者可烧录于硬体中;而嵌入式视觉所用的演算法实际上是无限制的,而且还一直在发展中。」他表示。
Gardner把嵌入式视觉称为「完美的应用」,因为它能「充分利用演算法中固有的资料层平行机制」。然而,仅拥有大量画素运算单元是不够的,他补充道,「记忆体系统和汇流排架构必须设计成能够以接近每秒10亿画素的速率高效率地提供画素资料。」
那么在针对嵌入式视觉应用实现最佳化处理器时,设计者必须具备哪些特殊能力?Jeff Bier列举:必须能应用多种架构化平行机制,充分利用画素处理平行特色;支援更短与更长的资料类型(如8位元、16位元和32位元),这样当需要较低精度时,就能平行执行更多作业以及节省记忆体频宽,而在需要较高精度时也能立即得到满足;提供非常高的记忆体频宽,以便能使所需的大量资料有效率地进出处理器;提供专门的指令,以便有效率地建置这些演算法中所使用的关键作业。
事实上,Tensilica公司的IVP架构就能满足许多这种要求。IVP基于四路可变长度指令扩展(FLIX)架构。FLIX是Tensilica版本的VLIW架构,提供混合了紧密编码指令的高度平行机制。IVP采用一套32路向量单指令多资料(SIMD)的资料集和一条平衡的9级管线。
这种架构包含一个直接记忆体存取(DMA)传送引擎,支援高达每秒10GB的吞吐量和每周期1,024位元(64x16位元画素/周期)的局域记忆体吞吐量,可充分满足解析度和画面播放速率要求。IVP还采用了许多特殊成像作业指令,可加速8位元、16位元和32位元画素资料类型和视讯作业模式,据Tensilica公司介绍。
Tensilica IVP vs CEVA架构
当然,Tensilica并不是第一家致力于开发成像和嵌入式视觉用处理器核心的公司。CEVA公司于2012年1月发布的MM3101与Tensilica的IVP有许多相似之处,也混合使用了VLIW和SIMD。
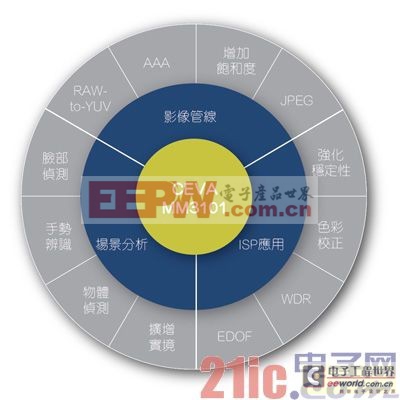
CEVA-MM3101平台专用于满足最先进的成像增强和电脑视觉 应用等极端计算需求
Gardner认为,「随着Tensilica进入嵌入式视觉市场,CEVA将必须重新改善其MM3000平台。」
相较于Tensilica的IVP,CEVA公司的MM3101提供较低的原生运算性能和较小的记忆体频宽。Tensilica支援32路SIMD(512位元向量),可能平行处理32个16位元画素,相形之下,MM3101在使用两个128位元的向量处理单元时仅支援每周期16个16位元画素,Gardner解释道。
此外,虽然CEVA的MM3101有一个独立的256位元向量载入/储存单元,但Tensilica的IVP支援每周期高达2个512位元的参考记忆体,可实现高达4倍的记忆体频宽。






评论