JPEG 2000标准中MQ编码器的VLSI结构设计

引 言
JPEG 2000是为了弥补JPEG的不足而提出的新一代静止图像压缩国际标准。其目标是对多种类型的静止图像实现高效压缩,并要求压缩码流具有较好的抗误码性能,用户可对图像进行多种形式的累进传输,还可以对压缩码流进行随机访问和处理。
JPEG 2000用基于上下文的自适应算术编码取代JPEG系统中的赫夫曼编码,对量化后小波变换系数的二进制位平面进行算术编码。算术编码对每一小波子带分块独立进行位平面编码,并将每个位平面分在3个子位平面通道内进行编码。虽然现有算术编码在算法上做了很多改进,但算法的复杂性和大量的编码数据导致MQ编码器的实际工作效率仍然很低。为了提高MQ编码器的编码速度,对编码流程进行优化,提出一种基于三级流水线的MQ编码器的VLSI结构。
1 MQ编码器原理
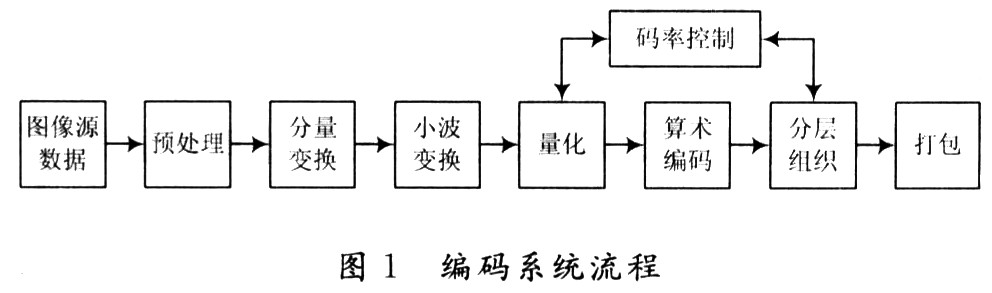
JPEG 2000的编码系统流程如图1所示。
在JPEG中,作为无损压缩DCT系数的熵编码方法,采用了霍夫曼编码(算术编码为选项)。霍夫曼编码因按DCT系数大小来分配可变码长,所以查表处理形成主体,能够简单实现霍夫曼编码。但是,由于预先调查了解符号系列的统计性质后制表,所以此后一旦有与其性质相违背的符号输入进来,就难免使压缩特性恶化,这个不足限制了其应用范围。
补救霍夫曼编码这一缺点的就是JPEG 2000中被采用的自适应算术编码。算术编码的构思是作为Elias编码,依据为人们所熟悉的划分递归概率区间的设想,在Elias编码中,对于具有 “0”或“1”值的二进制符号系列,以各自概率值比率将当前概率区间划分成两个子区间,被分配给实际产生符号的概率值区间下限值构成代码串。即代码串按二进制符号系列的输入逐次被递归地修正下去。
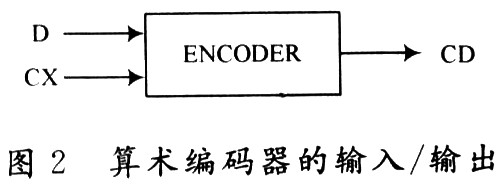
JPEG 2000中采用算术编码,其基本规则像Elias编码那样,不是以符号“0”和“1”的实际值来区别,而是分别作为MPS(大概率符号)或LPS(小概率符号)中一个子区间来区别的。而且,将当前概率区间划分成两个子区间时的顺序是MPS子区间可配置到LPS子区间的上面。因此,若符号是MPS,就在给代码串附加LPS子区间的同时,设概率区间宽度为MPS子区间;若符号是LPS,就不改变代码串,设概率区间宽度为LPS子区间。按判决输入将此处理递归地重复下去。MQ编码器的输入/输出框图如图2所示。其中,D是二进制判决;CX是上下文索引;D和CX二者均事先由算术编码之前进行的系数位建模确定。 CD是输出的压缩数据。
在MQ算术编码器中,用寄存器A表示当前子区间的宽度,寄存器C表示子区间的起始位置。它们均具有16 b有效长度,在发生重新归一化时,为了避免16 b的C寄存器溢出,而采用28 b表示。通过采用重新归一化方案,使A的取值范围保持在[0.75,1.5]。当编码器接收到一个新的待压缩码,编码器从概率估值表查找相应的概率Qe。根据接受的待压缩码类型,寄存器A的值和寄存器C的值被进行更新,从而区间更新可近似为:当编码MPS时,A=A-Qe,C=C+Qe;当编码LPS时, A=Qe,C=C,避免了乘法运算。
同时,由于MQ算法在进行区间计算时省略了乘法的近似,使得可能发生LPS子区间大于MPS子区间的情况。为了避免这种情况,采用区间条件交换,即将 MPS与LPS互换。MQ编码器通过重归一化方法解决计算的有限精度问题:当AO.75时,对A进行左移直至不小于0.75为止,同时C也左移同样位数,并按一定间隔将不再变化的高位移入存储区。
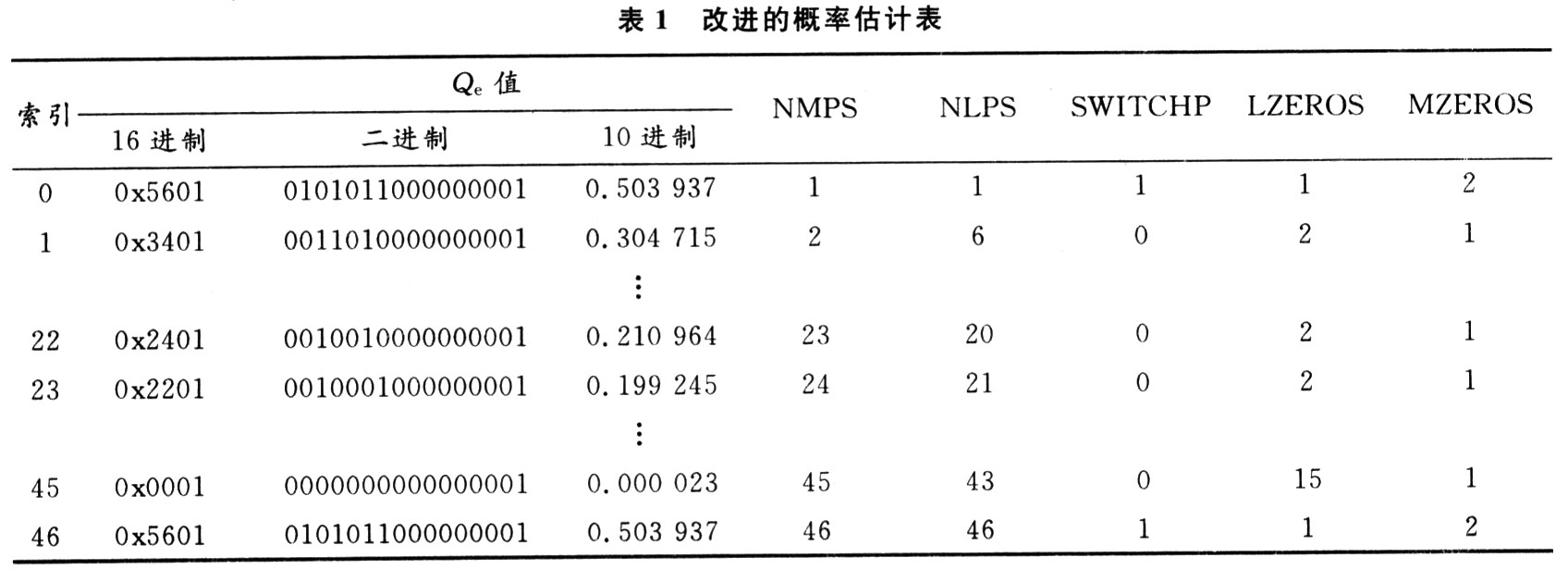
MQ编码器所使用的概率估值表是一个可以对原始数据快速适应的复杂概率自动估计模型。该模型是一个具有47个状态的有限状态机。每个状态包含小概率符号 LPS的概率Qe、下一个状态的索引NMPS和NLPS。是否需要交换MPS和LPS所代表符号的标志SWITCH。
MQ编码器中设置了一个专用计数器CT作为已压缩字节输出控制。当A左移1位时,CT也同时减1;当CT=0时,输出1个字节。为避免区间更新过程中产生的进位向前传播,在MQ编码器中,采用位填充技术来处理进位问题。根据字节缓冲B及C进位位的值,编码器选择是否进行位填充。
2 MQ编码器的优化
MQ编码器采用串行执行方式,且编码算法复杂、耗时,从而导致编码器执行速度慢,效率低下。为了提高MQ编码器的运行速度,利用FPGA的大容量和并发执行等特性,对MQ编码器进行设计,在不改变原算法理论的条件下,对整个流程进行改进和优化。
只有当前一输入的结果被输出后才能读人下一输入的串行执行方式,极大地限制了编码速度的提高。为解决这个问题,将整个编码流程分成三个大的模块(如图3所示)串接起来,采用流水线的方式进行工作。
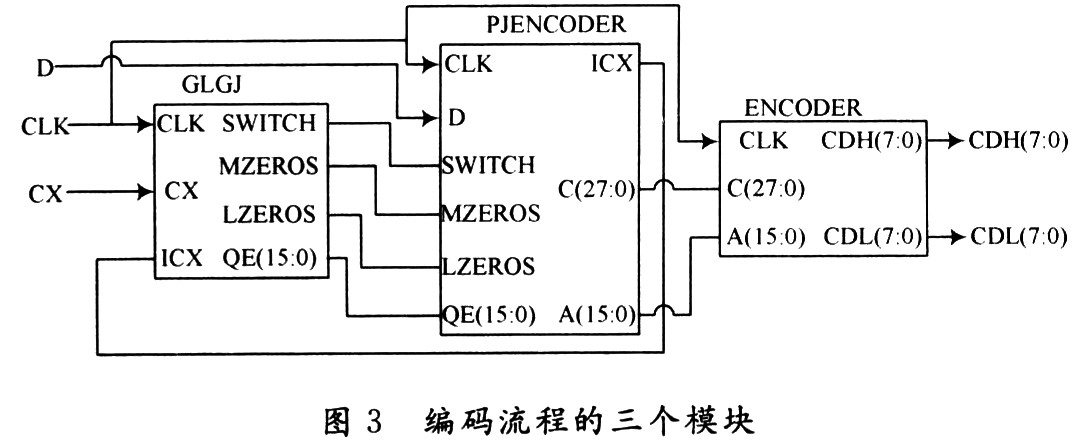
其中,GLGJ模块为概率估计模块,其功能是根据上下文索引CX选择,判决D编码所必需的概率估值和相关数值,在各个上下文自适应更新数值; PJENCODER模块为判决编码模块,其功能主要是进行MPS编码或LPS编码、重新归一化等主要数据处理进程;ENCODER模块为编码输出模块,主要完成压缩数据的输出及编码终结等功能;由这三个模块组成三级流水线。
2.1 判决编码的化简
判决编码中先判断D的取值是“0”还是“1”,如果D=0,就进行0的编码;如果D=1,那就进行1的编码。在“0”或“1”的编码中,又要根据MPS (CX)的取值,判断是进行MPS编码,还是进行LPS编码;在MPS和LPS编码中,先更新区间宽度A的值,即A=A-Qe[I(CX)],再判断A是大于还是小于Qe[I(CX)],由此与其他的一些条件决定最后的赋值方式。
上述过程包括ENCODE,CCOE0/CODE1,CO-DELPS/CODEMPS五个子流程,6个条件判断,多次赋值,降低了编码速度。对编码的判决条件进行整理,减少不必要的赋值,其Verilog代码如下:

由此可有效地减少不必要的寄存器和位数赋值,加快模块的工作效率,从而提高整个系统的工作频率。
2.2 重新归一化的加速
MQ编码器一方面在编码MPS时,给代码C加上Qe值,将概率区间A减为A-Qe;另一方面,在编码LPS时,代码C不变,将概率区间A置换成Qe。如果将这样的区间划分运算进行下去,在某一时间点上,概率区间A就会比必要精度范围(O.75≤A1.5)小,这时就要通过重新归一化A与C维持精度范围。
重新归一化过程是根据条件(A0.75):当条件成立时,将区间寄存器A和代码寄存器C再左移1次,使其大小加倍,直到概率区间A的大小超过0. 75。由此可见,如果A的值很小,则左移操作将会反复进行,大大降低了编码速率。同时因编码中有MPS编码和LPS编码两种,根据D的不同以及编码方式的不同,重新归一化时移位的次数也不同。
因此为了提高速度,并充分利用硬件的优势,将Qe的移位次数作为寄存器数,加入到概率估计表中(表1所示)。无论输入数据D为何值,编码的判决都是以 LPS或MPS为标准,所以当判决为LPS编码时,LZE-ROS中的数据就决定了左移位的次数;当判决为MPS编码时,MZEROS中的数据就决定了左移位的次数。通过编程将扩展后的概率估计表,以寄存器的方式固化在芯片内部,虽然这样增加了硬件电路中寄存器的数量,但可以通过一次性的直接查表得到判决编码和重归一化所需的数据,提高了查找效率。由于每次编码都要用到该表,访问效率很高,这样大大加快了编码的速率,同时便于流水线结构的实现。
2.3 编码输出模块的改进
标准MQ编码器中当输出计数器CT=0时,MQ编码器输出1个字节。标准中字节输出流程是串行执行的,造成效率低下。又由于重新归一化过程采用了一次性的移位方式,最大的移位次数可达15次,且过程中伴随着字节输出。有三种可能情况:不需要进行字节输出,需要进行1个字节或2个字节的字节输出。因此需要对字节输出机制作改进。这里将减法记数器CT改为5位的加法记数器,并使用一个16位的数据缓存器。根据CT的取值,判别输出的是0字节还是1字节或者2字节,由此达到加速字节输出的目的。
3 实验结果及分析
对所实现的MQ编码模块用Verilog HDL硬件描述语言进行RTL级描述,在Xilinx ISE 7.1和:Model-sim 6.1平台下进行功能验证和时序仿真。按字节输入测试码流:00 02 00 51 00 00 00 C0 03 52 87 2A AAAA AA AA 82 C0 20 00 FC D7 9E F6 BF 7F ED 90 4F46 A3 BF,得到结果码流为:84 C7 3B FC E1 A1 43 0402 20 00 00 41 0D BB 86 F4 31 7F FF 88 FF 37 47 1ADB 6A DF FF AC。得到的结果与理论结果一致,仿真波形如图4所示。
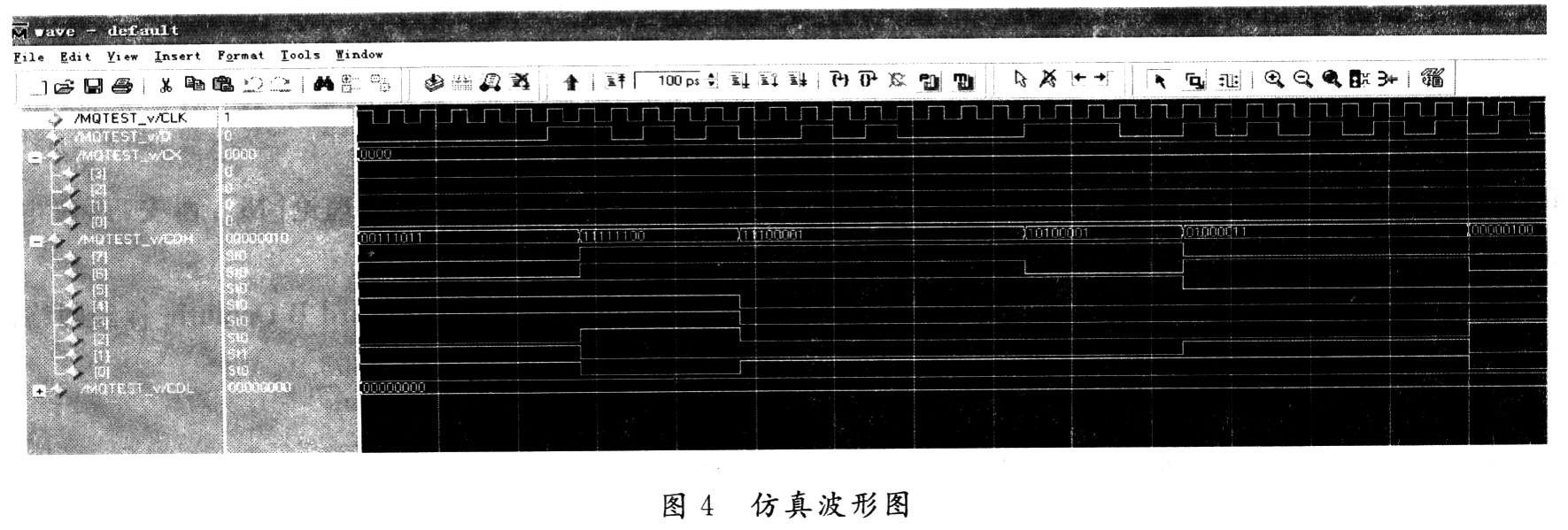
图4中D为输入的测试码流,CDH为输出码流。该设计在Xilinx的XA2C32A-6VP44器件上进行验证,结果表明,最高工作频率可达95.47 MHz,较大地提高了编码速度,能够满足JPEG 2000对高速编码的要求。
4 结 语
综上所述,为了满足现在对JPEG 2000高速编码的需求。在对MQ编码器的流程及相关算法进行分析后,利用现有FPGA的优势,在采用三级流水线结构的同时,对编码进行了优化;经 Xilinx的FPGA器件实现,不仅验证了该设计在功能上的正确性,同时表明在编码速度上得到了很大的提高,且最高工作频率可达95.47 MHz。



评论