基于FPGA的M2M异构虚拟化系统(二)

exe_mem_reg
本文引用地址:https://www.eepw.com.cn/article/201808/388222.htm本模块完成EXE和MEM两个阶段之间的信号流水。本模块的时序图如下。
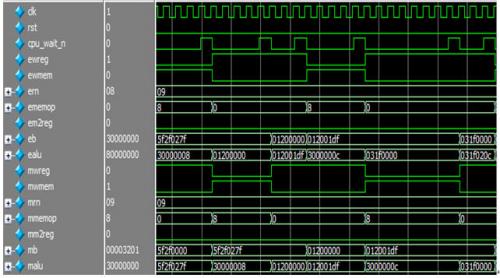
图 22 exe_mem_reg时序图
mem_stage
本模块完成对数据Cache的读写。模块的对外接口符合Wishbone总线标准。本模块的主要时序如下图。
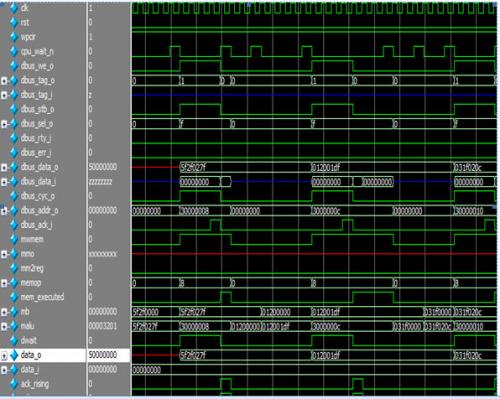
图 23 mem_stage时序图
mem_wb_reg
本模块完成MEM和WB两个阶段之间的信号流水。本模块的时序图如下。

图 24 mem_wb_reg时序图
wb_stage
本模块完成写回指令的寄存器堆修改操作。本模块的时序图如下。

图 25 wb_stage时序图
except
本模块完成流水线中的中断及异常处理。为了完成精确中断,即产生异常的指令前已经在流水线中的指令完成执行,而在异常指令后的指令不允许完成执行(不修改CPU状态),才能响应异常。因此,在实现精确中断时,需要对流水线中的指令进行跟踪,所有的异常或中断信号将延迟到流水线的特定阶段(Writeback)进行响应,并且对不同类型的异常信号,中断程序的返回地址不同。本模块的主要时序图如下。
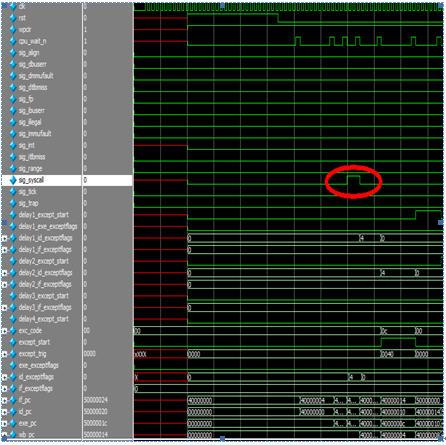
图 26 except时序图
4.1.2.2Cache模块详细设计方案
功能描述
本模块实现指令Cache和数据Cache。其中,指令Cache和数据Cache的映射策略都采用直接映射方式。指令Cache只读,数据Cache的写策略为写通过(主存和Cache里的数据时钟保持一致)。
- 子模块列表
Instruction Cache top | |
Data Cache top |
详细设计
ic_top
本模块的时序图如下。
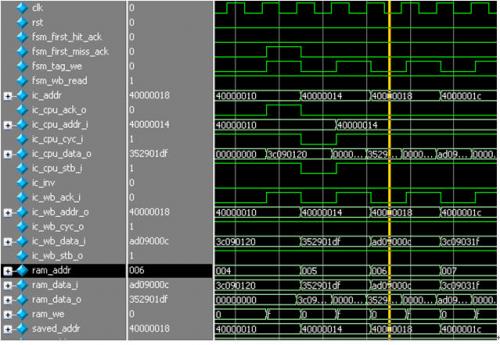
图 27 ic_top时序图
4.1.2.3动态翻译硬件模块详细设计方案
功能描述
为了提高动态翻译效率,我们在CPU中增加了硬件加速模块。动态翻译硬件加速包括以下部分:
在QS-I CPU的ALU模块中增加x86 flag寄存器(MIPS架构中没有flag标志寄存器),软件可通过mtc0,mfc0两条指令来访问flag寄存器。这样x86的算术逻辑或比较指令(如add, sub, cmp等),以及条件跳转指令(如ja, jb, jg等)有效地得到了硬件支持,使得软件的翻译效率大大提高。
在QS-I CPU外增加了JLUT(Jump address Lookup Table),即跳转地址查表。通过CAM(Content Address Memory)的硬件支持,跳转指令的翻译效率将比完全基于软件的翻译方式提高一个数量级。在QS-I中将新增4条用户指令campi, ramri, camwi, camwi用于软件对JLUT的访问。
- 子模块列表
JLUT top | ||
SPC is stored in CAMs, and it will take less than two clock cycles to get address of the CAMs content specified. | ||
TPC is stored in ubiquitous RAMs. |
详细设计
如下方的JLUT详细设计图所示,JLUT模块与QS-I CPU之间通过campi, camwi, ramwi, ramwi四条指令进行交互。
campi用于CAM的查表,camwi用于CAM的写操作,ramwi用于RAM的写操作,RAMRI用于RAM的读操作。
4条指令的格式如下。
Instruction | Format | Usage |
campi | opcode, rs, 5’h0, rd, 5’h0, func | campi rd, rs |
camwi | opcode, rs, rt, 5’h0, 5’h0, func | camwi rt, rs |
ramwi | opcode, rs, rt, 5’h0, 5’h0, func | ramwi rt, rs |
ramri | opcode, rs, 5’h0, rd, 5’h0, func | ramri rd, rs |
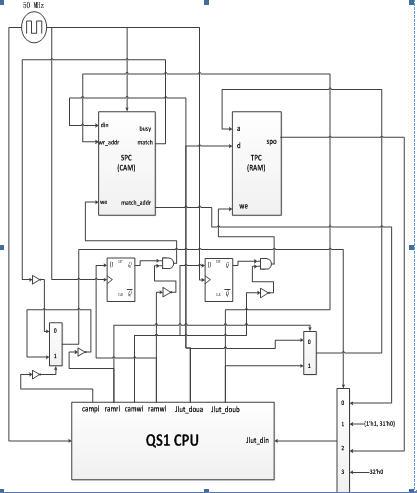
图 28 JLUT详细设计图
4.2.动态翻译详细设计方案
二进制翻译技术能够把一种体系结构的二进制程序翻译成另一种体系结构的二进制程序,以在新的体系结构下运行。二进制翻译主要有三类:解释执行、静态翻译及动态翻译。
在系统总体框架图中,二进制翻译层可运行不同的翻译程序,以在不同的体系之间进行转换,如x86到MIPS、ARM到MIPS、x86到ARM等。本部分挑选了8086到MIPS的动态翻译作为实现原型。
4.2.1.二进制翻译介绍
二进制翻译可以分为三大类:解释执行、静态翻译和动态翻译。
解释执行的流程是:取指、解析、执行。它对源机器代码进行实时解释并执行,然后继续下一条指令。系统不对已解释的指令进行保存或缓存。在这个框架下,不能对代码进行优化。这种翻译技术能取得高度兼容性,但执行效率很低。
静态翻译是先将源可执行文件转换成目标机器可执行文件,然后运行在目标机器上。这是离线翻译,因此有充足的时间对代码进行优化,以提高代码的执行效率。但静态翻译很难做到正确性,如代码的自修改问题,执行过程中有些跳转值只能在运行时才能获知等问题。
解释执行是实时翻译,静态翻译是离线翻译,动态翻译就像是两者的折中。它不像解释执行那样对每条指令进行翻译并马上执行,也不像静态翻译那样将指令完全翻译好之后才执行。它每次对一个基本块进行翻译并执行,然后取另一个块。一个基本块一般包含多条算术类型指令,最后是一条控制流(Control Flow)类型指令。已翻译的块可进行缓存或保存。动态翻译只对将要执行的代码进行翻译,且能很好地解决代码自修改问题。
4.2.2.二进制翻译策略选择
本项目采取的是软硬协同动态翻译策略,将源二进制代码进行翻译,当遇到控制流类型指令,如跳转指令,系统调用等,翻译过程挂起,将已翻译的指令序列作为一个基本块,然后运行基本块。当基本块执行完以后,会跳到下一处执行。若下一处已翻译过,则继续执行,否则暂停执行以进行翻译,如此过程循环。完整的流程如下图所示。
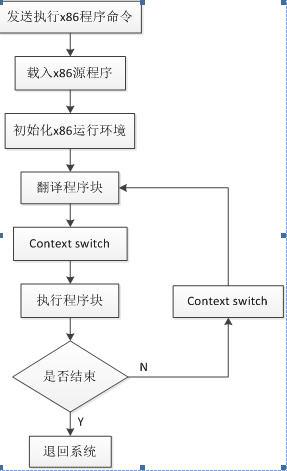
图 29 x86程序翻译执行流程
基本块执行时有硬件模块辅助,如图 12所示。硬件模块管理跳转缓存,缓存的基本项为对。程序执行到跳转指令时,程序向跳转缓存发送SPC,得到相应的TPC,再跳至TPC继续执行生成块。简单的示例如图 30所示。源程序从块A开始执行,到末尾时,需要跳转到块C。翻译后执行,执行完块A’后将要跳转,此时的跳转地址是SMEM中地址,即SPC,要转换成相应的TPC,该TPC就由跳转缓存中寻找。
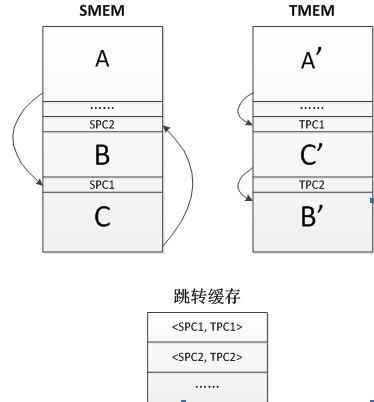
图 30 SMEM与TMEM的映射
4.2.3.8086程序的载入
首先,由系统向服务器发送命令,命令格式为x86 *.com,它包含在自定义传输协议中,类型码为86,要求.com文件仅使用一个段,大小限制为64KB。服务器找到所指定的文件,并将其传送给系统,系统将其存放在内存中。至此,完成8086可执行程序的载入。
4.2.4.标志寄存器处理
8086中有个标志寄存器FLAGS,而MIPS中没有与之相对应的标志寄存器,解决办法有二,软件模拟实现或硬件提供支持。
软件模拟指的是,当一条8086指令执行后,会影响哪些标志位,然后用软件方法将其模拟出来,使两者的结果一致。如执行add ax, bx对溢出位的影响。模拟时,将ax移到MIPS的$t0寄存器的低16位,将bx移到MIPS的$t1寄存器的低16位,然后对$t0和$t1做加法,结果放到$t0,相对应的指令为add $t0, $t0, $t1。结果是否溢出则要查看$t0的第16位。最后,还要将溢出位存放至标志寄存器的对应位。这中间还要涉及移位运算、位运算等,所需代价很大,但有个好处是无需对硬件平台做改动,使硬件平台更为纯粹。
若采用提供硬件支持,那么硬件平台需稍做修改,增加一个类FLAGS寄存器。仍以上面的add ax, bx为例。将ax、bx分别放到$t0、$t1的高16位,然后进行相加,是否溢出的结果会自动保存到新添加的类FLAGS寄存器里,因而软件层面无需再做处理。此种做法,增加了硬件工作,但大大简化了软件的操作。8086的FLAGS有多个标志位,若要完全实现,那么对本身的硬件平台改动会比较大,因此,我们只选择了其中几个进行实现,如Z、O、C、S等。
4.2.5.寄存器映射
MIPS有32个通用寄存器,从0号到31号,每个寄存器为32位。8086的通用寄存器有8个:AX、CX、DX、BX、SP、BP、SI和DI。这8个通用寄存器都是16位,AX、CX、DX和BX还可以分成两个8位寄存器,高8位和低8位,如AX可分为AH和AL。此外,段寄存器有CS、DS、ES和SS,都是16位。还有IP寄存器和FLAGS寄存器,也都是16位。
因为MIPS的寄存器数量比8086的寄存器多,可以采用直接映射,一个8086寄存器对应一个MIPS寄存器,而不需要对寄存器进行置换,简化了寄存器的管理。






评论