为何图像和FPGA更配?揭秘背后的技术要素

背景
本文引用地址:https://www.eepw.com.cn/article/201711/372324.htm“No PP,No WAY”这是个眼见为实的世界,这是个视觉构成的信息洪流的世界。大脑处理视觉内容的速度比文字内容快6万倍,而随着智能手机的普及,图片、视频的产生和分享已经是人们在社交平台上的基本交流方式。用户通过手机、平板、电脑上传和分享自己的图片,而且这个趋势是每年都在增长(参见图1)。
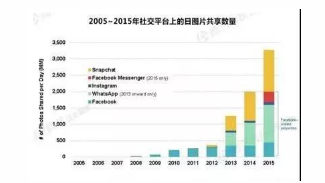
图1. 2016年KPCB统计报告[1]
每天QQ相册、微信朋友圈上,用户上传的图片数量有上亿张,这些图片被后台服务器存储下来,再通过网络分发出去。如果每张图片可以进行压缩,使得图片存储和传输分发的数据量越少,既节省了用户带宽,也提高了用户下载图片的速度,用户体验更好。那么图片是可以进行压缩的么?1948年,信息论学说的奠基人香农曾经论证:不论是语音或者图片,由于其信号中包含很多的冗余信息,所以可以对其进行压缩。图像压缩算法有:JPEG、WEBP、H264(帧内压缩)、HEVC(帧内压缩),压缩能力是:JPEG < WEBP/H264(帧内压缩) < HEVC(帧内压缩), 这个压缩能力是通过计算复杂度的提高来实现,其中WEBP、HEVC的计算复杂度是 JPEG 压缩的 10 倍以上。 目前在社交平台上用户上传的大量图片是JPEG格式,通过后台服务器用更加复杂的算法如WEBP、HEVC(帧内压缩),进一步压缩以节省存储和带宽, 所以对图像的压缩,从本质上是通过提高计算算力来降低存储和带宽。同时更加复杂的算法也带来计算算力的大量消耗和处理延时的增加。
从业务角度来看,对于离线业务,可以通过业务在波峰和波谷之间闲置的计算算力进行图片转码处理;但对于在线业务,图片转码处理对于处理延时的要求就会有较高要求,为了满足处理延时的要求,有时候会先进行图片转码处理,把转码好的图片存储下来,当用户需要的时候直接传输,这样通过消耗存储资源为代价来解决处理延时的要求。但是这又带来一个新问题,用户查看图片的智能终端屏幕大小不一,如果都传同样大小的图片,显然不是最优。最优处理方法还是能够通过计算算力,实时进行图片转码处理。
在数据中心里面,计算算力通常由x86 CPU来提供,以前的x86 CPU性能每18个月就能翻倍(众所周知的“摩尔定律”),但目前工业界的发展方向是摩尔定律已经走到终点。例如,2016年3月24日,英特尔宣布正式停用“工艺年-架构年(Tick-Tock)”处理器研发模式,未来研发周期将从两年周期向三年期转变。而国际半导体技术发展路线图(International Technology Roadmap for Semiconductors,简写 ITRS)在维持了数十年,每两年更新一次,为全世界半导体行业提供建议和规划指南,也在2016年宣布不再做进一步的更新。
一方面处理器性能再无法按照摩尔定律进行增长,另一方面数据增长对计算性能要求超过了按“摩尔定律”增长的速度。处理器本身无法满足高性能计算(HPC:High Performance Compute)应用软件的性能需求,导致需求和性能之间出现了缺口(参见图2)。
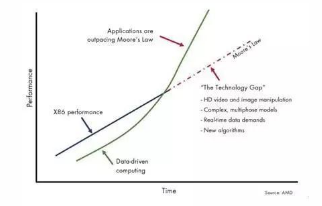
图 2. 计算需求和计算能力的缺口发展形式
图像处理解决方案
图片服务支持的能力丰富多样,基础功能包括多种缩略剪裁方式、文字图片水印、格式转换、断点续传、镜像存储、防盗链等。我们结合当前图文时代的用户需求,提供图片的上传、存储、处理、分发的全方位一体化的解决方案。目前,互联网图片服务的解决方案中落地存储和下载大部分图片格式还是JPEG/WEBP,但随着新的编码标准HEVC的出现,在同等图像质量下,HEVC的压缩效率会比JPEG/WEBP好30%~70%,可以节省大量的存储和带宽,但是HEVC的算法复杂度高导致CPU的编码延迟和吞吐在线上环境中无法满足,因此,我们开发了基于FPGA的新的解决方案。FPGA图像处理方案可以很好的解决线上环境的需求,当然,FPGA图像处理解决方案也兼容当前用户线上系统的WEBP等其他图像转码格式,可以很好的适应不同用户的需求,提供低延迟,高吞吐,低成本的解决方案。
我们以HEVC FPGA 图像处理为例,来说明在互联网业务中图片上传,存储,处理和下载的架构。
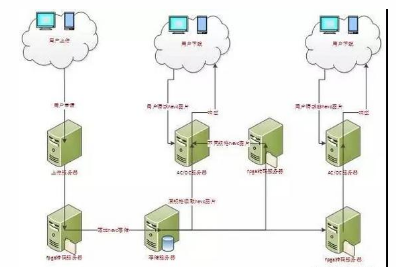
图3. HEVC FPGA 图片上传存储,处理,下载解决方案
如图3所示,图片HEVC FPGA转码的部署主要是落地存储前以及下载前的转码服务器,使用FPGA做转码主要有以下优势:
FPGA转码落地存储HEVC,可有效节省存储成本。
1. FPGA转码服务器和CPU转码相比可以降低服务器成本。
FPGA转码HEVC图片和CPU相比吞吐量可以大大提高。
在下载时实时生成HEVC图片,使用FPGA进行图片转码加速,会大大降低转码延迟,提高用户体验。
图像编码算法分析
在图像和视频编解码算法中,各个模块都是基于像素级运算或者基于块操作,而且针对各个像素或者图像块的操作是相同和重复的。早期的图片压缩标准JPEG和JPEG200,原始图像首先经过基于块的DCT变换或者小波变换,变换后的系数经过量化后再进行熵编码(包括Huffman编码或者自适应算术编码),进而输出压缩后的码流信息。在解码端,通过反向操作,可将码流信息进行解码。在JPEG2000中,DCT变换被小波变换替代,可以更好的消除图像块内的冗余性,而且量化后的系统按照比特位平面进行自适应算术编码,可以达到更好的压缩性能。
除了JPEG这类对原始图像直接变换的方法,还有一种是基于块预测的方法。也就是对一个图像块先进行预测,原始图像块和预测块的残差再进行变换,量化和编码。比较典型标准就是从H.264的帧内预测发展而来的WebP。随着新一代视频编码标准HEVC/H.265的推出,其帧内编码的压缩性能,较上一代标准提升接近一倍[2]。因此,将HEVC的帧内编码用于图像压缩也成为一种趋势。HEVC的帧内编码过程如图4所示。

图4. HEVC帧内编码的过程
在HEVC中,块划分的方式是基于非完全四叉树结构,这更适用于不同的图像场景。每一个最终确定大小的块只需要一个独立的预测模式。图5是HEVC图片编码中块划分和预测模式的一个例子。可以看出当一个块可以通过单独的某一个角度进行预测的时候,则不需要划分为更小的块。而场景信息较为复杂区域则需要划分为较小的块。编码器的一项重要任务,就是寻找最佳的块划分方式和最优的预测角度。

图5. HEVC图片编码块划分及预测模式
图6(a) 就是根据最终的块划分方式和预测模式得到的预测图片。预测图片和原始图片的差值(残差)通过DCT变换,量化之后,最终通过熵编码器输出。图片预测的残差如图6(b)所示。在解码器中,根据得到的残差数据,并进行和编码器相同的预测,可以得到最终的重构图片,图6(c)所示的就是重构数据。由于编码过程需要用到重构数据作为参考数据,因此在编码器也需要进行重构的过程。原始图片如图6(d)所示,可以看出,重构的图片和原始图片损失非常小。

图6. HEVC图片编码过程中的预测,残差,重构以及原始数据
在HEVC的帧内编码中,由于要进行最佳编码模式的搜索,造成编码器的计算复杂度高。传统的CPU无法达到理想的吞吐量。现在的GPU虽然也大量应用的图片和视频领域,然而GPU的并行化更适用的是各个像素点进行相同操作,完成之后再进行下一步的并行化操作。这并不利于HEVC图片编码各个模块控制较为复杂的情况。在Nvidia的GPU中,图片和视频编解码也采用的专用的芯片来处理。 而FPGA可以实现各个不同的模块的流水化运算,实现时间上的并行。 同时,由于只是进行帧内编码,不同图像之间是相互独立的,在FPGA中也可以设计多路的编码器,对不同的图片进行并行的编码压缩。
当然,对于基于块预测的图像编码方法,也存在一些限制FPGA并行化实现因素。但是,这些受到限制的部分,也可以通过FPGA设计的特点来解决。例如,如图4所示,帧内预测的参考点需要通过重构的方法得到,这就增加了不同块之间的依赖性,限制了块之间的并行化,和流水化设计。在实际的FPGA设计中,可以在进行预测模式初选时,用原始数据替代重构数据作为参考,而在最终编码时用重构数据在作为参考数据[3]。在FPGA的实现过程中,也可以更改扫描顺序,优先处理那些有依赖关系的像素点。此外,在自适应熵编码部分,由于存在更新码表和更新概率估计的过程,部分比特数据进行熵编码时,也存在依赖关系。 在实际的FPGA设计过程中,可以通过将这些需要进行编码的数据进行分组,将没有依赖关系的数据分为一组,同时,通过数据缓存,可以预先判断接下来的数据是否存在依赖关系,从而提高熵编码的吞吐量[4]。
HEVC图像编码算法的FPGA实现
FPGA图像编码架构
目前,我们图片业务已经实现WEBP和HEVC格式的FPGA硬件加速,下面以HEVC I帧图像硬件加速举例,说明图像编码在FPGA中是如何实现的。
FPGA的逻辑架构主要包括平台部分和HEVC编码器IP部分,其中FPGA平台主要包括PCIE DMA以及DDR总线相关逻辑,这部分逻辑主要实现和host CPU的数据通信以及和FPGA板卡上的DDR通信。如图7所示,FPGA架构上实例化了4个HEVC core(具体几个是和FPGA资源有关),每一个HEVC core完成HEVC编码算法的完整处理,这里4核心并行工作,也就是同一时刻,4个编码任务可以并行工作,同时输出4条HEVC码流。
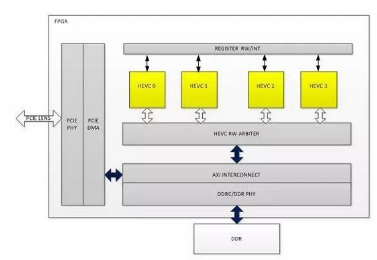
图7. FPGA内部逻辑架构
FPGA内部逻辑主要包括:
HEVC CORE 0-3:H265编码器IP,实现HEVC的编码算法;
PCIE/DMA:实现和host CPU进行通信;
REGISTER RW/INT:寄存器读写以及中断处理;
HEVC RW ARBITER:总线读写仲裁模块;
AXI INTERCONNECT/DDRC/DDRY: 总线控制访问DDR逻辑;
FPGA图像编码流程
FPGA HEVC core内部算法处理流程如图8所示:分为当前图像载入,intra预测初选,intra预测精选,CABAC编码,码流输出。
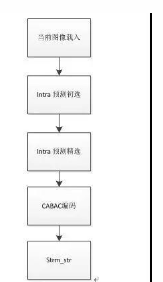
图8. HEVC core内部算法处理流程
那么如何设计HEVC core实现算法功能呢?这里,编码器模块流水线设计成四级流水,如图9所示,四级流水CURLD/PINTRA/SEL/CABAC处理性能设计接近,并行起来后,平均处理每个LCU需要8400个周期,如果按照1080p图片一共510个LCU计算,单核理论上编码可以达到编46 帧/s (FPGA电路实现频率200M),这样4核并行能达到184帧/s。
具体来说,CURLD完成当前图像的载入逻辑,PINTRA完成intra预测初选35种模式的遍历,得到最优的预测模式,这级流水算法上做了优化,预测参考像素没有像传统方式选择重构像素,而是选择当前像素做参考像素,这样优化,使得intra预测初选可以单独划分为一级流水,和intra预测精选分开,使得编码器整体处理性能增加一倍。SEL完成帧内预测模式精选以及RDO模式选择,预测块大小支持32/16/8,由于涉及到变换量化等运算量大的逻辑,这一级流水是整个编码器的资源消耗大户,设计上在算法上以及逻辑资源消耗上做了权衡;CABAC模块完成头信息的码流生成以及每个LCU的语法元素和残差的编码,并完成码流的打包输出,这一级流水的主要问题在于CABAC的性能是否足够快,从而应对QP比较小编码更多bin的处理及时。
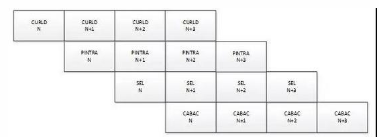
图9. 运算模块流水线
性能和收益
用FPGA完成JPEG格式图片转成HEVC格式图片,图片分辨率大小为1920x1080,FPGA处理延时相比CPU降低7倍,FPGA处理性能是CPU机器的10倍,FPGA机型单位性能成本是CPU机型的1/3(参见图10)。
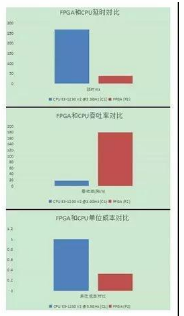
图10.图片转码FPGA和CPU对比
总之,图片算法的FPGA实现,如果不考虑FPGA资源、硬件实现架构和处理性能,CPU图像压缩算法可以完全在FPGA进行“复制”实现,FPGA算法压缩性能可以完全等同CPU。但是现实没那么理想,FPGA算法实现要统一考虑FPGA性能,资源,算法实现复杂度等要素,只有联合设计才能设计出最优秀的方案,为了发挥FPGA硬件实现的速度优势,算法进行优化是必须要做的,综合考虑各方面,我们在实际应用中,往往FPGA的算法实现要做一些“让步”。另外,某种型号的FPGA一旦被选定,它的运算以及布线资源往往有个理论值,算法的实现同时要考虑FPGA资源的利用情况,如何能在相同的FPGA资源上实现最好的压缩算法成为设计的难点。我们用FPGA进行算法实现的目标-----实现算法性能尽量接近CPU,图片处理吞吐量,以及处理延迟让CPU望其项背。
参考文献:
[1]. KPCB:玛丽·米克尔“互联网女皇”-2016年互联网趋势报告
[2]. G. J. Sullivan, J. R. Ohm, W. J. Han and T. Wiegand, "Overview of the High Efficiency Video Coding (HEVC) Standard," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649-1668, Dec. 2012.
[3].G. Pastuszak and A. Abramowski, "Algorithm and Architecture Design of the H.265/HEVC Intra Encoder," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 26, no. 1, pp. 210-222, Jan. 2016.
[4].D. Zhou, J. Zhou, W. Fei and S. Goto, "Ultra-High-Throughput VLSI Architecture of H.265/HEVC CABAC Encoder for UHDTV Applications," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 25, no. 3, pp. 497-507, March 2015.












评论