如何搞定机器学习中的拉格朗日?看看这个乘子法与KKT条件大招

一 前置知识
本文引用地址:https://www.eepw.com.cn/article/201709/363864.htm拉格朗日乘子法是一种寻找多元函数在一组约束下的极值方法,通过引入拉格朗日乘子,可将有m个变量和n个约束条件的最优化问题转化为具有m+n个变量的无约束优化问题。在介绍拉格朗日乘子法之前,先简要的介绍一些前置知识,然后就拉格朗日乘子法谈一下自己的理解。
1.梯度
梯度是一个与方向导数有关的概念,它是一个向量。在二元函数的情形,设函数f(x,y)在平面区域D内具有一阶连续偏导,则对于每一点P(x0,y0)∈D,都可以定义出一个向量:fx(x0,y0)i+fy(x0,y0)j ,称该向量为函数f(x,y)在点P(x0,y0)
的梯度。并记作grad f(x0,y0) 或者∇f(x0,y0),即 grad f(x0,y0) = ∇f(x0,y0) = fx(x0,y0)i+fy(x0,y0)j=(fx(x0,y0),fy(x0,y0)) 。
再来看看梯度和方向导数的关系:如果函数f(x,y)在P(x0,y0)点可微,el = (cosα,cosβ)是与方向L同向的单位向量,则∂f/∂L|(x0,y0) = fx(x0,y0)cosα+fy(x0,y0)cosβ = grad f(x0,y0).el = |grad f(x0,y0)|.cosθ ,其中θ表示的梯度与el 的夹角。由此可知,当θ = 0时,el 与梯度的方向相同时,此时方向导数最大,函数f(x,y)增长最快;当θ = π时,el 与梯度的方向相反时,此时方向导数最小且为负,函数f(x,y)减小最快。
2.等高线(等值线)
通常来说,二元函数 z = f(x,y)在几何上表示一个曲面,这个曲面被平面 z = c(c为常数)所截得的曲线L的方程为:
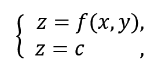
这是一条空间曲线,这条曲线L在xOy平面上的投影是一条平面曲线L*,它在xOy平面直角坐标系中的方程为:f(x,y) = c .对于曲线L*上的一切点,已给函数的函数值都是c,所以我们称平面曲线L*为函数z = f(x,y)的等值线(等高线)。再来看看等高线的一些性质:
若fx,fy不同时为零,则等高线 f(x,y) = c上任一点P(x0,y0)处的一个单位法向量为:
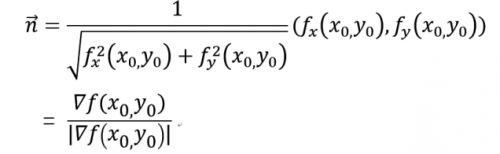
这表明函数f(x,y)在一点(x0,y0)的梯度∇f(x0,y0)的方向就是等高线f(x,y) = c在这点的法向量的方向,而梯度的模|∇f(x0,y0)|就是沿这个法线方向的方向导数∂f/∂n,于是有:
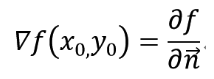
二 拉格朗日乘子法
1.等式约束
首先看一下什么是拉格朗日乘子法,已知一个问题:
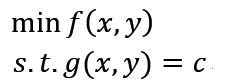
要求f(x,y)在g(x,y)=c的前提下的最小值,我们可以构造一个函数L(λ,x,y) = f(x,y) + λ(g(x,y) - c),其中λ(λ不等于0)称为拉格朗日乘子,而函数L(λ,x)称为拉格朗日函数。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。这就是拉格朗日乘子法。那么拉格朗日乘子法为什么是合理的?下面分别从几何和代数两方面解释下自己对其的一些见解:
(1)从几何的角度
先来看一幅图:

图中的虚线表示f(x,y)的等高线,如果满足g(x,y)=c这个约束,必然是等高线与g(x,y)=c这条曲线的交点;假设g(x)与等高线相交,交点就是同时满足等式约束条件和目标函数的可行域的值,但并不是最优值,因为相交意味着肯定还存在其它的等高线在该条等高线的内部或者外部,使得新的等高线与目标函数的交点的值更大或者更小,只有到等高线与目标函数的曲线相切的时候,才可能取得最优值。假设该切点为P(x0,y0),则f(x,y)在p点的梯度必然垂直于其在该点处的等值线(前面已经说过),即梯度与该点出的法向量平行,又由于p点是曲线g(x,y)=c的切点,可以看做g(x,y)=c在p点处的梯度平行于它在该点的等值线的法向量,故f(x)在p点的梯度与g(x,y)=c在p点的梯度共线(因为他们在p点处的法向量是共线的),即(fx(x0,y0),fy(x0,y0)) = λ*(gx(x0,y0),gy(x0,y0))。所以最优值必须满足:∇f(x,y) = λ* ∇(g(x)-c),λ是常数且不等于0,表示左右两边平行。这个等式就是L(λ,x)对参数分别求偏导的结果,即:

也就是说满足∇f(x,y) = λ* ∇(g(x)-c)的点必然是式子min L(λ,x) = f(x,y) + λ(g(x,y) - c)的解,所以min L(λ,x) = f(x,y) + λ(g(x,y) - c)这个式子与原问题是等价的(可以先简单的认为g(x,y) - c = 0造成的)。
(2)从代数的角度
先来看一下z = f(x,y)在条件g(x,y) = c下取得极值的必要条件。
如果z=f(x,y)在(x0.y0)处取得所求的极值,那么有 g(x0,y0) = c,假定在(x0,y0)的某一领域内f(x,y)与g(x,y) = c均有一阶段连续偏导(对于凸函数很显然是成立的)并且gy(x0,y0)≠0.由隐函数的存在定理可知方程g(x,y)=c能够确定一个连续且具有连续偏导的函数y = μ(x),将其带入z= f(x,y)中可以得到一个变量x的函数:z = f[x,μ(x)].
于是z=f(x,y)在x=x0处取得极值,相当于z = f[x,μ(x)]在x=x0处取得极值,又由一元可导函数取得极值的必要条件可知:
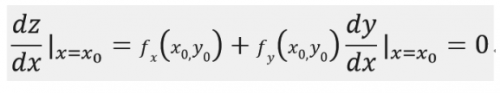
而又由y = μ(x)用隐函数求导公式,有
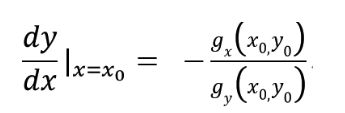
将以上两式结合可得,
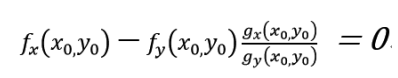
上式与g(x0,y0)=c 就是函数z=f(x,y)在g(x,y)=c的条件下取得极值的必要条件。如果令:

上述的必要条件就变为
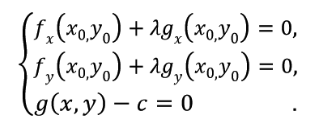
同从几何角度推出的结论一致。
综上所述,对于问题
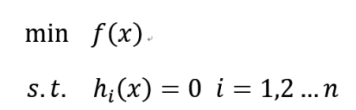
(x可以为一个矢量,也可以为一个标量)
等价于求
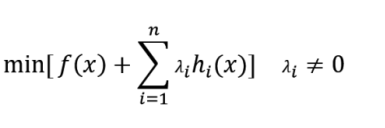
对于拉格朗日乘子法求出的候选值,需要注意验证;如果目标函数f(x)是凸函数的话则可以保证得到的解一定是最优解。
三 KKT条件
1.关于不等式约束
上述问题中讲述的都是约束条件为等式的情况,对于约束条件为不等式的情况,通常引入KKT条件(在不等式约束下,函数求极值的必要条件)来解决,具体如下:
对于问题
我们也引入拉格朗日函数
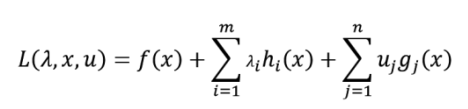
其中μj≥0。
再看一个关于x的函数:
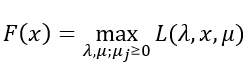
而实际上F(x)可以看做是f(x)的另一种表达形式;由于hi(x)=0,所以拉格朗日函数中的第二项为0;又由于gj(x) ≤ 0且μj ≥ 0,所以μjgj(X) ≤ 0,所以只有μjgj(X) = 0时L取到最大值;因此F(x)在满足约束条件时就是f(x)。由此,目标函数可以表述为如下的形式:
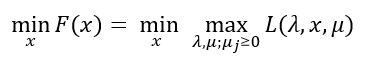
我们称这个式子为原问题。并定义原问题的最优值为P*。
然后再看关于λ和μ的一个式子:
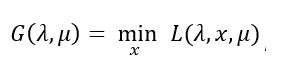
考虑该式子的极大化:
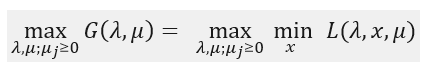
我们称这个式子为原问题的对偶问题。并定义对偶问题的最优值为d*。
(关于拉格朗日的对偶性,可参考李航《统计学习方法》中的附录部分,或者参考博客:http://blog.pluskid.org/?p=702)
关于对偶性问题,通常分为弱对偶性和强对偶性:
(1)考虑到原问题和对偶问题的最优值P*和d*,如果d* ≤ P*,则称“弱对偶性”成立。
(2)如果d* = P*,则称“强对偶性”成立。
通常情况下,强对偶性并不成立;但是当原问题和对偶问题满足以下条件时,则满足强对偶性。
(1)f(x)和gj(x)是凸函数。
(2)hi(x)是仿射函数。
(3)不等式约束gj(x)是严格可行的,即存在x,对所有j有gj(x) < 0 。
以上三个条件也称为Slater条件。如果满足Slater条件,即原问题和对偶问题满足强对偶性,则x*和λ*、μ*分别为原问题和对偶问题的最优解的充要条件是x0和λ0、μ0满足下面的条件:
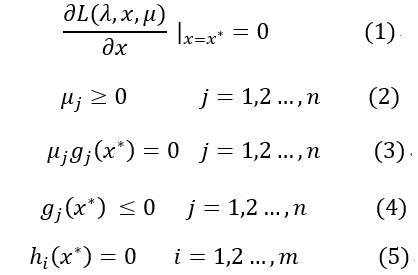
以上五个条件就是所谓的Karush-Kuhn-Tucher(KKT)条件。下面是关于这几个条件的简单阐述:
对于第一个条件,由于原问题和对偶问题满足强对偶性,所以
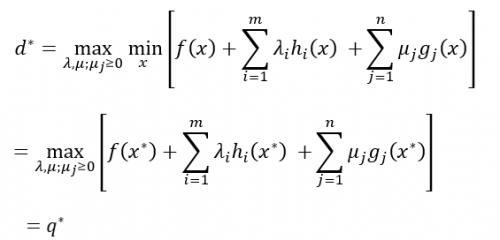
即关于x的函数:
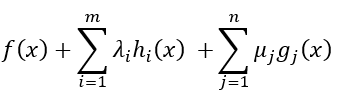
在x*处取到了极值,由费马引理可知,该函数在x*处的偏导数为0,即:
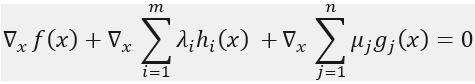
也就是条件(1)。该式子说明f(x)在极值点x*处的梯度是各个hi(x*)和gj(x*)的线性组合。
对于第二个条件,时在定义拉格朗日函数时的约束条件。
对于第三个条件,在定义F(x)时就已经体现了,由于:

因为μjgj(x)≤0,要使得L最大,只有μjgj(x) = 0时满足。所以产生了第三个条件。
对于第四、五个条件,是原问题的自带的约束条件。
当原问题和对偶问题不满足强对偶性时,KKT条件是使一组解成为最优解的必要条件,即在不等式约束下,函数求极值的必要条件。可以把KKT条件看成是拉格朗日乘子法的泛化。



评论